다차원 배열 선언copy^
포인터와 배열로 2차원[1] 배열을 만들어 보겠습니다.
// using pointer
// dynamic array
#include <stdio.h>
#include <stdlib.h>
int main(void){
int **p;
p = malloc(sizeof(int*) * 10);
for(int i = 0; i<10; ++i){
p[i] = malloc(sizeof(int) * 10);
}
...
for(int i = 0; i<10; ++i){
free(p[i]);
}
free(p);
return 0;
}// using array operator
// static array
#include <stdio.h>
int main(void){
int arr[10][10];
...
return 0;
}확실히 포인터를 사용하는 방식은 다차원 공간의 메모리를 만들기 위해 코드를 더 많이 사용해야 하는 단점이 존재합니다. 이것만 보면 배열이 더 나아 보입니다. 그러나 프로그램이 조금 커지면 오히려 배열이 방해가 될 수 있습니다.
정적 배열의 한계copy^
그 원인 중 첫 번째가 스택 크기의 제한입니다. 1MB 가지고 전체 프로그램의 함수 호출, 명시된 변수들을 사용해야 하는데, 이렇게 배열로 공간을 낭비하게 되면 스택 오버플로우로 프로그램 정상 실행에 문제가 될 수 있습니다. 차원이 한 단계 추가될 때마다 사용하게 되는 메모리는 기하급수적으로 늘어납니다. 차원이 늘어날수록 스택이 불안정해진다 말할 수 있겠죠.
둘째, 사용자로부터 배열의 길이를 마음대로 받을 수 없는 문제가 있습니다. 이 문제는 C99 표준이 발표되며 어느 정도 해소되었으나, 불편을 조금 해소할 수 있는 것뿐이지 완전히 해결되었다고 말할 수는 없습니다.
셋째, 각 배열의 길이를 마음대로 조정할 수 없습니다. 스택에 쌓이는 정적 배열[2]의 경우 이차원 배열에 [4, 5, 3, 5] 개의 요소들이 들어간다고 가정합니다.
int arr[4][5] = {
{1,2,3,4},
{1,2,3,4,5},
{1,2,3},
{1,2,3,4,5}
};이렇게 되면 arr[i]의 인덱스 길이는 초기화된 요소의 수만큼 이 아닌 [5, 5, 5, 5]가 됩니다. 0번, 2번 인덱스가 각각 4, 8Byte의 공간을 낭비하게 되는 것입니다.
넷째로, 요소 값의 교환이 느려질 수 있습니다. 배열은 정적인 것으로서 각 요소를 가리키는 대상의 값은 부동입니다. 그러나 동적 배열의 경우에는 각 하위 배열의 메모리 블록이 다릅니다. 따라서 메모리 블록을 관리하는 상위 블록에서 실제 값을 가지고 있는 메모리 블록 주소를 서로 바꾸어주면 값의 교환을 흉내 낼 수 있으며 오류 없이 제 기능을 수행할 수 있게 됩니다.

관리 메모리(1차 메모리)에서 실제 값을 가지고 있는 2차 메모리 주소의 인덱스 순서를 변경한다
이 내용을 이제부터 코드로 설명합니다.
요소 값 변경하기copy^
이차원 배열이 존재합니다. 우리는 arr[2]와 arr[4]에 들어있는 값을 서로 교환하는 프로그램을 만들 것입니다.
// origin
int arr[10][10] = {
{ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10},
{11, 12, 13, 14, 15, 16, 17, 18, 19, 20},
{21, 22, 23, 24, 25, 26, 27, 28, 29, 30},
{31, 32, 33, 34, 35, 36, 37, 38, 39, 40},
{41, 42, 43, 44, 45, 46, 47, 48, 49, 50},
{51, 52, 53, 54, 55, 56, 57, 58, 59, 60},
{61, 62, 63, 64, 65, 66, 67, 68, 69, 70},
{71, 72, 73, 74, 75, 76, 77, 78, 79, 80},
{81, 82, 83, 84, 85, 86, 87, 88, 89, 90},
{91, 92, 93, 94, 95, 96, 97, 98, 99, 100}
};동적 배열의 값 초기화 하기


