
DB에서 말하는 "Relation", 즉 "관계"는 수학에서 나오는 "관계"이다. 고로, 먼저 수학에서의 "관계"가 무엇인지를 알아야 한
다.
그에 앞서 먼저 set이란 무엇인지를 알고 가자.

참고로, set과 list의 차이점에 대해서도 알아 놓자. 차이점은 단 한가지, "순서"에 있다.
set은 element들의 순서가 고려돼 있지 않다.
그러나 list들은 element들의 순서가 고려돼 있다. (아래의 관계 부분은 list개념이다.)

A X B ={ {1->p} ,{2->q}, {3->r} ..... {2->r} }, 총 6개의 list로 구성이 돼 있다.( Tuple : 1개의 list가 n개의 element로 구성이
돼 있을 때, 그 list를 n-tuple이라고 한다.)
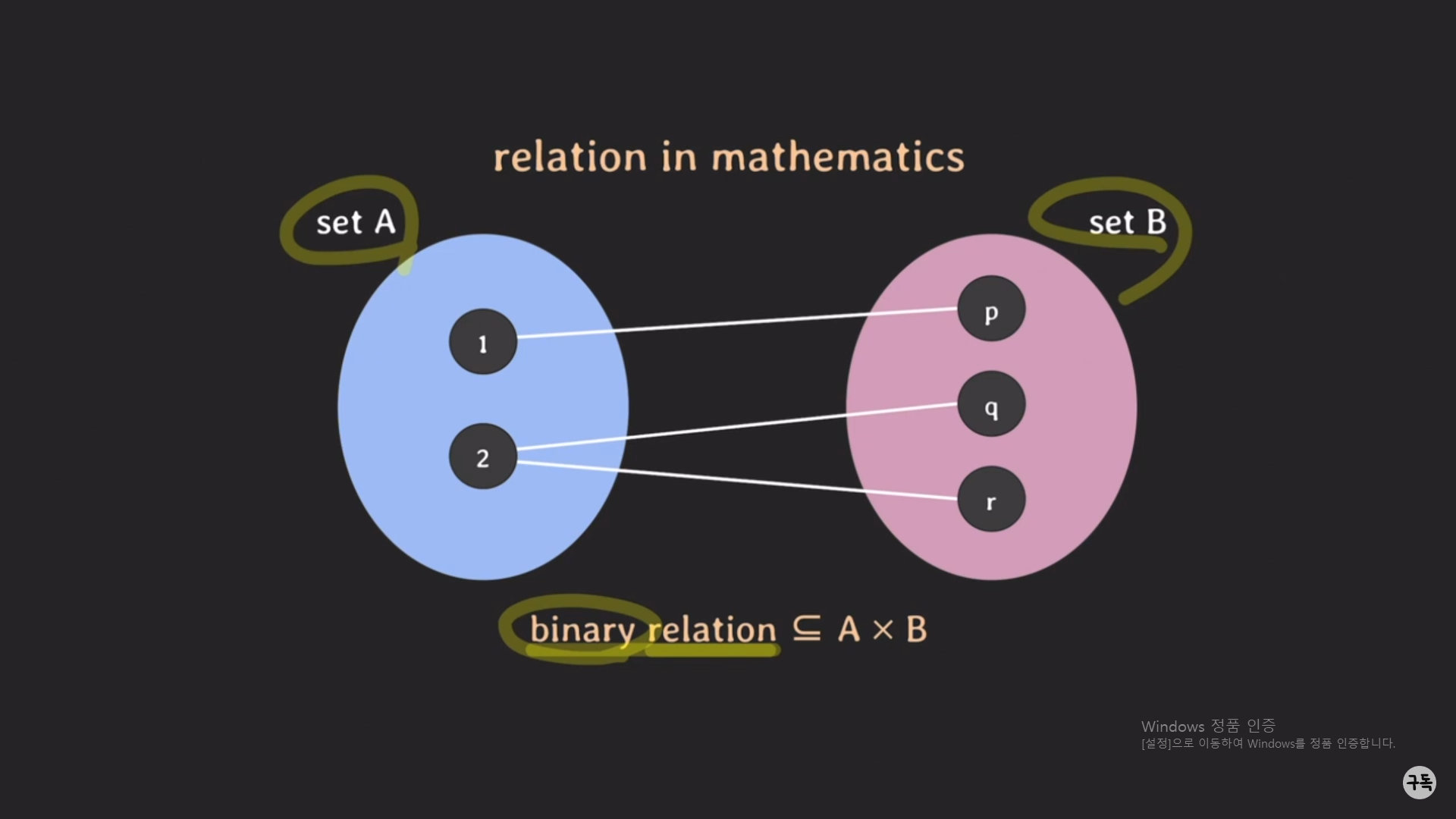
위 그림과 같이 Set이 각각 1개씩 있다고 가정해 보자.
