SELECT with SubQuery
SubQuery를 이용하면, 좀 더 정밀하고,세세한 조건의 SQL문을 작성 가능하다.

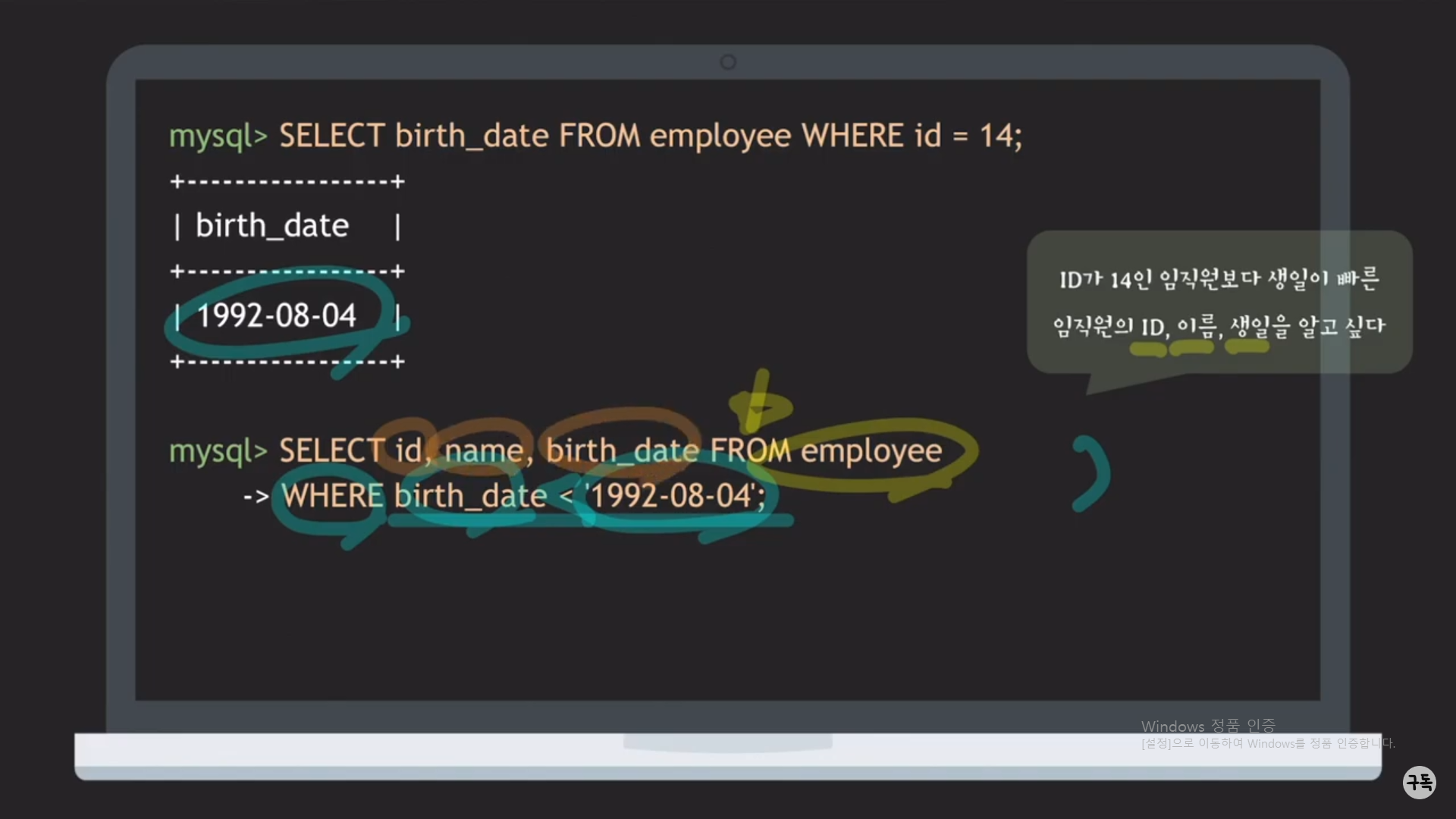
위 그림의 2개의 SQL문을 이용하여 예제를 풀 수가 있다.