위와 같은 공간이 존재한다고 할 때, 정적 배열의 경우에는 2번 배열과 4번 배열의 값을 서로 변경할 때는 반복문을 통해 일일이 교환해주어야 합니다. 코드는 아래와 같습니다.
for(int i = 0 ; i < 10; ++i){
int temp = arr[4][i];
arr[4][i] = arr[2][i];
arr[2][i] = temp;
}
각 요소의 값을 일일이 교환
이 방식은 요소의 수만큼 반복 행위가 늘어나므로 O(n)의 복잡도를 가집니다. 그러나 동적 할당을 사용한 동적 배열은 한 번만 교환해주면 값의 변경이 이루어집니다.
( new 키워드를 쓰지 않아도, vector를 사용하면, 동적 할당이 가능하다. ex) vector<int> a[2] ; // 메모리 교환 가능)


배열을 관리하는 메모리에서 2번 배열 주소와 4번 배열 주소를 교환
int *p = arr[4];
arr[4] = arr[2];
arr[2] = p;이렇게 변경할 수 있는 이유는 포인터를 이용해 다차원 배열을 만들 때의 특성 때문입니다. 정적 배열과 달리 동적 배열은 모든 요소가 하나의 메모리 블록에 집중된 것이 아닙니다. 즉, 여러 개의 메모리 블록을 하나의 포인터로 관리할 수 있도록 각 블록의 시작 주소를 저장하도록 관리 메모리가 하나 더 추가되어 있습니다.

관리 메모리(1차 메모리)에서 실제 값을 가지고 있는 2차 메모리 주소의 인덱스 순서를 변경한다
값을 가지고 있는 메모리에 접근하지 않고, 각 배열을 관리하는 관리용 메모리에 접근합니다. 관리용 메모리 2번 인덱스가 4번 인덱스에 가지고 있는 값은 세 번째 배열과 다섯 번째 배열의 주소입니다. 이 두 값을 서로 교환하면 실제로 요소의 값이 변경되지는 않았지만, 순서가 변경되었기 때문에 교환된 것 같은 효과를 누릴 수 있습니다.
달리 이야기하면 배열 메모리 주소를 교환하고 나면, arr[2]의 요소에 접근할 때는 본래 arr[4]의 요소 값을, arr[4]의 요소에 접근할 때는 본래 arr[2]의 요소 값에 접근하는 것입니다.
코드로 알아보기copy^
실제로 어떻게 변경되는지 코드로 알아봅니다. 바로 아래 코드는 정적 배열을 이용한 경우입니다.
#include <stdio.h>
int main(void){
// origin
int arr[10][10] = {
{ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10},
{11, 12, 13, 14, 15, 16, 17, 18, 19, 20},
{21, 22, 23, 24, 25, 26, 27, 28, 29, 30},
{31, 32, 33, 34, 35, 36, 37, 38, 39, 40},
{41, 42, 43, 44, 45, 46, 47, 48, 49, 50},
{51, 52, 53, 54, 55, 56, 57, 58, 59, 60},
{61, 62, 63, 64, 65, 66, 67, 68, 69, 70},
{71, 72, 73, 74, 75, 76, 77, 78, 79, 80},
{81, 82, 83, 84, 85, 86, 87, 88, 89, 90},
{91, 92, 93, 94, 95, 96, 97, 98, 99, 100}
};
long long address[10][10];
for(int y = 0; y< 10;++y){
for(int x = 0; x< 10; ++x){
address[y][x] = (long long)(arr[y] + x); // &arr[y][x]와 동치
}
}
printf("idx\tidx 2\tidx 4\n");
for(int i = 0 ; i < 10; ++i){
printf("%d\t%d\t%d\n", i, arr[2][i], arr[4][i]);
}
for(int i = 0 ; i< 10; ++i){
int temp = arr[4][i];
arr[4][i] = arr[2][i];
arr[2][i] = temp;
}
printf("\nchange value\n");
printf("idx\tidx 2\tidx 4\tmatch 2\tmatch 4\n");
for(int i = 0 ; i < 10; ++i){
printf("%d\t%d\t%d\t%s\t%s\n", i, arr[2][i], arr[4][i],
arr[2] + i == ddress[2][i] ? "true" : "false",
arr[4] + i == address[4][i] ? "true" : "false"
);
}
return 0;
}결과는 이미지와 같습니다.