Catesian Product( A X B )에 대한 Binary Relation, 즉 A X B의 부분 집합을 Binary Relation이라고 한다.
아래 그리과 같이 set이 2개가 아니라 n개로 확장이 됐을 때를 생각을 해보자.
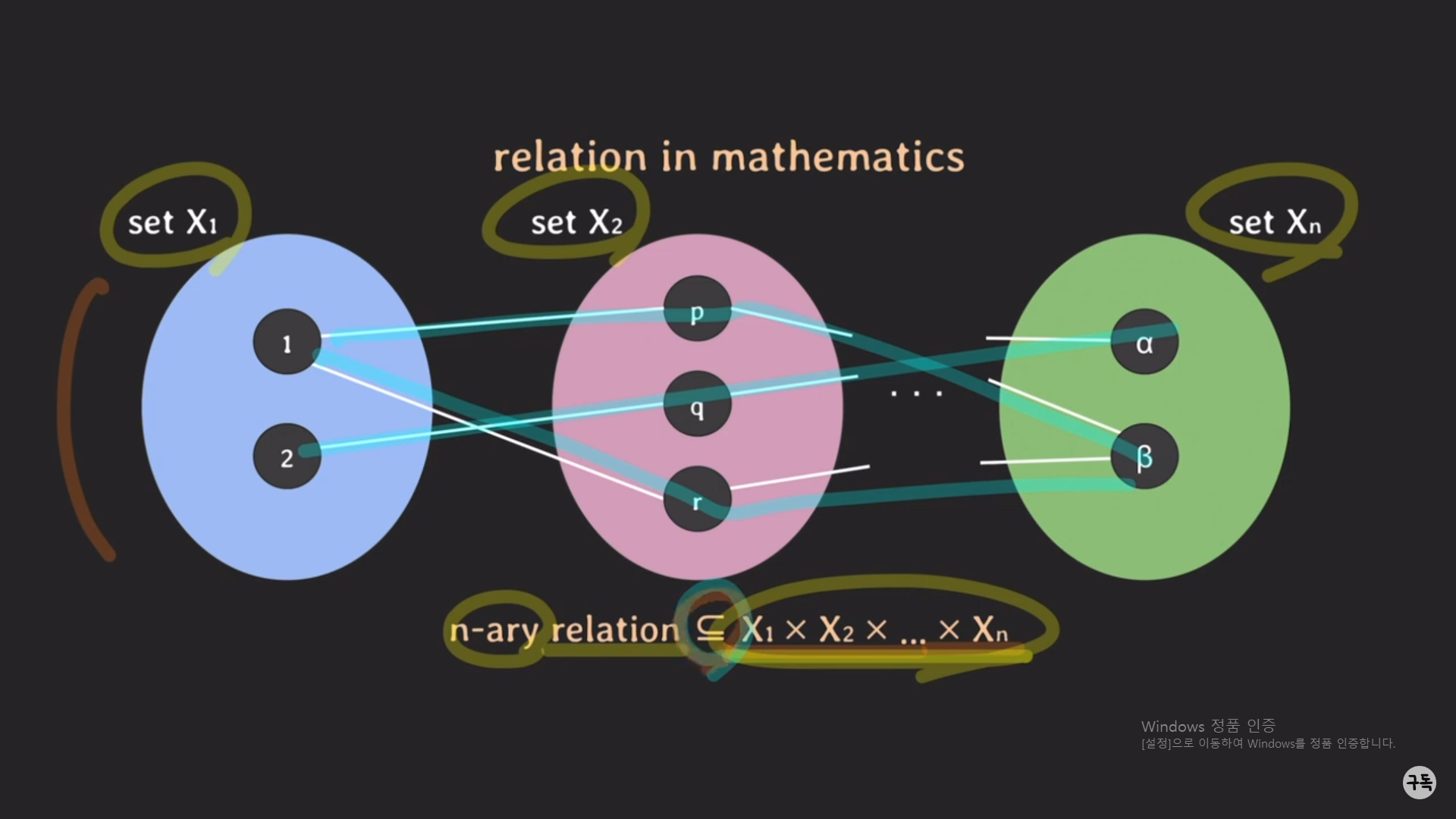
set이 X_n개 있을 때, 그것에 Cartesian Product는 X1 x X2 x ...x Xn으로 표현을 하며, 그것의 부분집합을 n-ary Relation,
즉 수학에서 정의하는 "관계"라고 한다.
이제 이 수학에서의 "관계"가 데이터 베이스에서 어떻게 사용이 되고 있는지 살펴 보자.
그 이전에 도메인(DOMAIN)이라는 용어를 알고 가자.
Relational DBMS에서는 set의 element, value들의 집합(set)을 도메인(DOMAIN)이라고 부른다.
아래에서는 도메인 X1, X2 ... Xn이 있다. ( 각각의 도메인에 이름을 부여해 줄 수가 있다.)