Q. SQL문을 2개나 쓰는 것은 뭔가 귀찮다. 2개의 SQL문을 1개의 SQL문으로는 바꿀 수가 없을까?
A. 쌉가능.(아래 그림 참조)
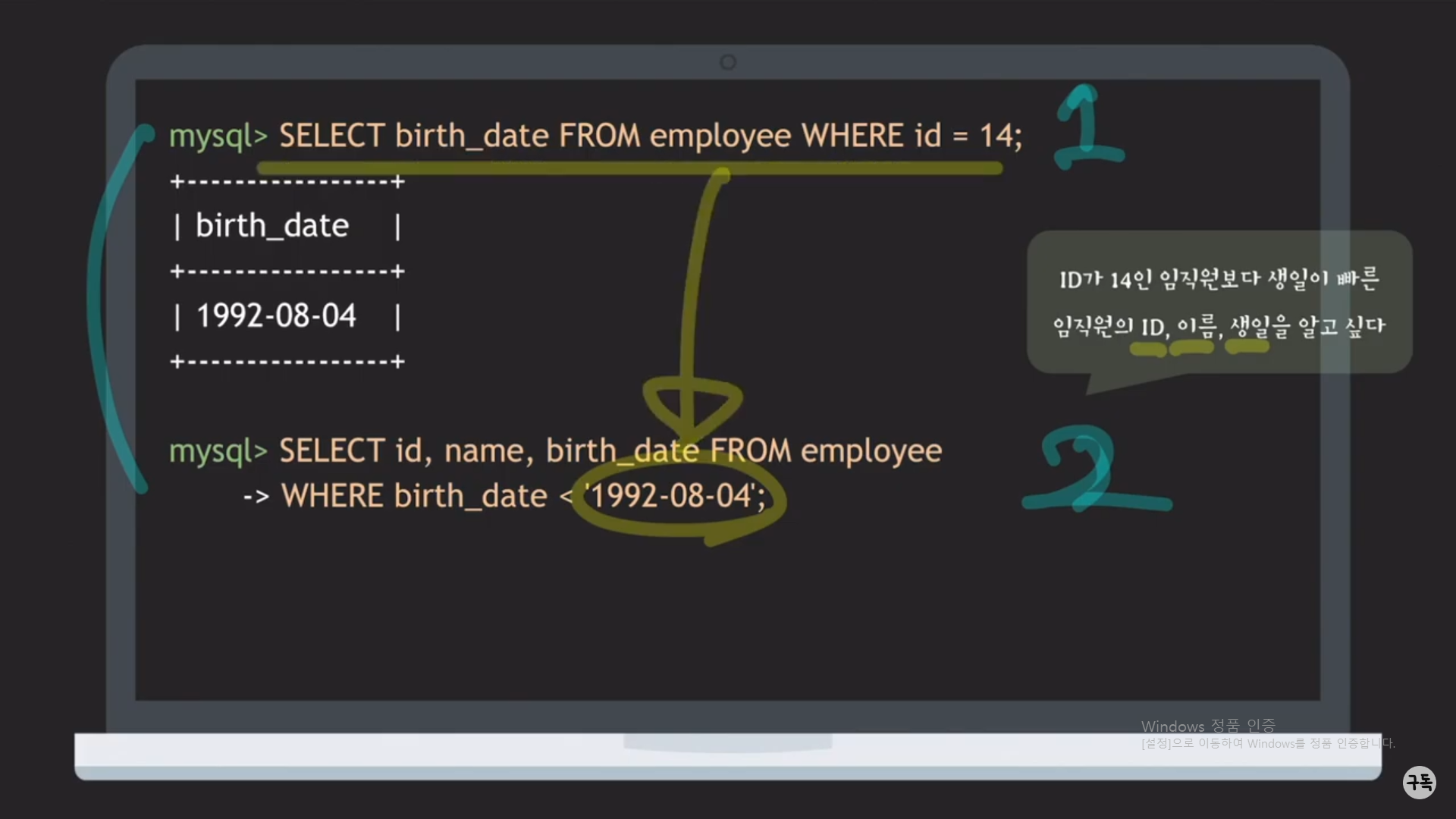
2번째 Query문에서의 ' 1992 - 08 - 04 '는 1번째 Query문의 결과이다.
'1992-08-04' 부분을 1번째 Query문으로 치환을 시키면, 아래의 그림과 같이 1개의 SQL문이 만들어 진다.
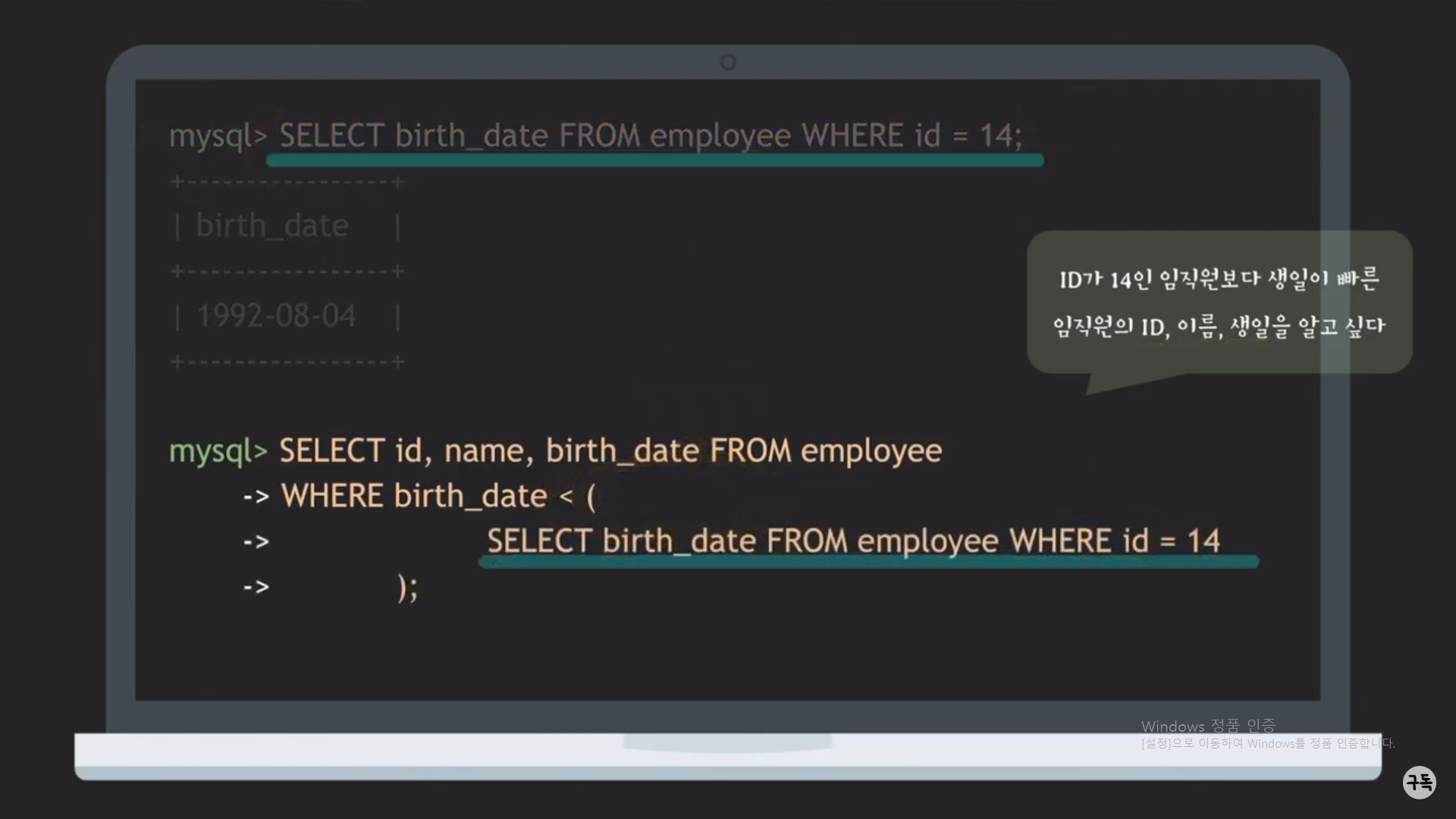
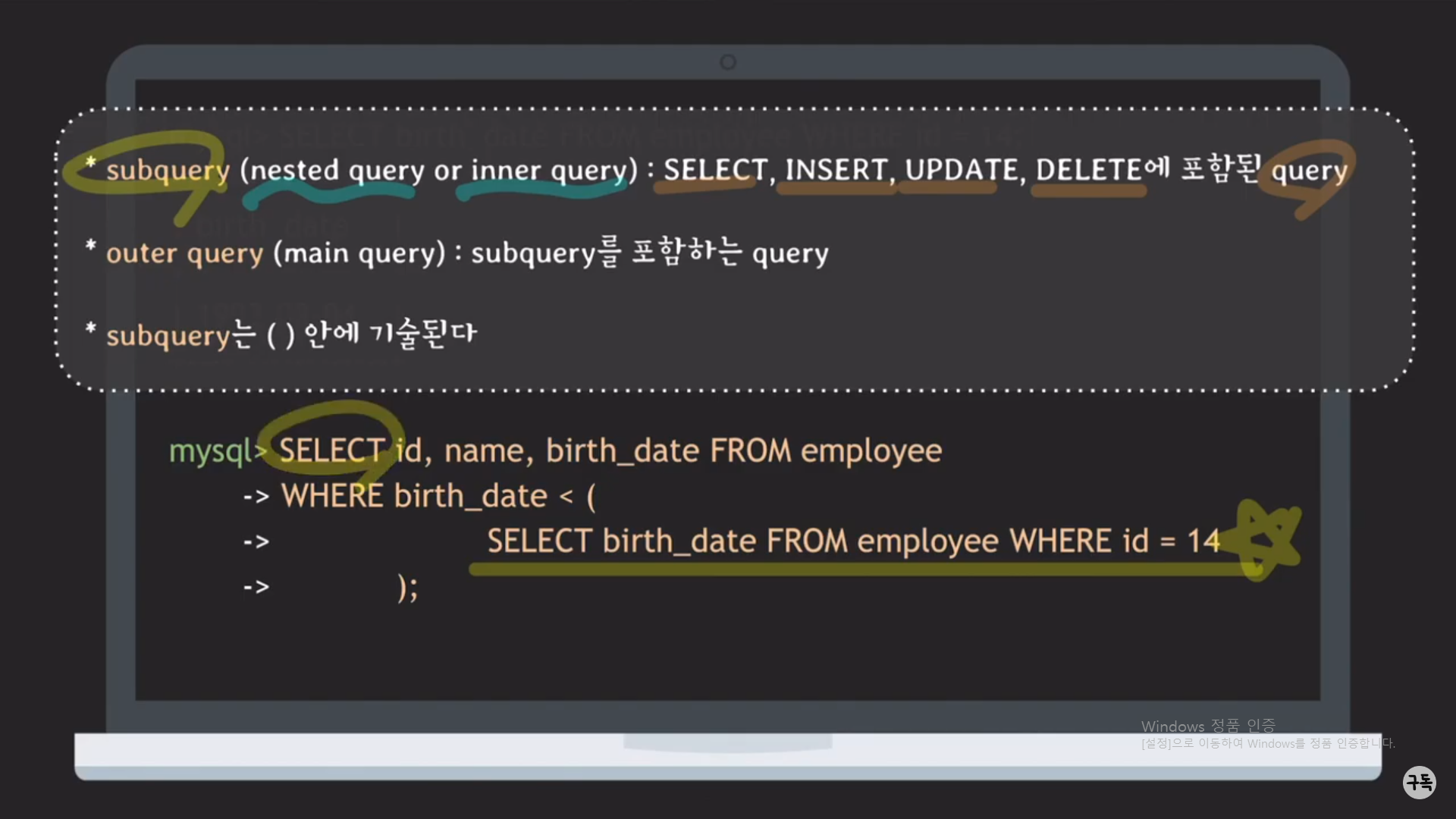
subquery
"SELECT birth_date from employee where id = 14" : SELECT문에 포함된 또 다른 Query문(약간, 재귀 함수 같은 느낌)
outer query(main query)
SELECT id, name, brith_date from employee WHERE birth_date : subquery는 이 query안에 포함되는 것이다.
-> subquery는 반드시 ( ) 괄호 안에 작성을 해야 한다.
suquery는 1개 이상의 attribute를 반환할 수가 있다. 아래의 예제에서 살펴 보자.




(select works_on.empl_id from works_on
where proj_id = (select proj_id from works_on where empl_id=1) : SQL문의 정답은 꼭 1개가 아니다. 여러 형태로 똑같은 결과값을 낼 수가 있다. 이 SQL문을 실행해도 예제를 풀 수가 있다.
