데이터 추가
INSERT INTO [테이블 명] VALUES( ...) : VALUES 안에 Attribute값을 넣어 준다. 그리고 table을 정의했을 때의 Attribute 순서대로 넣어 주면 된다. 이때 모든 Attribute에 대한 값을 다 넣어 줘야 한다. ( 모든 Attribute값을 안 넣어 줘도 되게 하는 방법이 아래쪽에 나와 있음)


위 명령어를 실행을 하면 정상적으로 작동을 할까??
-> Nope!!! "111"이라는 dept_id Attribute는 DEPARTMENT Table의 값을 참조하고 있는데, 위 시점에서는 아직
DEPARTMENT Table에는 어떠한 id값도 넣어 지지 않았기 때문에, DEPARTMENT Table의 id Attribute에 없는 값(111)을
참조하게 되버린다.
foreign key는 참조하고 있는 table에 없는 값을 참조해서는 안 된다.(foreign constraints)
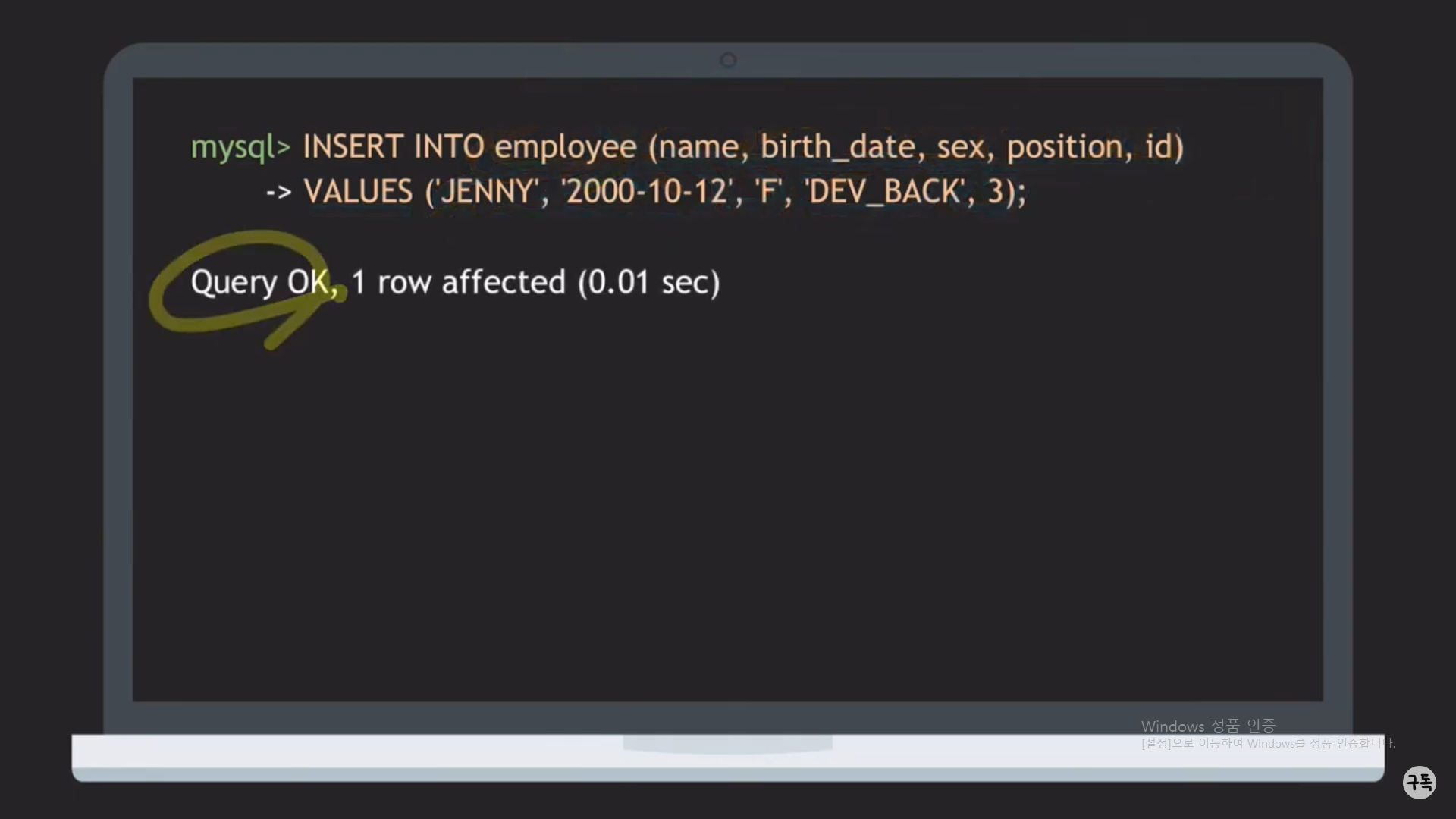
INSERT INTO [테이블 명] ( Attribute1, Attribute2, ... ) VALUES(Attribute1, Attribute2, ...)
-> 위 그림을 보면, (name,birth_date,sex,position,id)가 있다. 서두에서 insert 시에, 모든 Attribute값을 순서대로 넣어 줘야
한다고 언급을 하였는데, 위와 같은 문법으로 정의를 하게 되면, Attribute 중에서도 추가하고 싶은 Attribute값만 넣을 수 있
고, 추가 순서도 임의로 변경이 가능하다.