수학에서의 관계(Relation)의 개념을 적용하여 student DB를 구성해 보겠다.


Phone_numbers라는 도메인이 2번 쓰이고 있다.
student를 모델링하려고 하는데, 가만히 생각을 해보니 일반 전화 번호와는 별도로 학생들의 비상 연락 번호도 같이 저장을
하고 싶었던 것이다.
같은 도메인이 사용이 되었지만, 사용되는 역할은 다르다.
각 도메인이 어떤 역할을 하는 지를 나타내는 것이 Attribute이다. (아래 그림에 각 도메인의 Attribute가 있다.)

위와 같이 Attribute가 설정이 되면, 아래와 같이 tuple로 관련이 있는 element들이 표현이 된다.

그러나 위와 같이 Relational Data Model을 표현하는 것은 가독성이 좋지가 않다.
그래서 일반적으로 Relational Data Model은 테이블(Table) 형태로 많이 표현된다.( Tuple보다는 Table형태가 일반적!)
아래는 Relational Data Model을 Table 형태로 표현을 한 것이다.

relation은 Table이라고 생각을 하면 된다. (정확한 relation은 정의는 "set of tuples"이다. 아래 그림 참조!)




relation이라는 용어는 추상적 의미와 구체적 의미를 가진다.
1. 추상적 의미( relation )
맥락 상, relation이 추상적으로 "set of tuples"로 쓰이는 경우!
2. 구체적 의미 ( relation or relation state )
맥락 상, 특정한 시점의 구체적인 테이블을 구성하는 set of tuples로 쓰이는 경우!
이 경우에는 relation이라는 용어 외에, relation state라고도 불린다.
-> relation이라는 용어가 나오면, 1과 2중 어떤 의미로 사용됐는지 잘 구분하자.

Relational Database = set of Relations
관계형 데이터 베이스란 relation들의 집합으로 정의된다.

