
key 중복 불가

위와 같이, <key, value> 데이터의 연속이므로, 위와 같은 자료 구조를 연관 배열(Associative Array, Map, Dictionary)라
고부를 수가 있다.( 파이썬에서는 Dictionary라는 용어를 쓰는 것 같음)
Map 구현체
1. Hash Table : [배열, 해쉬함수]를 사용하여 Map 구현! ( 일반적으로, 상수 시간으로 데이터에 접근하기에 데이터 접근 속도 빠름)
2. Tree - based : 트리 기반의 Map(대표적으로 [레드 블랙 트리].... 이번 시간에는 Hash Table에 대해 알아 보며, 트리 기반은 레드 블랙 트리 시간에 다시 살펴 볼 것이다)
Map 구현체 - Hash Table
먼저 아래의 것을 까먹지 말고 숙지하고 가자!
Hash Function은 Input값에 대하여, 해쉬값을 반드시 [정수]로 반환을 한다. ( 주로, modular 연산을 사용함 )
Hash Table의 동작 방식( Hash Collision에 대한 예시도 있음 )

Hash값 : 202(정수)
Hash Table의 Capacity가 8이기에 Hash % 8을 통해, 버킷(or Slot)을 정해줌

만약 홍진호의 전화번호와 다른 전화번호, 즉 다른 key값을 가지고 조회를 했더니, 우연히 버킷 2번으로 나왔다면,
우리는 홍진호라는 데이터를 반환해야 하는 걸까?
그건 아니다. 홍진호의 전화번호와 다르기 때문이다.
그럼, 이러한 해쉬 충돌(Hash Collision)을 어떻게 해결해야 할까?
Hash Table에 value뿐 아니라, key와 함게 <key,Value>형태로 저장을 하면 된다.

버킷 2에 들어가서 key 값을 비교해서
key 값이 같으면 홍진호를 반환을 하고, key값이 다르면 반환하지 x. ( 중복을 허락하지 않는 map 성질을 이용! )
Hash Collision이 일어나지 않고, 되도록 bucket이 균등하게 만들어야 한다.
Hash Collision을 일으키는 2가지 상황
1. key는 다른데, hash가 같을 때!
2. key도 hash도 다른데, [hash % capacity]가 똑같을 때!
-> 어찌됐든 같은 bucket/slot 번호가 나오는 경우임!
Hash Collision을 해결하는 큰 2가지 방법( 이 2 가지 방법에 파생된 수많은 방법들이 존재한다 )
1. Open Addressing
2. Separate Chaining
Separate Chaining
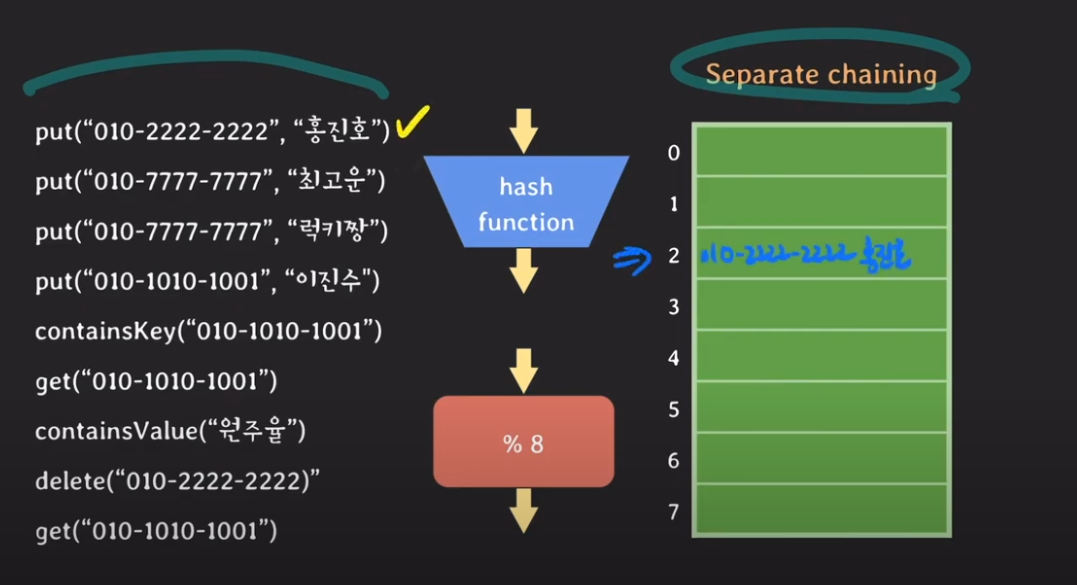

