


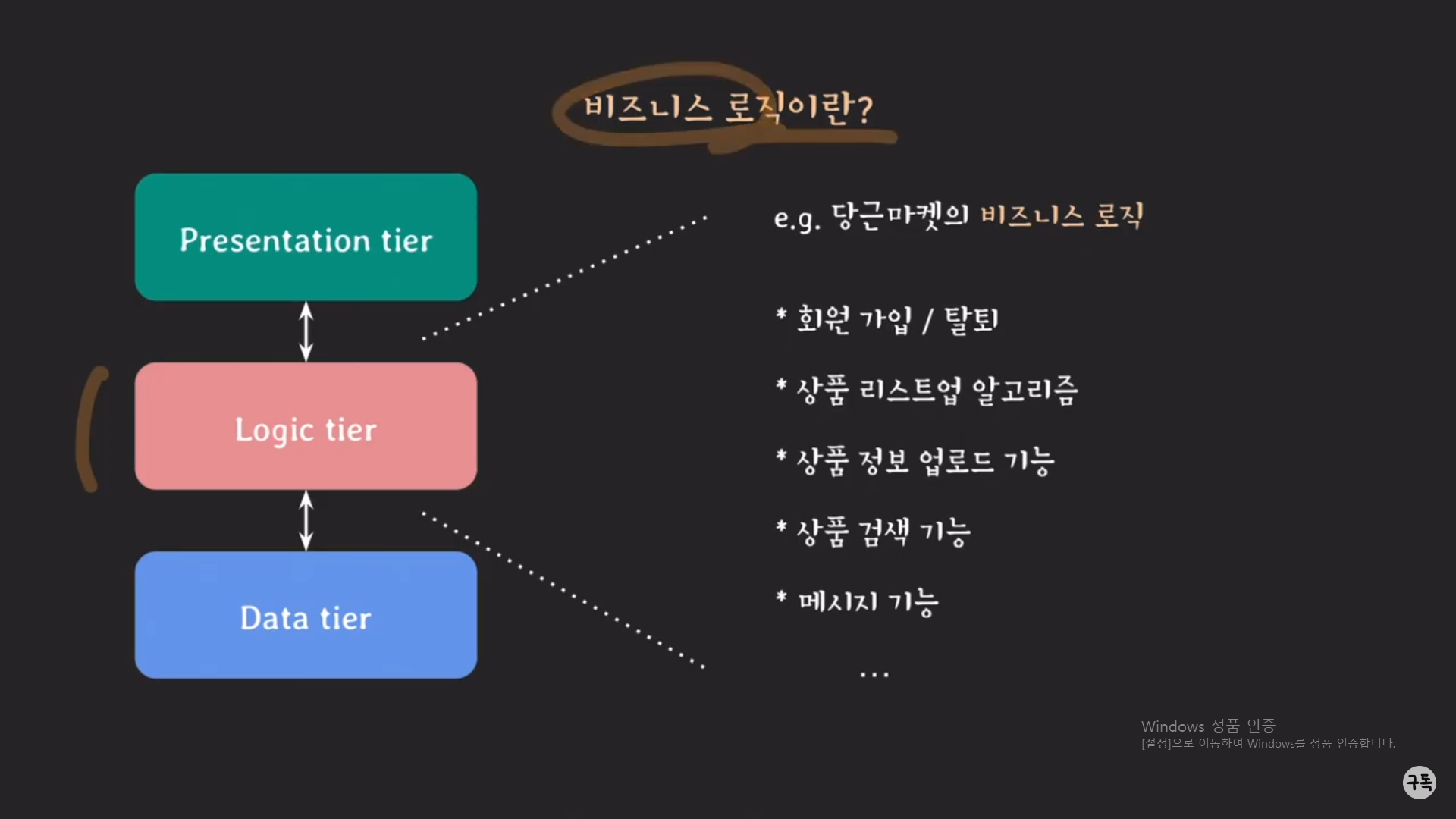
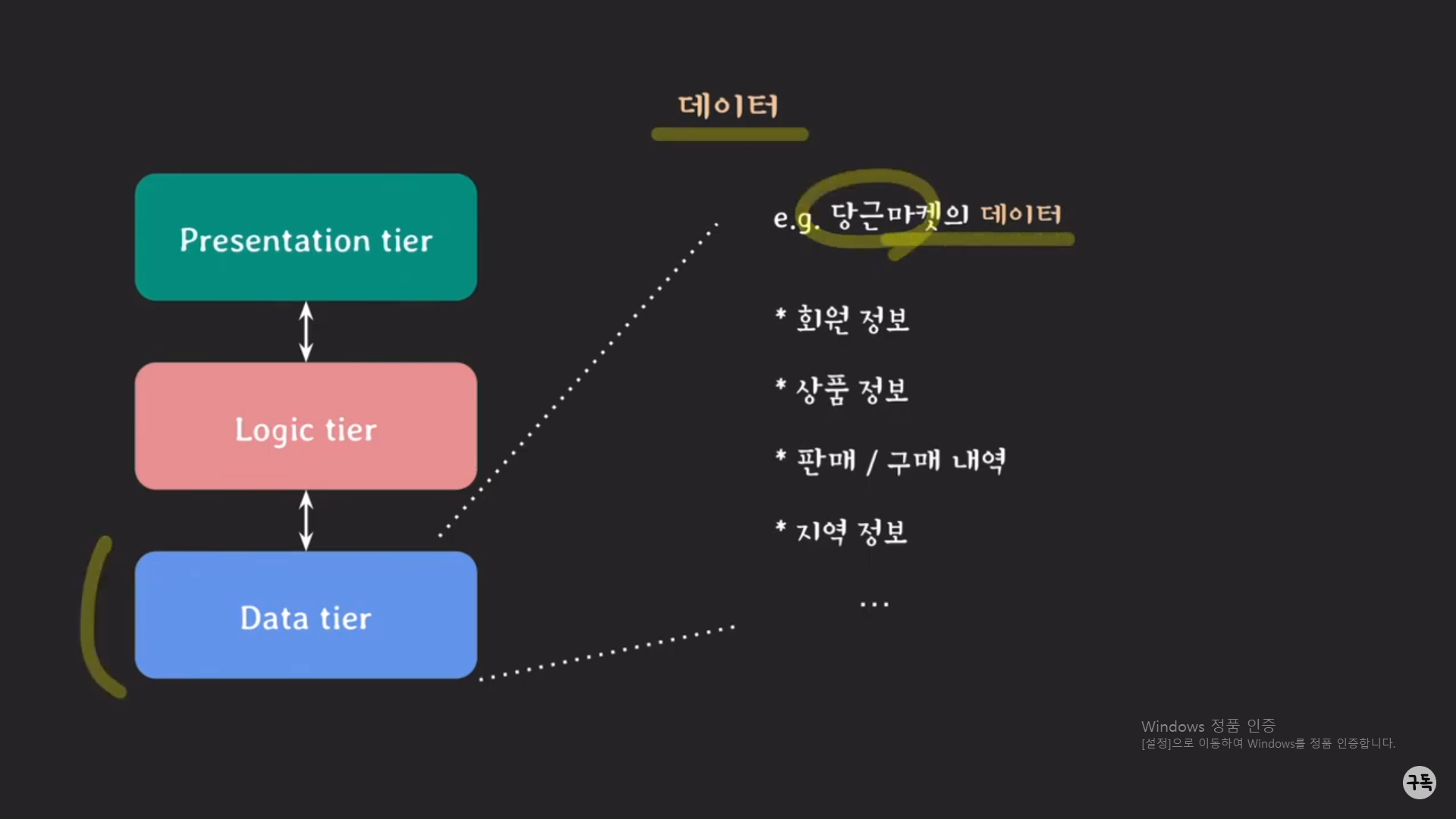