SELECT * FROM[테이블 명] : 해당 테이블의 모든 TUPLE들을 보여 준다.

INSERT INTO [테이블명] VALUES (.....), (......), (.....) ... , (....)
-> (....)에 Attribute값들을 넣어서 한 번에 여러 tuple들을 삽입하고 싶을 때 사용
ex) insert into employee values( 1,'alice', 'M'), (2,'John','F'); // 2개의 TUPLE을 한 번에 삽입을 했다.
위 SQL문을 사용하여 company DB에 정의한 4개의 테이블에 TUPLE들을 저장을 하였다. 그러나 아직 완전히 끝나지 X.

employee table에 tuple을 추가했던 시점에는 department table에는 아무런 값도 없었기 대문에 위 그림과 같이 dept_id를
NULL 처리를 해주었다. 그러나 이제는 department table에 tuple들이 들어가 있기 때문에, dept_id 부분을 UPDATE해줘야
한다.
데이터 갱신

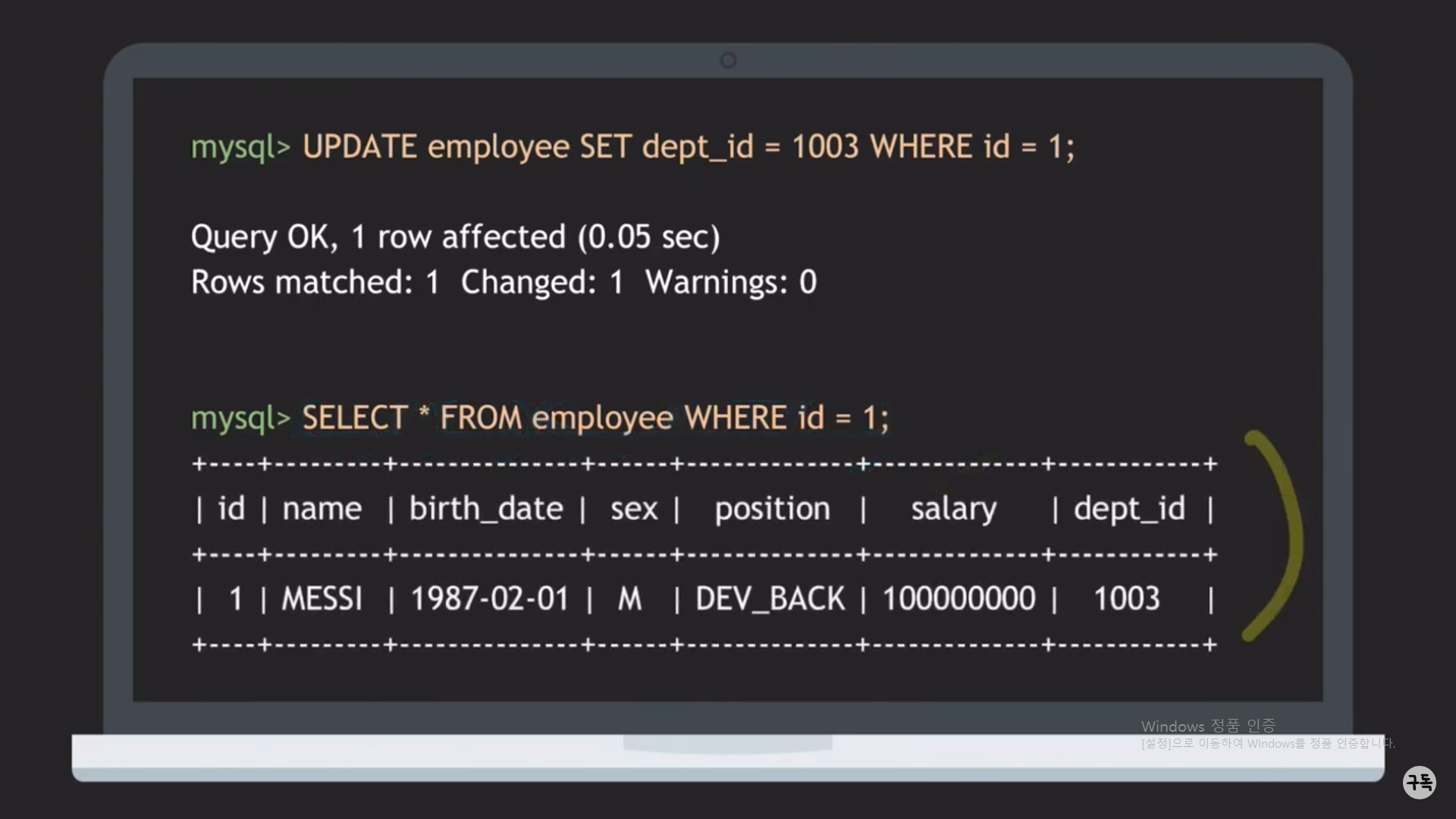
이제는 개발팀id 1003인 사람들의 연봉을 2배로 올려줘 보자.