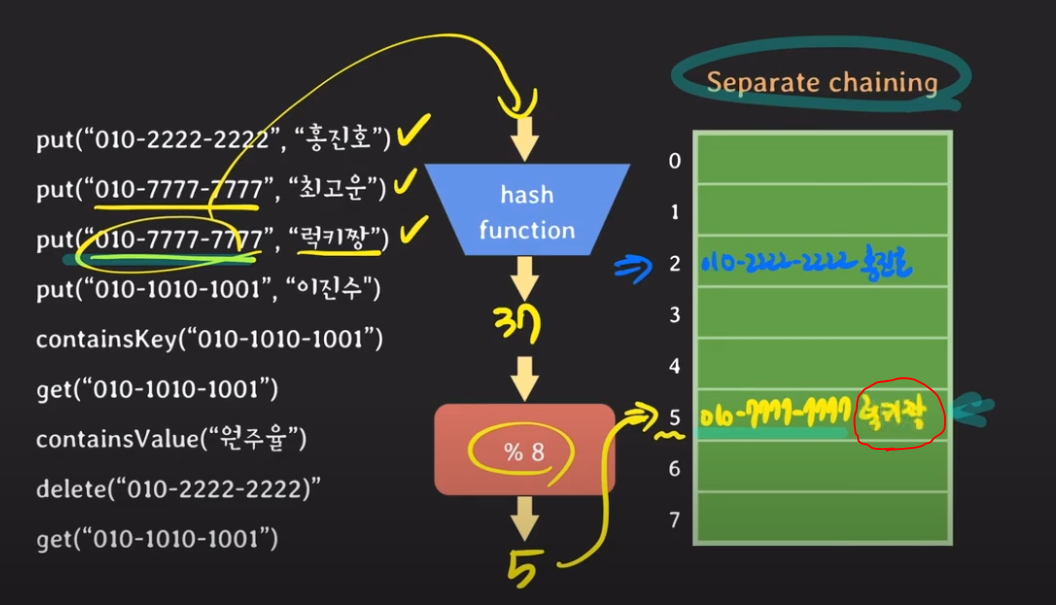
put("010-7777-7777", 럭키짱)의 전화 번호는 최고운과 같다.
당연히, bucket/slot 번호가 같을 것이다.
이때 이미 key값 010-7777-7777이 저장이 돼 있다.
이때, 해쉬 테이블은 해당 버킷에 있는 key값에 대해 equal()을 실행하여, 똑같은 key값이 있는 지를 확인을 한다.
이 경우에는 이미 key값이 미리 존재해 있으므로, 최고운이라는 value값 대신에 럭키짱이라는 value로 데이터를 덮어 버린다.