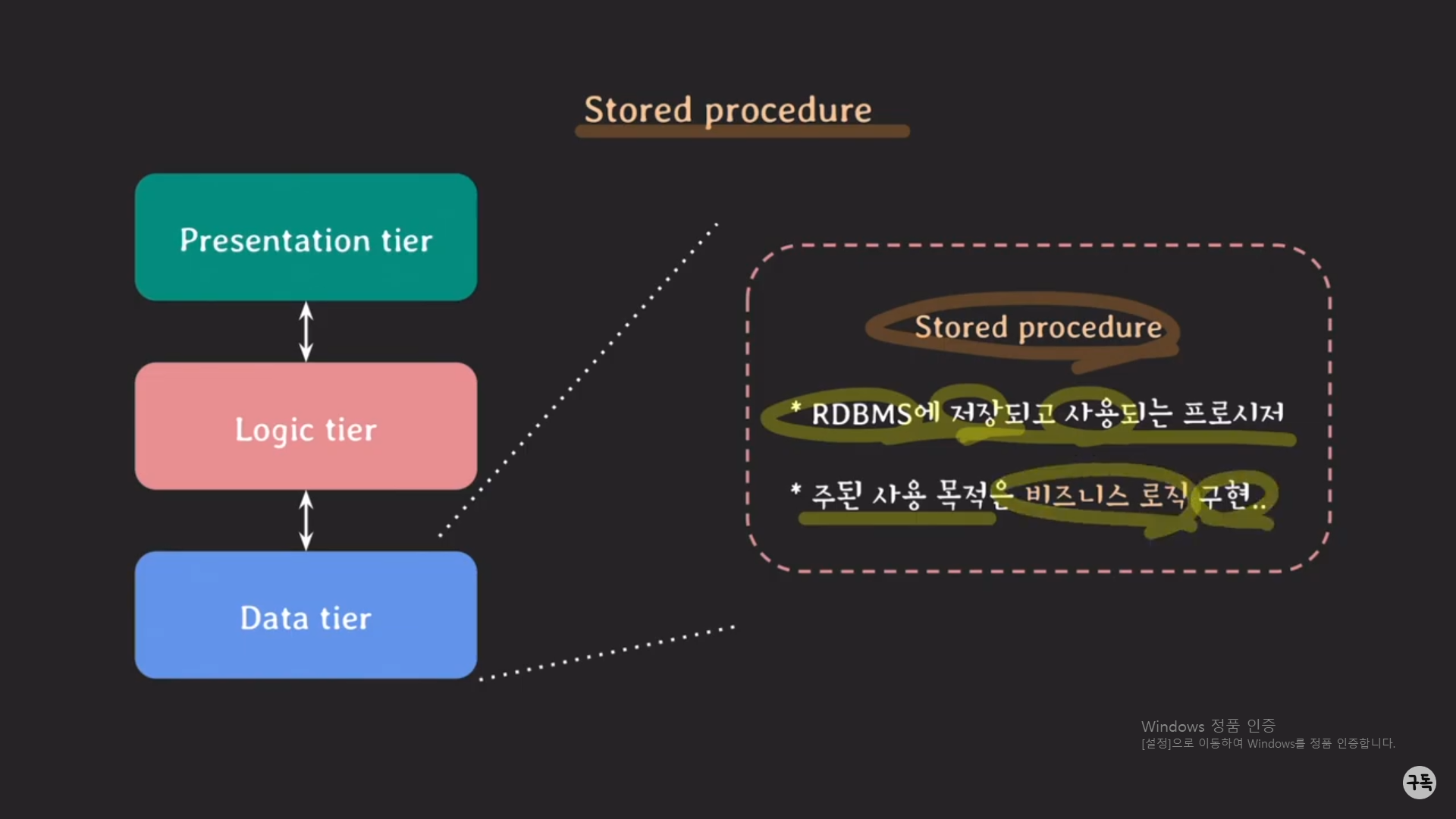
주된 사용 목적이 비즈니스 구현이라는 것은 비즈니스 로직이 Logic tier뿐 아니라 Data tier에 존재할 수도 있다는 뜻이다.