(proj_id = 2001 OR proj_id = 2002) : proj_id가 2번 중복이 된다. 이거를 1번만 적을 순 없을까?(아래 참조)
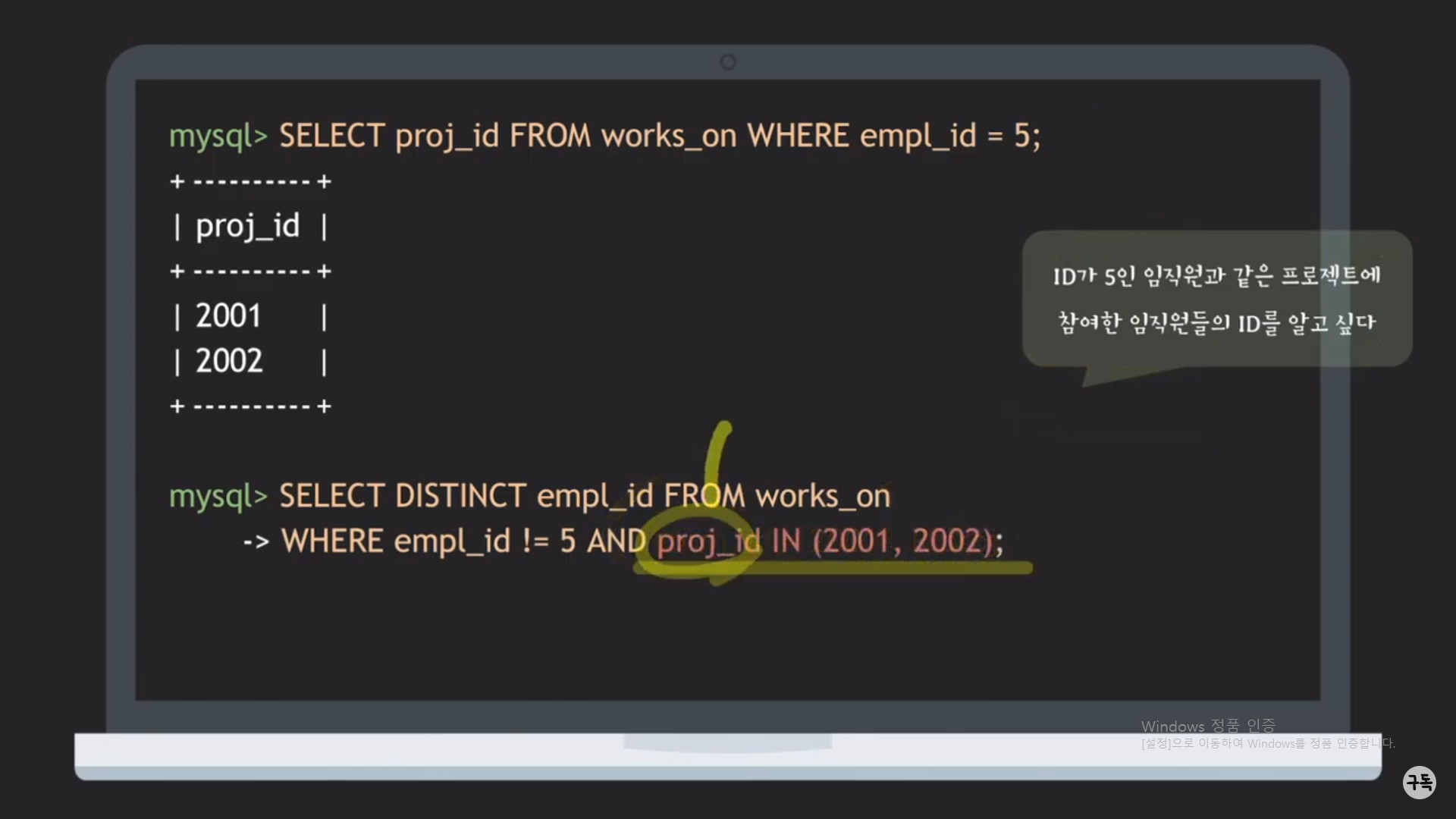
proj_id IN (2001,2002) == (proj_id = 2001 OR proj_id = 2002)
proj_id IN (2001,2002)는 첫번째 SELECT문의 반환값으므로, 아래와 같이 1개의 SQL문으로 합칠 수가 있다.