위 예시가 Separate Chaining의 예시이다.
key값 010-1010-1001의 버킷 번호가 2이다.
그러나, 이미 버킷 2에는 <key,value>가 존재하고 있다.
이때에 노드[010-1010-1001,이진수]를 추가하여 LinkedList으로 데이터를 삽입을 한다.
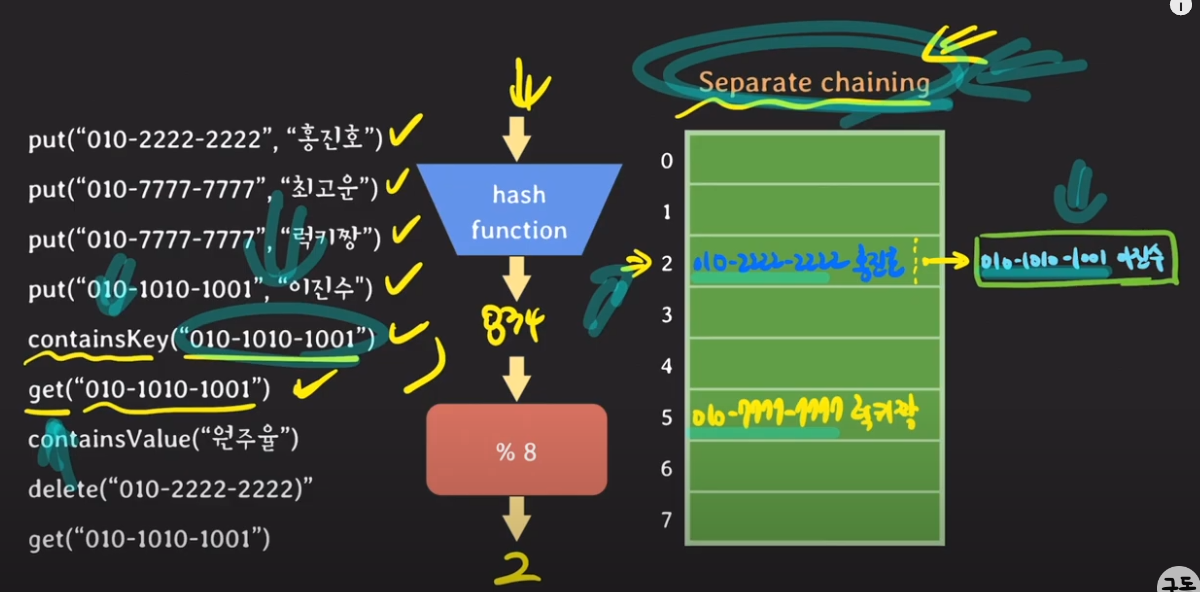
key값 "010-1010-1001"에 해당하는 데이터를 조회할 때에
버킷 2는 LiknedList로 구현이 돼 있으므로, head부터 tail까지 순차 탐색을 한다.

value값을 해쉬 테이블에서 조회하는 것은 버킷 0 ~ 7까지 순차적으로 탐색을 하는 수밖에 없다.
Open Addressing(여기서는 대표적인 linear probing 방식으로 설명을 하겠다 )