SQL문 : UPDATE employee SET salary = salary * 2 where dept_id = 1003;
-> select * from employee where dept_id = 1003;을 통해 확인을 해 보자!!!
다음으로는 project_id 2003에 참가한 직원들의 연봉(salary)을 2배로 올려보자.

1. 먼저 Works_On 테이블에서 project 2003에 참여한 직원이 누구인지를 파악을 해야 한다.
2. 직원을 파악한 뒤(직원의 id를 파악한 뒤), 그 직원의 연봉(salary) Attribute가 있는 employee 테이블에서 연봉(salary)를
2배로 올려야 한다.

조건절에 해당하는 WHERE id = empl_id and proj_id = 2003 을 분석해보자.
id는 employe::id이며, empl_id는 works_on::emply_id이다. 즉 employee의 id와 works_on의 id가 일치하면서 그 id에 해당
하는 employee가 project 2003을 맡고 있는 경우라는 뜻이다.
이 중에서도 id = empl_id가 employee 테이블과 works_on 테이블을 연결시켜 주는 역할을 하고 있다.
(id,empl_id가 각각 어느 테이블에 소속된 attribute인지가 헷갈린다. 그래도 employe.id, works_on.empl_id 처럼 앞에 테
이블 명을 적어 줄 수도 있다.)

SET 뒤에 2개 이상의 attribute값을 세팅 가능하다.
데이터 삭제

John에 대한 정보는 employee 테이블과, works_on 테이블에 있다.

DELETE FROM EMPLOYEE WHERE id = 8을 실행을 시키면 employee 테이블에서 JOHN에 해당하는 TUPLE이 삭제가
된다.
Q. employee에서의 삭제는 완료가 되었다. 그럼 word_on 테이블의 {8,2001} 부분도 delete문으로 삭제 처리를 해줘야 할까?
A. Nope!!! (아래 참조)

위 그림에서 보면 Schema를 정의할 때, works_on.empl_id를 foreign key로 설정하고 employee.id를 참조하도록 하였다.
그리고는 reference option으로 "on delete CASCADE"를 해주었다.
CASCADE는 참조값이 삭제가 되면, 그 참조값에 해당하는 works_on의 tuple을 삭제하는 것이다.
고로, DELETE FROM EMPLOYEE WHERE id = 8를 실행시키면 자동으로 works_on의 {8,2003} tuple은 삭제가 된다.