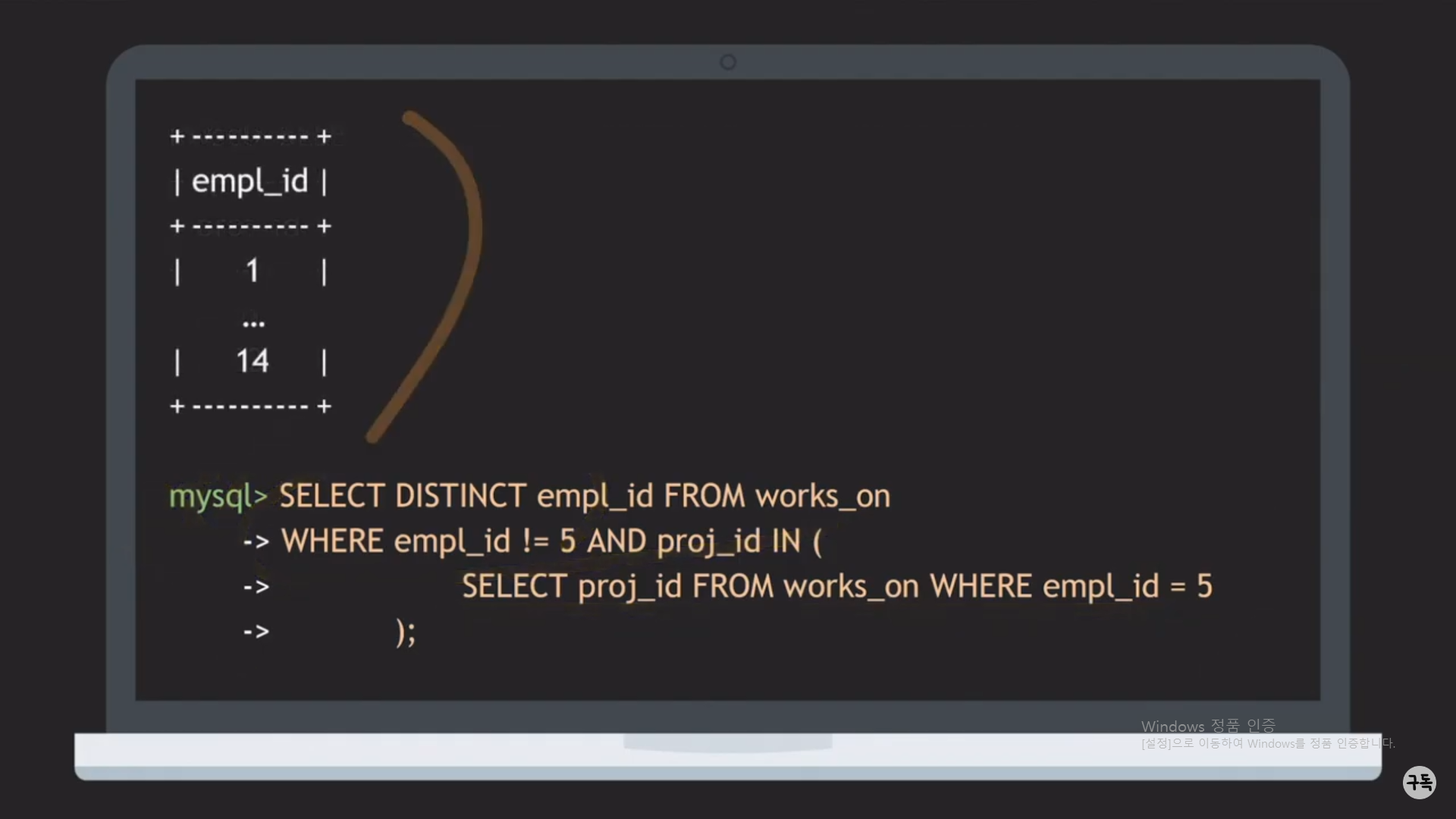


Unqualified Attribute : SELECT name from employee에서 name은 어떤 table의 name인지 명시를 하지 않았다.
이러한 attribute를 Unqualifed Attribute라고 부른다.
그럼 어떤 방법으로 table을 확정 짓을까??
해당 attribute 이름을 가지는 가장 가까이에 있는 table로 확정시킨다.
예를 들어 outer query의 2개의 empl_id와 proj_id는 works_on table을 참조한다.
subquery의 proj_id, empli_id는 subquery의 명시된 table, 즉 works_on table을 참조한다.