여기까지는 위 Separate Chaining과 똑같음

"이진수"를 해쉬 테이블에 넣으려고 하였으나, 해쉬 충돌이 발생을 했다.
Open Addressing 방식의 포인트는 [ 해쉬 충돌 시, 비어 있는 버킷 공간에 데이터를 삽입하자 ]이다
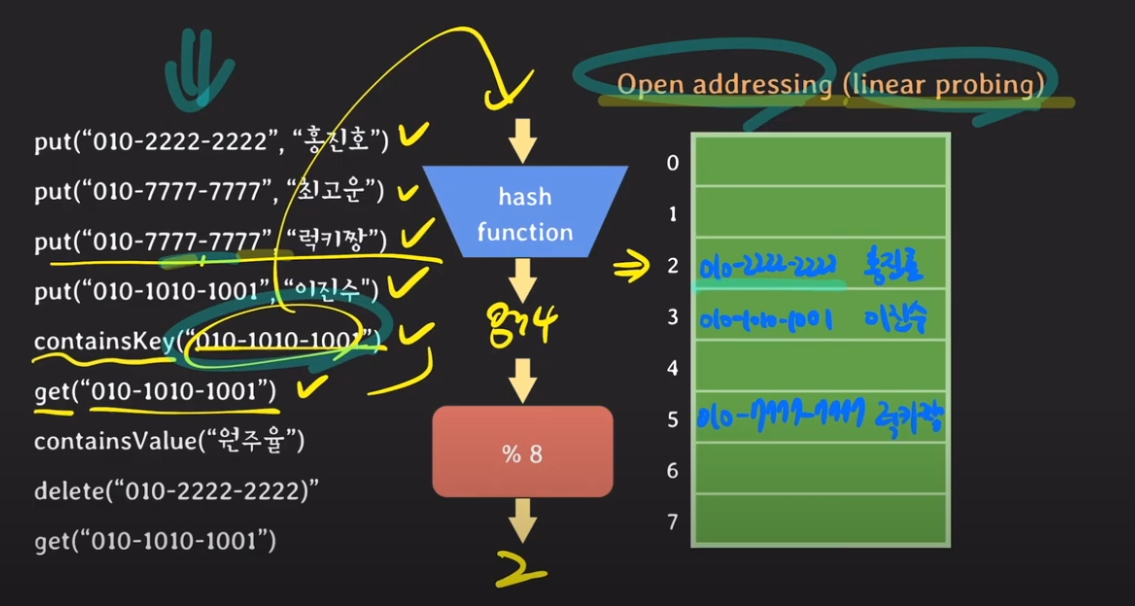
get("010-1010-1001) : 버킷 2에 가서 이미 존재하는 key값에 대해서 equal()을 진행할 것이다.
그러나 key값이 같은 것이 없다.
그러나 Open addressing 방식으로 인해서, 이 key값이 아래의 버킷 중 비어 있는 공간에 저장돼 있을 가능성이 있으므로,
버킷을 아래로 순차적으로 내려가면서 순차 검색을 하는 것이다.
결과적으로 버킷 3에 해당 key값이 존재하였다.

["010-2222-2222",홍진호]를 삭제해 보자
근데, 여기서 단순히 삭제만 하고 끝내면 절대 안 된다.
"이진수"는 원래 버킷 2번에 있어야 했으니 이진수를 원래 버킷 2번에 옮겨 주던지,
아니면 위와 같이 "deleted"와 같은 더미 값을 넣어 줘야 한다.
그 이유는 다음 예시에서 알 수가 있다.