[ relational database ] = relation들의 집합
[relational database] schema = relation들 사이의 schema(구조) + integrity에 대한 제약(constraints)들의 집합
(integrity와 integrity에 대한 constraints는 후반부에 자세히 설명을 할 것. 지금은 그냥 넘어 가도 ok )
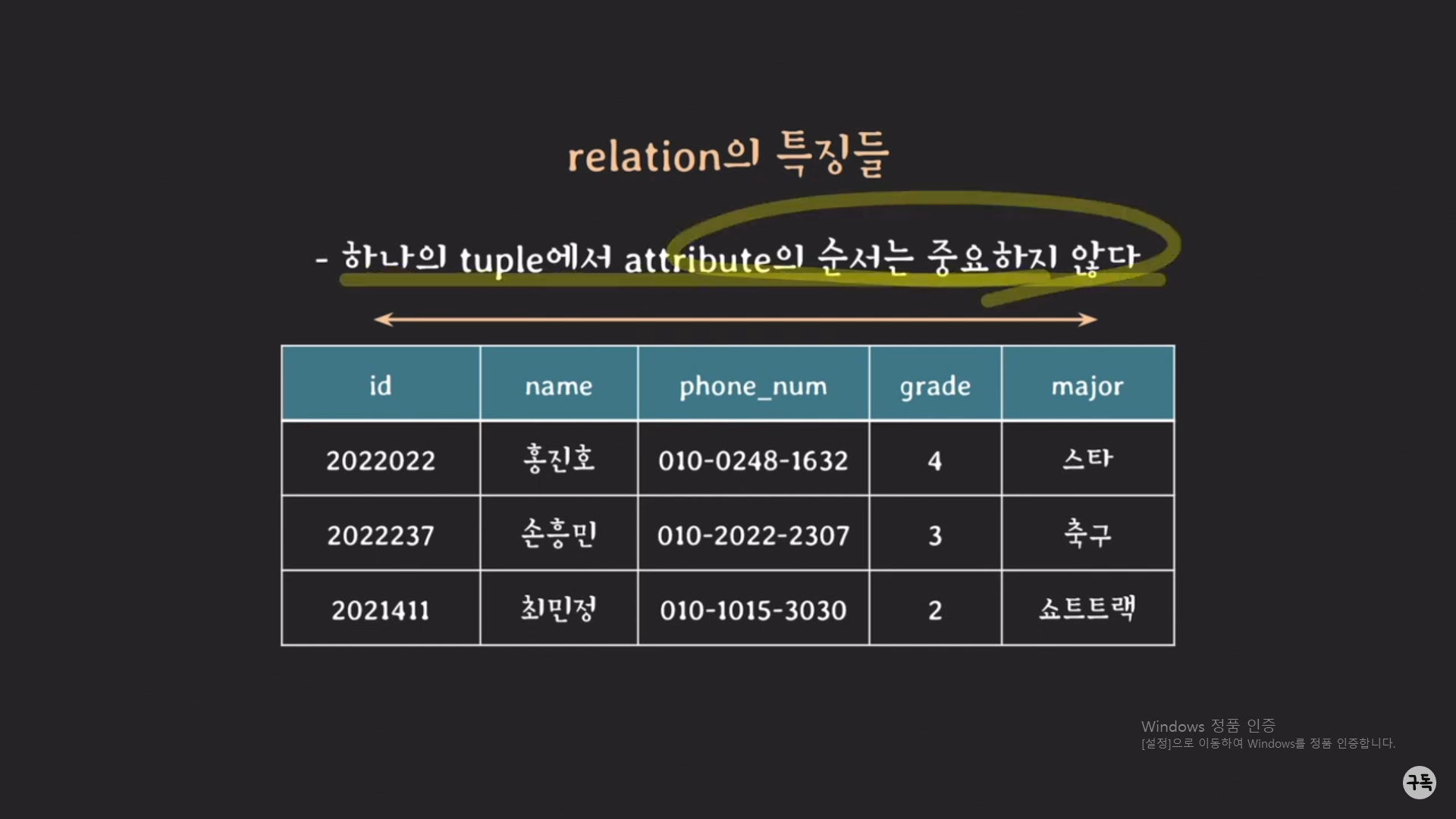
relation의 특징들