Q. 우리는 최종적으로 임직원의 ID를 알아내는 SQL문을 만들어 냈다. 여기서 추가적으로 그 ID에 해당하는 임직원의 이름을 알고 싶다면 SQL문이 어떻게 돼야 할까?
A. 아래의 그림 참조

위에서 많은 예제와 함께 IN을 배워 왔다.
그런데 IN은 항상 WHERE 뒤에 존재하였다.
IN은 사실 WHERE뿐만이 아니라, FROM절의 뒤로 와서 가상의 TABLE의 형태로 이용될 수가 있다.
(SELECT문의 결과값은은 Table의 형태를 띈다.)
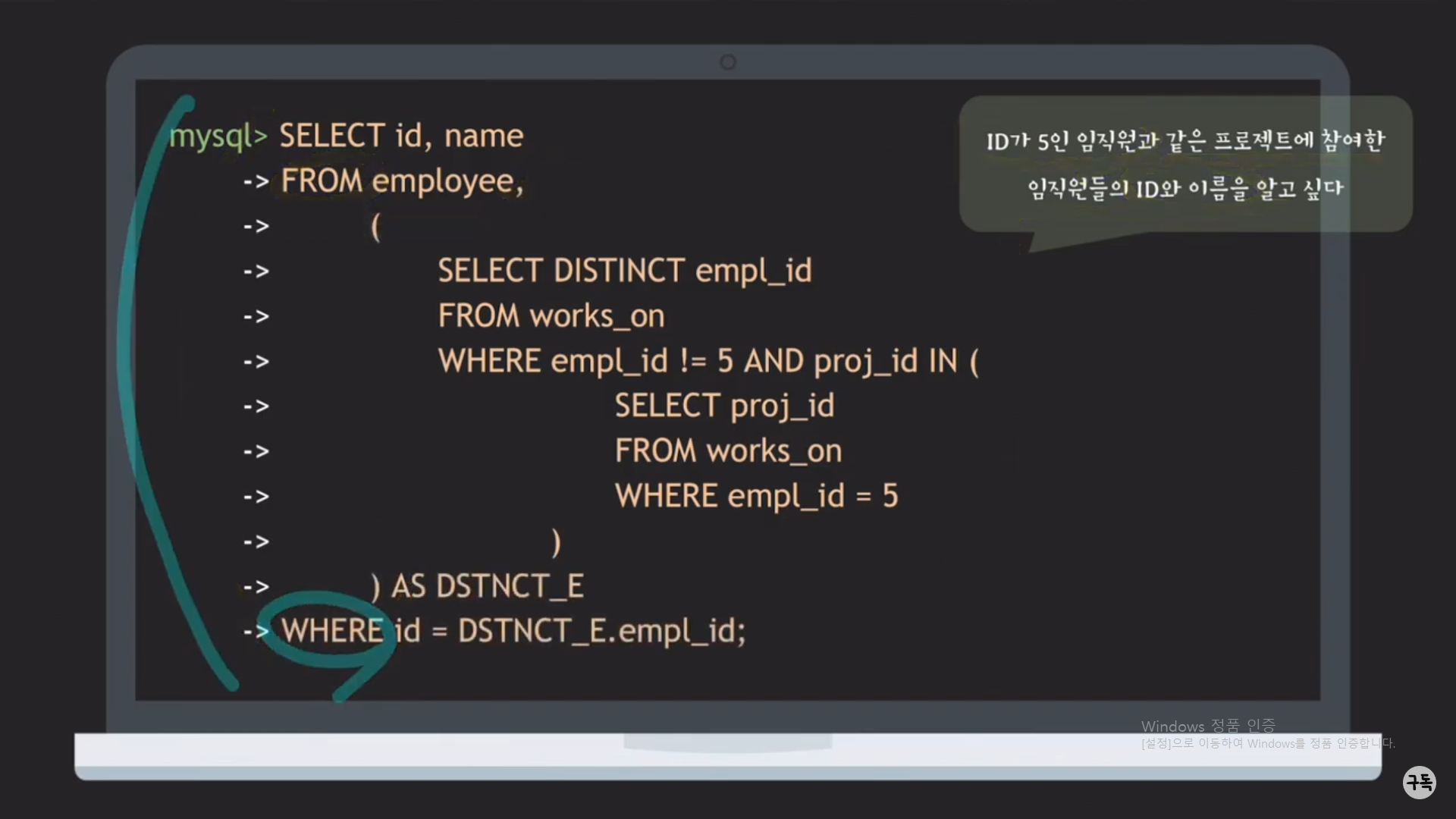
WHERE id = DSTINCT_E.empl_id;에 의해서 employee table과 works_on table이 연결이 된다.

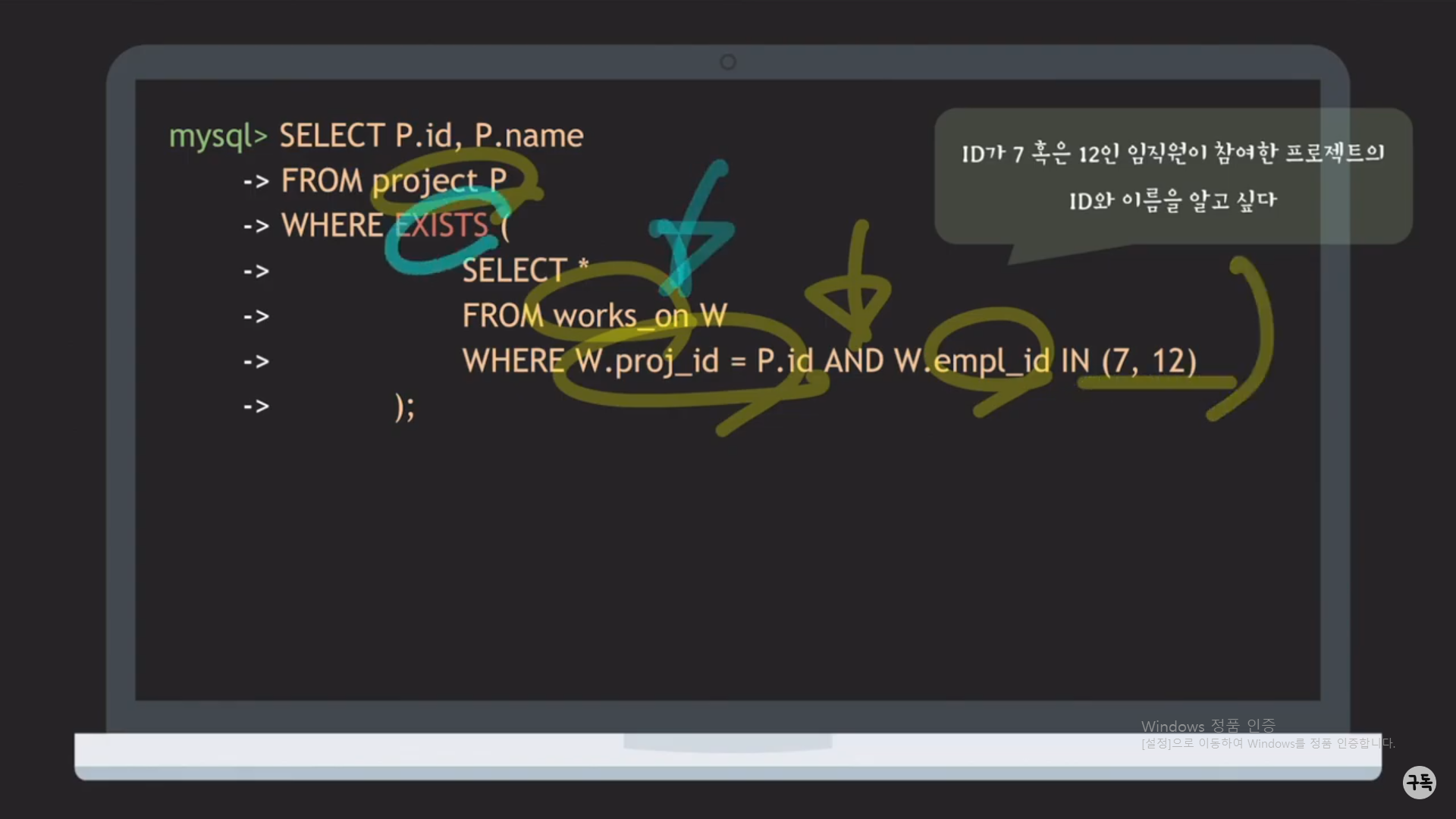
EXIST 키워드가 들어간 Query문은 약간의 해석에 요령이 필요하다.