key값 010-1010-1001으로 이진수라는 데이터를 조회하려고 한다.
버킷 2번으로 이동을 하게 될 것이다.
그러나 deleted라는 dumy 값이 있으므로 "아 어떠한 데이터가 원래 버킷2에 있어야 하는데, Open Addressing에 의해서 아
래의 버킷에 존재할 수도 있겠구나라고 하여, 버킷 2 아래의 버킷들을 순차 탐색해 나간다.)
해쉬 충돌 관련 issue : Hash Table resizing
-> 예를 들어 Java에서는 HashMap의 경우, Hash Table의 3/4이상 데이터가 차면, HashTable의 크기를 2배로 늘려서 데이
터를 다시 옮겨 담는다.
이와 같이, Hash Table에 어느 정도 데이터가 차게 되면, Hash Table의 size를 늘려 줘야 한다.
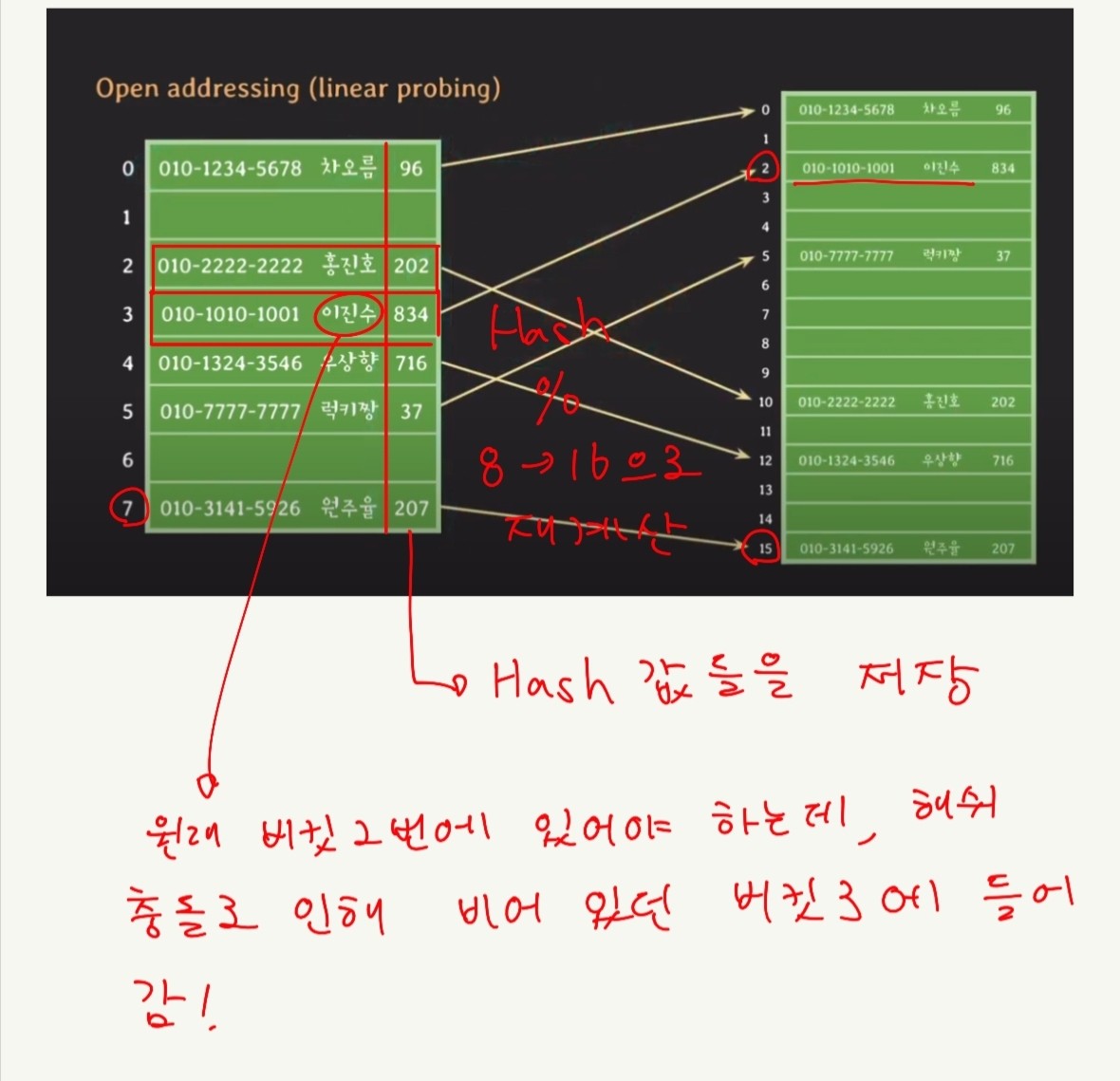
버킷 size를 2배로 늘려 준 덕분에.
본래 버킷2와 해쉬 충돌 이슈로 Open Adderssing 방식으로 인해 버킷3에 들어 가 있던 이진수가
새로운 해쉬 테이블에서는 비어 있는 버킷이 아닌, 해쉬 충돌이 없으므로 정상적으로 버킷에 들어 가게 되었다.
-> 해쉬 충돌을 줄여 주기 위해서는 Hash Table의 resizing이 도움이 된다.

'CS 과목(CS科目) > 자료 구조(Data Structure)' 카테고리의 다른 글
| 동적 배열(Dynamic Array) vs 연관 배열(Associative array) (0) | 2023.03.30 |
|---|---|
| Array List vs Linked List (0) | 2023.03.30 |
| Priority Queue와 Heap의 차이점 (0) | 2023.03.30 |
| DB Index에서 사용되는 B-Tree (데이터 삭제) (0) | 2023.03.10 |
| DB Index에서 사용되는 B tree(데이터 삽입) (0) | 2023.03.10 |