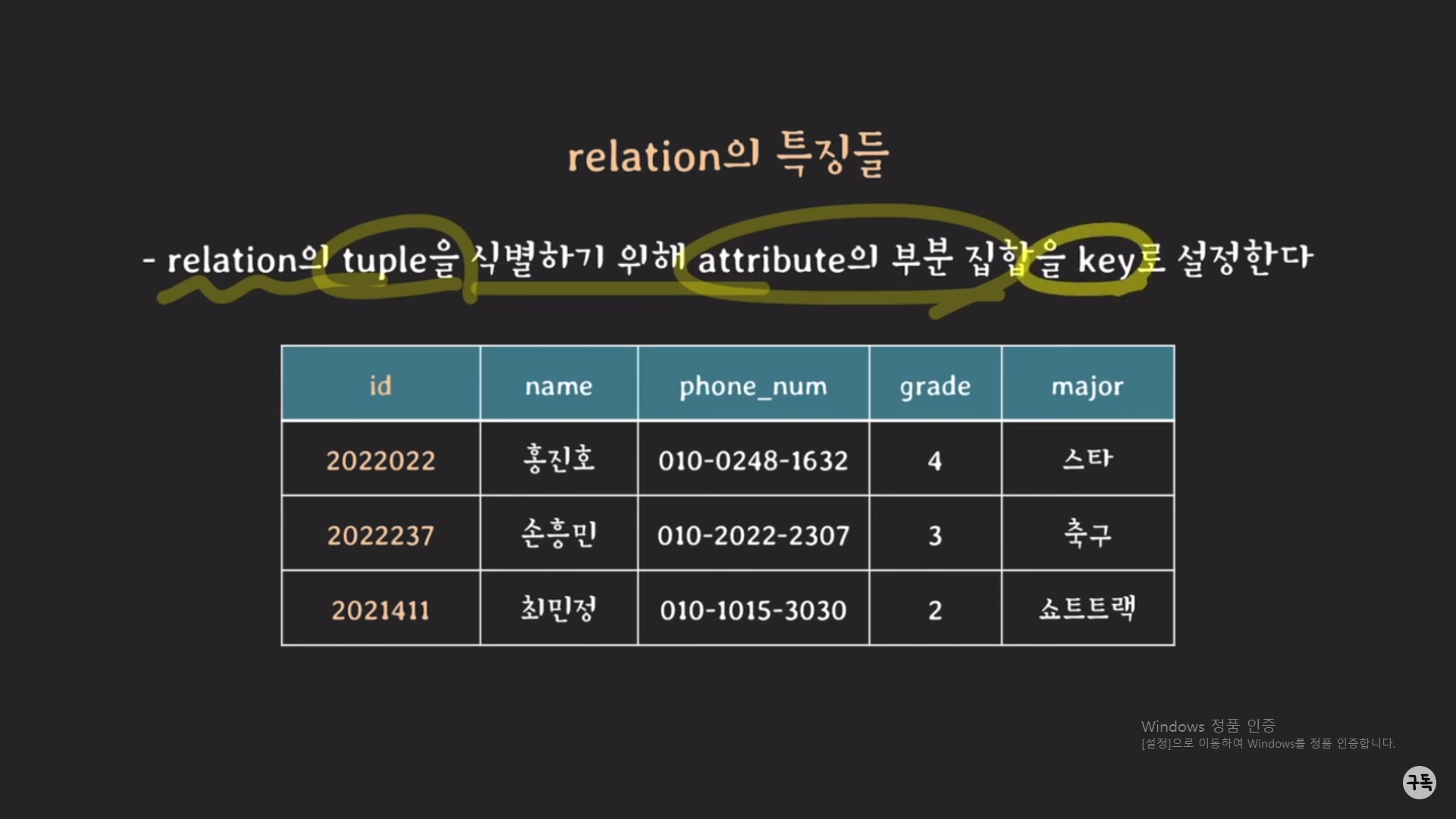

tuple의 순서를 결정하는 방법에는 여러 가지가 있다.
예를 들어, id를 기준으로 정렬을 할 수가 있고, name으로도 tuple을 정렬할 수도 있다.