a) 우선 Outer Query 부분을 먼저 해석한다.
b) project 테이블에서(FROM projcet) 모든 tuple들을 하나하나 탐색하여 아래의 조건을 만족하는 tuple을 찾는다.
c) project의 id가 works_on에도 있고 work_on.id가 7 혹은 12를 만족하는 works_on table의 tuple이 1개라도 존재(EXIST)
한다면 true를 반환하고, 그 project의 tuple들은 선택이 된다.

correlated query : subquery의 P.id는 outer query의 attribute 즉 Project table의 query를 참조하므로, 해당 subquery를
correlated subquery라고 부른다.
IN 키워드와 EXIST 키워드는 서로 치환이 가능하다. (아래 참조)
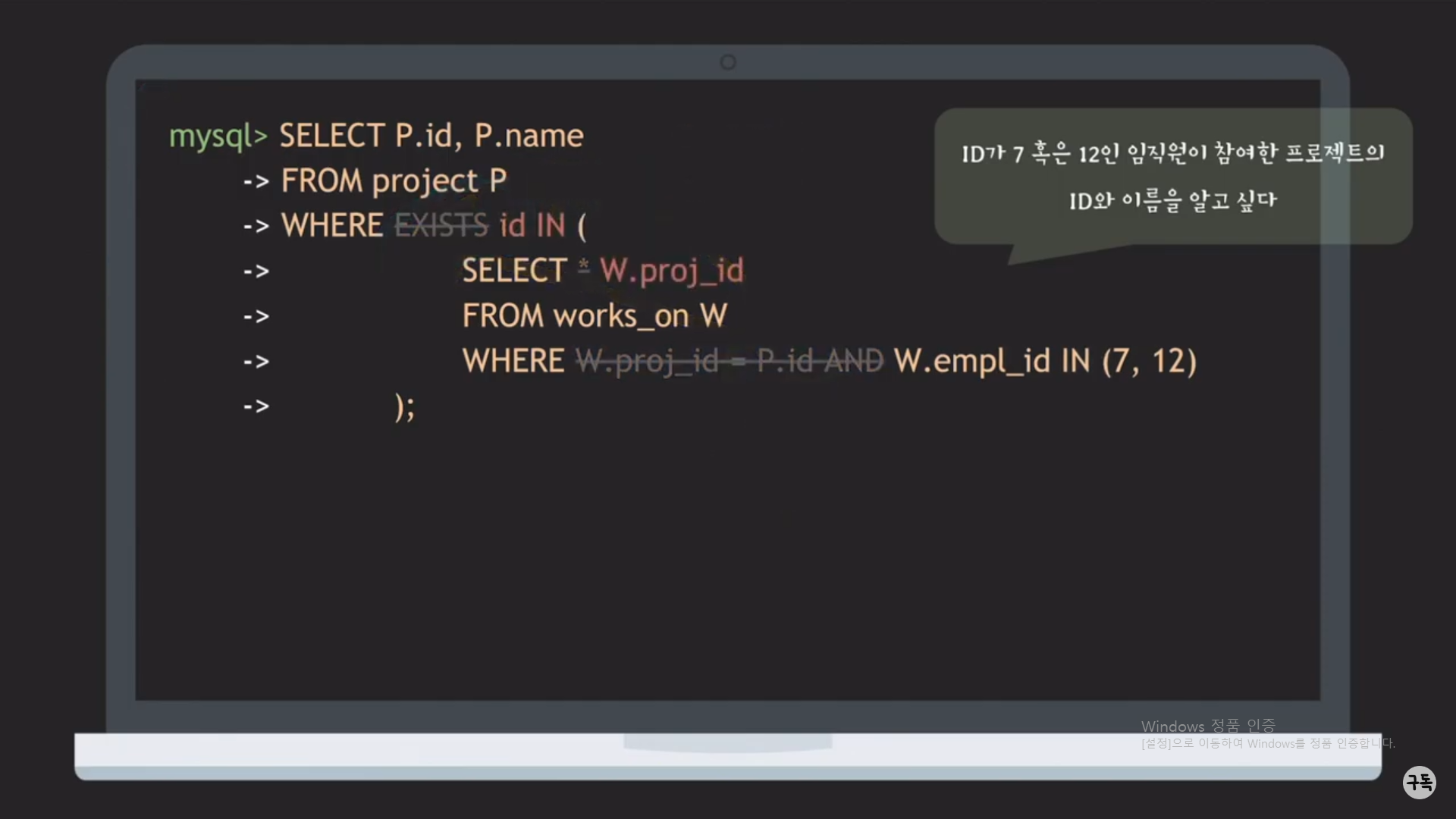
1. SubQuery의 atttribute 중 outer Query의 attribute(P.id)를 outer로 뺀다.
2. EXIST를 IN으로 바꾸어 준다.
3. (1,2)를 실행하면, P.id IN (....)의 형태를 가지게 된다. 근데 IN뒤의 ()괄호 안에 들어 가는 것은 P.id에 상응하는 어떠한 값
이다. 고로, 여기서는 그 값이 works_on.proj_id이므로, asterisk 부분을 proj_id로 바꾸어 준다.