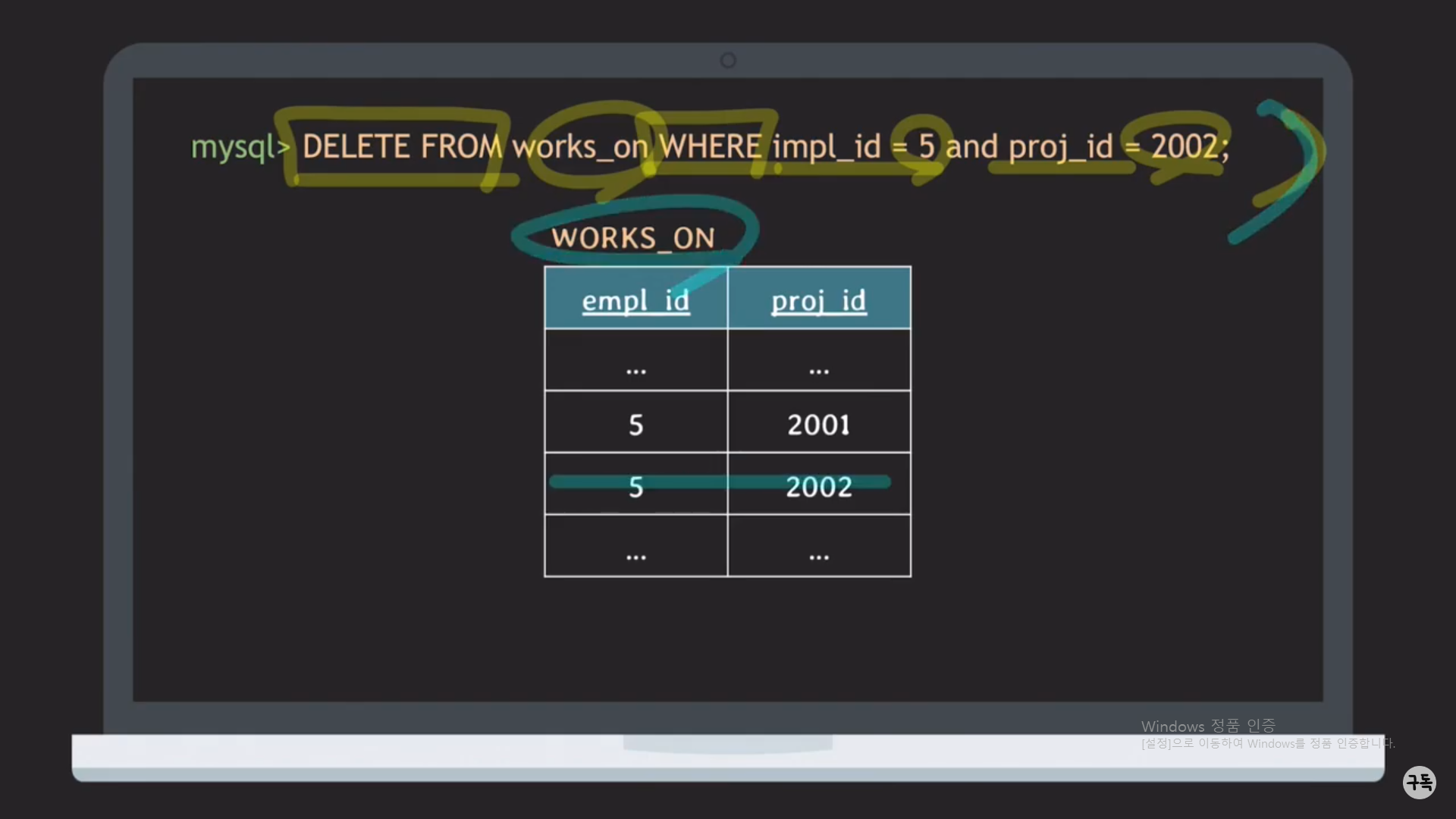
Q. 만약에 id=5인 직원(employee)가 2001 프로젝트 뿐 아니라, 예를 들어, 2003, 2004 프로젝트가 동시에 맡고 있었다면 어떻게 해야 하나?? 일단 분명한 건 위 SQL문으로는 처리가 안 될 것이다.
A. delete from works_on where empl_id = 5 and proj_id <> 2001 을 실행!!
-> <>의 뜻이 "~을 제외한"이라는 뜻이며, 즉 empl_id가 5인 튜플 중에서 2001 프로젝트를 제외한 나머지 튜플을 모두 삭제
해라는 뜻이다.(참고로 <> 대신에 != 을 사용해도 된다.)


'CS 과목(CS科目) > 데이터 베이스(データベース)' 카테고리의 다른 글
| 6. SQL로 데이터 조회하기(SQLでデーターを照会)PART 2 (0) | 2022.12.08 |
|---|---|
| 5. SQL로 데이터 조회하기(SQLでデーターを照会しょう)part 1 (0) | 2022.12.08 |
| 3. SQL의 개념과 SQL로 데이터베이스를 정의(SQLの概念とSQLでDBを作ろう) (0) | 2022.12.07 |
| 2. 관계형 데이터베이스(relational database)개념과 relation, primary key(기본키), foreign key(외래키), constraints (0) | 2022.12.07 |
| 1.데이터 베이스의 기본 개념(データベースの基本的な概念) (0) | 2022.12.06 |