예를 들어, [address와 major] Attribute를 살펴 보자.
"서울특별시 강남구 청담동" -> "서울특별시" + "강남구" + "청담동"
위와 같이 3개로 분할이 가능하며, 위 3개는 더 이상 [분할이 불가능](atomic)하다.
composite과 multivalued attribute에 대해서는 추후에 자세히 설명을 하겠다.
Null의 의미

null의 의미는 굉장히 중의적이다.
고로, DB에서 NULL은 사용을 하지 않는 것이 좋다.
아래의 그림을 예로 설명을 하겠다.
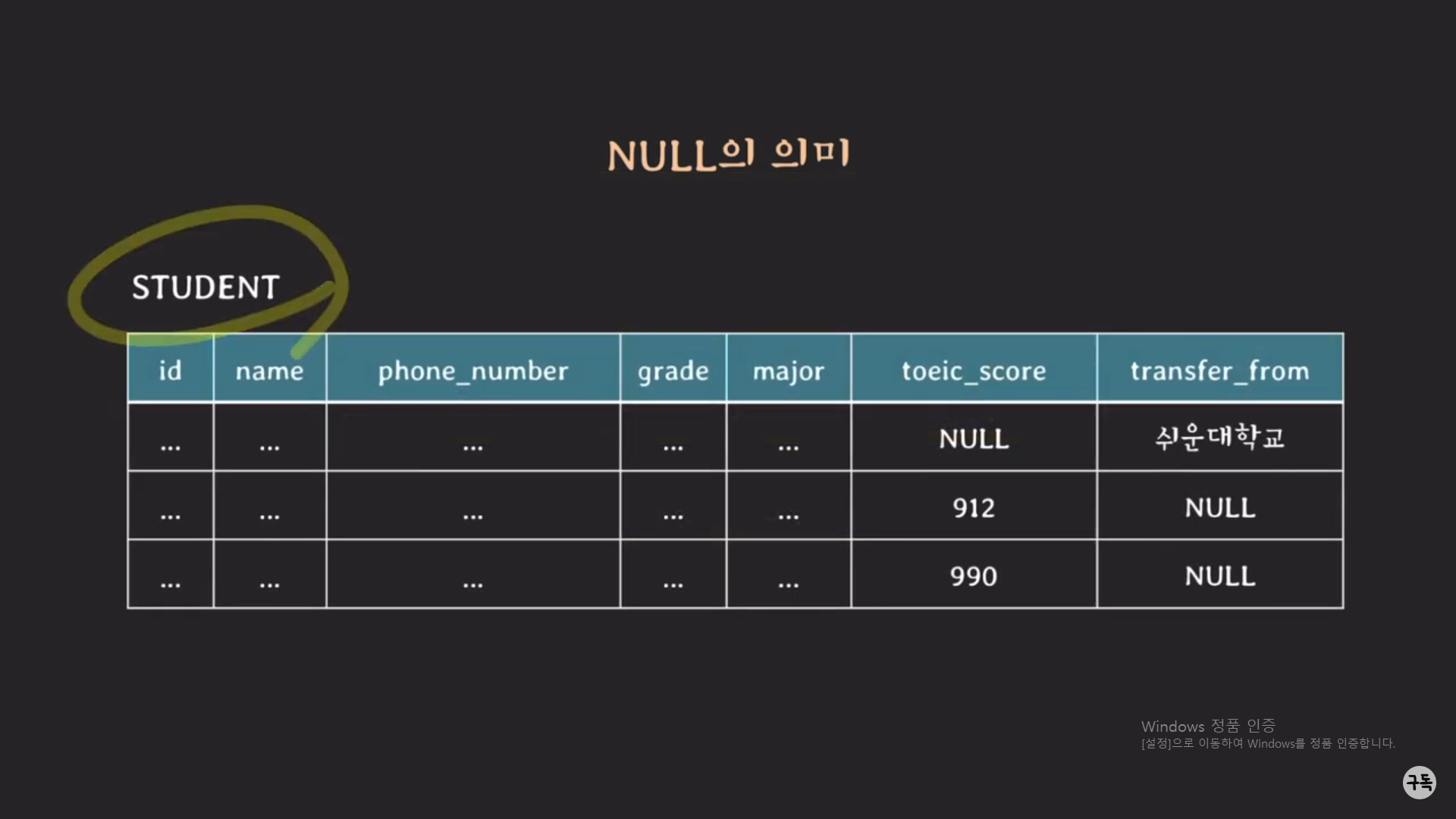
먼저 toeic_score부분의 NULL 의미를 파악해 보자.
경우의 수
1. 아직 TOEIC를 한 번도 친 적이 없어서 점수가 아예 없는 경우
2. TOEIC를 쳤지만, 아직 제출을 하지 않은 경우
3. 제출을 했지만, 어떠한 사정으로 인해 전산에 누락이 된 경우
다음은 transfer_from(편입 이전의 대학교 이름)의 NULL의 의미를 파악해 보자
경우의 수
1. 편입학생이 아닌 경우(해당 사항과 관련이 없음)
2. 편입학을 하였지만, 전상에 아직 업데이트가 되지 않은 경우
KEYS