NOT EXISTS과 NOT IN도 서로 치환이 가능하다. (요령은 위와 똑같다)



ANY : ()괄호 안의 SubQuery의 결과값 중, 단 1개라도 E.Salary(리더의 연봉)보다 작은 것이 있다면 true를 반환하여,
D.leader_id = E.id라는 join condition에 의해 서로 연결이 된 해당 tuple이 선택이 된다.


만약, 예제에서 구한 [리더의 ID와 연봉]을 바탕으로, 해당 부서의 최고 연봉을 알 수는 없을까???
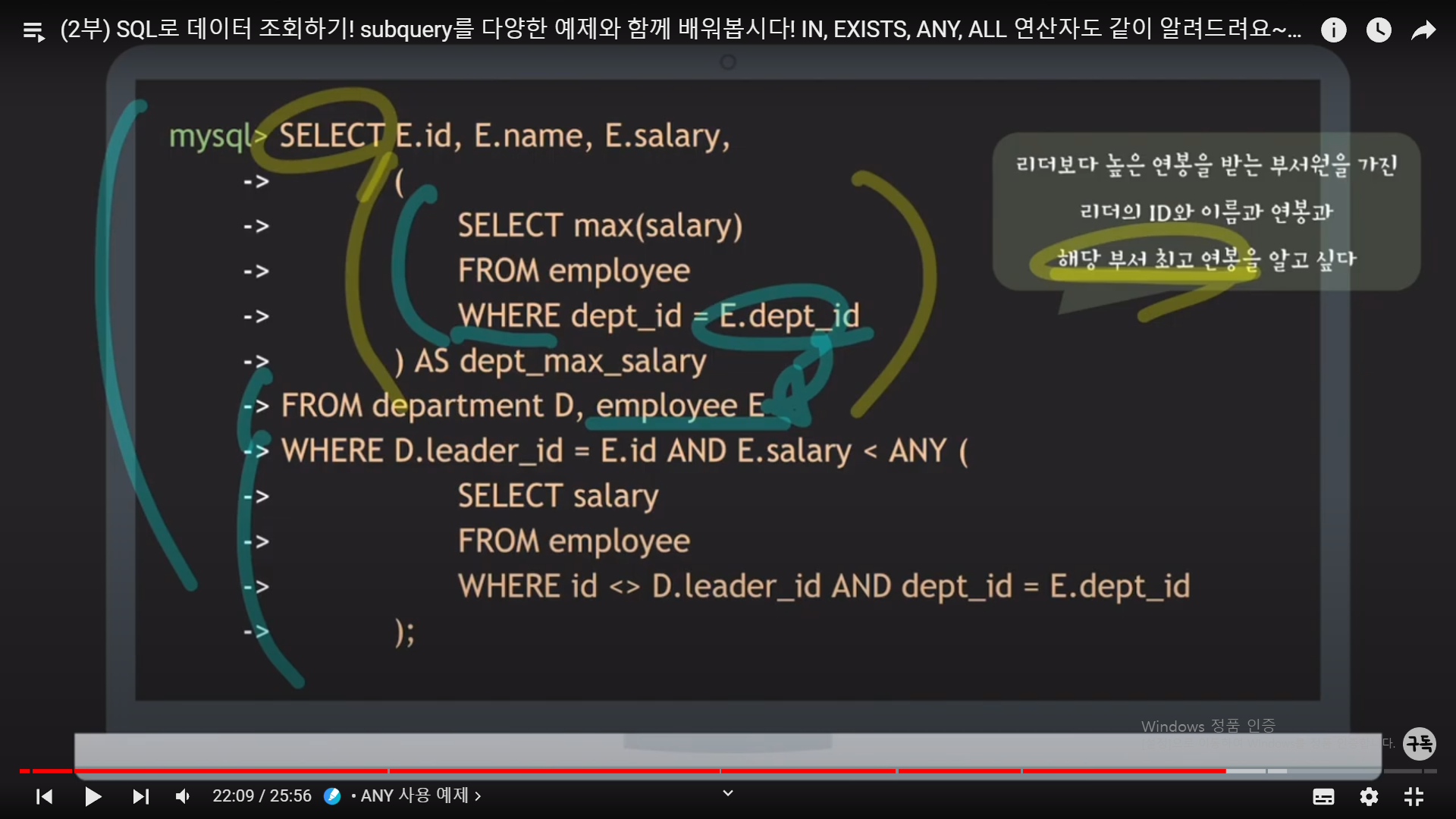
1번째 SubQuery의 "E.dept_id"는 outer query의 결과값이므로, 리더의 id를 의미한다.




뭔가 subQuery가 들어 가 있을 때에는, outer query를 먼저 해석하는 게 더 해석이 쉬운 것 같기도 하다.
'CS 과목(CS科目) > 데이터 베이스(データベース)' 카테고리의 다른 글
| 8.SQL로 데이터 조회하기(SQLでデーター照会)PART 4 (0) | 2022.12.08 |
|---|---|
| 7. SQL로 데이터 조회하기(SQLでデーター照会)PART 3 (0) | 2022.12.08 |
| 5. SQL로 데이터 조회하기(SQLでデーターを照会しょう)part 1 (0) | 2022.12.08 |
| 4. SQL로 DB에 데이터를 추가(insert)하고 수정(update)하고 삭제(delete)하는 방법(SQLでDBへデーターを挿入(insert)/修正(update)/削除(delete)する方法) (0) | 2022.12.08 |
| 3. SQL의 개념과 SQL로 데이터베이스를 정의(SQLの概念とSQLでDBを作ろう) (0) | 2022.12.07 |