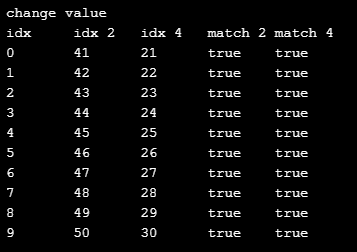
교환 전(왼쪽)과 교환 후(오른쪽)
각 항목 설명은 다음과 같습니다.
| idx | 현재 인덱스 |
| idx 2 | 세 번째 배열의 현재 인덱스에 위치한 값 |
| idx 4 | 다섯 번째 배열의 현재 인덱스에 위치한 값 |
| match 2 | 세 번째 배열의 현재 인덱스 주소 비교(교환 전 저장한 요소 주소 값, 현재 주소 값) |
| match 4 | 다섯 번째 배열의 현재 인덱스 주소 비교(교환 전 저장한 요소 주소 값, 현재 주소 값) |
다음은 동적 배열입니다.
#include <stdio.h>
#include <stdlib.h>
int main(void){
// origin
int **arr = malloc(sizeof(int*) * 10);
for(int i = 0 ; i< 10; ++i){
arr[i] = malloc(sizeof(int) * 10);
}
// 10X10 기준
for(int i = 0 ; i< 10; ++i){
for(int k = 0 ; k < 10; ++k){
arr[i][k] = i * 10 + k + 1;
}
}
long long address[10][10];
for(int y = 0; y< 10;++y){
for(int x = 0; x< 10; ++x){
address[y][x] = (long long)(arr[y] + x); // &arr[y][x]와 동치
}
}
printf("idx\tidx 2\tidx 4\n");
for(int i = 0 ; i < 10; ++i){
printf("%d\t%d\t%d\n", i, arr[2][i], arr[4][i]);
}
int* p = arr[2];
arr[2] = arr[4];
arr[4] = p;
printf("\nchange value\n");
printf("idx\tidx 2\tidx 4\tmatch 2\tmatch 4\n");
for(int i = 0 ; i < 10; ++i){
printf("%d\t%d\t%d\t%s\t%s\n", i, arr[2][i], arr[4][i],
arr[2] + i == address[2][i] ? "true" : "false",
arr[4] + i == address[4][i] ? "true" : "false"
);
free(arr[i]);
}
free(arr);
return 0;
};

변경 전(왼쪽)/후(오른쪽), 정적 배열과 달리 match 결과가 모두 false
동적 배열의 경우 정적 배열과 달리 변경 전/후의 요소 주소가 변경된 것을 알 수 있습니다. 즉, 단 한번 변경했을 뿐이지만 요소 값 변경과 같은 효과를 냈습니다.
Q. 왜 주소를 저장하는 공간의 자료형이 long long인가요?
정적 배열 VS 동적 배열copy^
정적 배열은 편한 문법입니다. 여전히 간단한 프로그램이나 프로토 타입을 개발할 때는 저도 애용하고 있습니다. 그러나 정적 배열은 포인터로 만든 동적 배열보다 한계가 많습니다. 프로그래머의 능력이 되더라도 문법 자체가 가지고 있는 한계이기 때문입니다.
정적 배열이 나쁘고 동적 배열이 좋다는 것을 말하고 싶은 것이 아닙니다. 그저 때에 맞추어 더 나은 선택을 하길 바라는 마음입니다.
정적 배열과 동적 배열의 장단점은 아래와 같습니다.
정적 배열 장단점copy^
장점
- 문법이 쉽다
- 메모리 누수를 걱정하지 않아도 된다.
단점
- 메모리 크기가 고정되어있다
- 최대 메모리 크기에 제약이 있다.
동적 배열 장단점copy^
장점
- 원하는 크기를 할당할 수 있어 공간 효율적이다.
단점
- 명시적으로 해제하지 않으면 메모리 누수 현상이 발생한다.
- 생성 시 오버헤드[3]가 발생한다.
'알고리즘(アルゴリズム) > 알고리즘 이모저모(アルゴリズムの緒論)' 카테고리의 다른 글
| 점화식은 행렬의 거듭 제곱을 이용해서, DP 보다 빠르게 구할 수가 있다 (0) | 2023.01.31 |
|---|---|
| 행렬의 거듭 제곱( feat. 단위 행렬) (2) | 2023.01.31 |
| 백준 11401번 ( 합동식 ) (0) | 2023.01.29 |
| pre-condition을 고려하며 function 작성하자!!!! (0) | 2023.01.28 |
| 합동식(modular)을 왜 쓰는 걸까??? (0) | 2023.01.28 |