위 그림에서 superKey의 예시로 3가지가 있는데, 각각을 분석을 해 보겠다.
첫번재
이 superkey는 Player이라는 relation의 모든 attribute를 담고 있다. 즉 각각의 tuple자체가 superkey라는 것이다.
모든 tuple들은 서로 중복을 불허하기에 tuple 자체가 superkey가 된다.
두번째
name자체는 중복을 허락하므로, 단독으로는 superkey가 될 수가 없으나, id가 tuple을 unique하게 식별이 가능하므로, 두
번째 case도 superkey가 된다.
세번째
player들 중에서 back_number(등번호)가 같은 경우는 존재한다. 그러므로 back_number 단독으로는 결코 superkey가 될
없다. 그러나 같은 팀 내에서는 같은 back_number가 존재하지는 못한다. 고로 back_number와 더불어 team_id가 같이 있
있기에 이것또한 superkey가 된다.


Primary Key = Candidate Key && superkey로 채택
걍, Candidate Key중에서 이것을 superkey로 사용을 하겠다고 하면, 그게 primary key임.
(일반적으로, Primary Key는 Candidate Key중 Attribute의 수가 적은 것을 고른다.)

보통, relational Schema를 적을 때, primary key인 attribute부분에는 그 밑에 언더바를 붙여 준다.
위 그림에서는 {id}가 primary key이기에 id밑에 언더바 표시가 있다.

PK = Primary Key의 약자
team_id Attribute는 Team이라는 relation의 PK인 id를 가리키고(참조) 있으므로, {team_id}가 foreign key가 된다.
Constraints(제약 사항)
Constraints : relation database의 relation들이 항상 지켜줘야 하는 제약 사항.
Constraint의 종류


schema-based constraints에는 아래의 5가지 종류로 나뉜다.





'CS 과목(CS科目) > 데이터 베이스(データベース)' 카테고리의 다른 글
| 6. SQL로 데이터 조회하기(SQLでデーターを照会)PART 2 (0) | 2022.12.08 |
|---|---|
| 5. SQL로 데이터 조회하기(SQLでデーターを照会しょう)part 1 (0) | 2022.12.08 |
| 4. SQL로 DB에 데이터를 추가(insert)하고 수정(update)하고 삭제(delete)하는 방법(SQLでDBへデーターを挿入(insert)/修正(update)/削除(delete)する方法) (0) | 2022.12.08 |
| 3. SQL의 개념과 SQL로 데이터베이스를 정의(SQLの概念とSQLでDBを作ろう) (0) | 2022.12.07 |
| 1.데이터 베이스의 기본 개념(データベースの基本的な概念) (0) | 2022.12.06 |