stored procedure의 장점
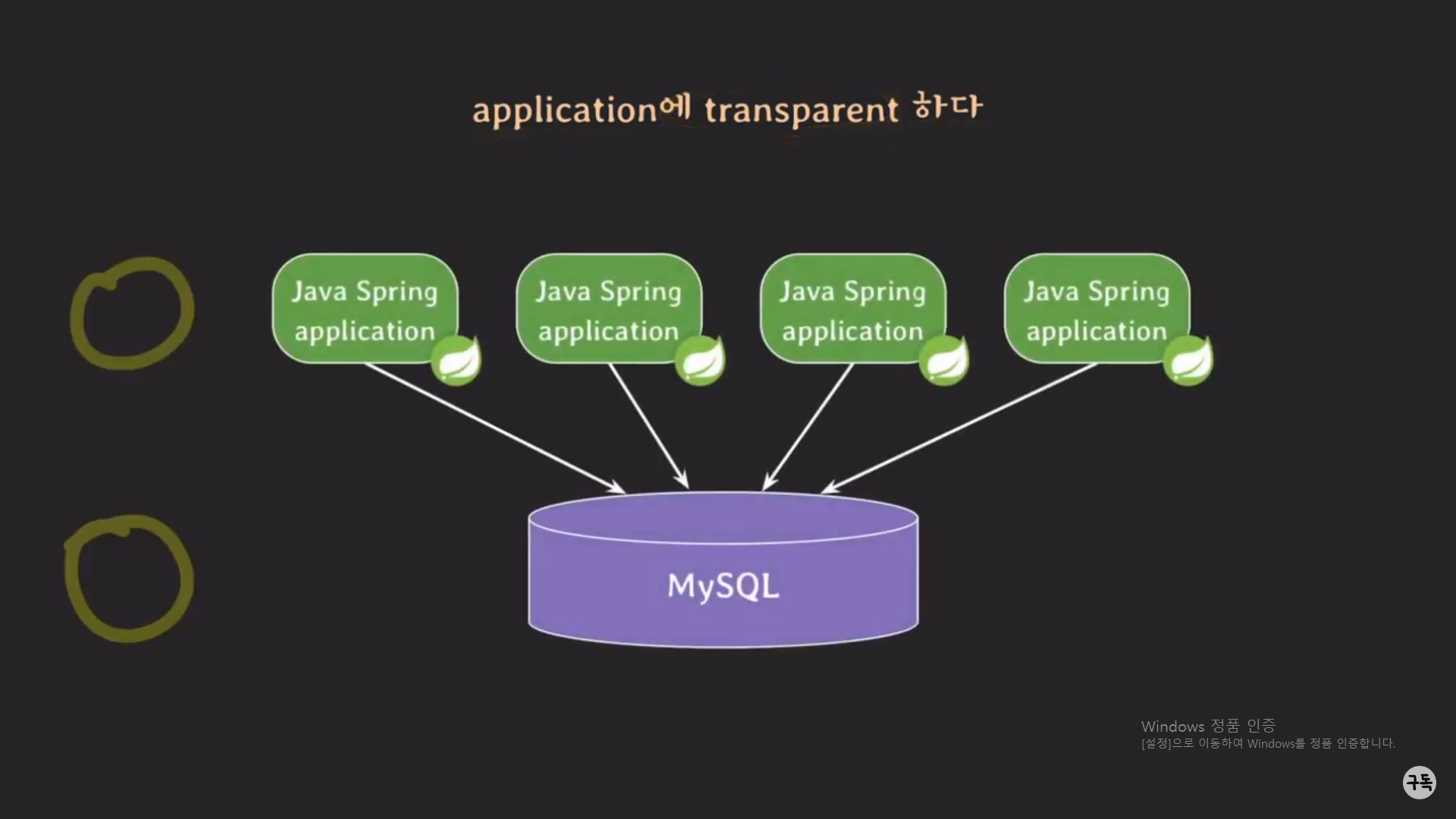
위 그림은 프론트엔드(Presentation tier)를 제외한 백엔드 부분(Logic tier, Data tier)부분만을 나타내고 있다.
Logic tier에는 현재 4개의 Spring 서버가 있고, Data tier에는 1개의 MySQL 서버가 있는 상황이다.
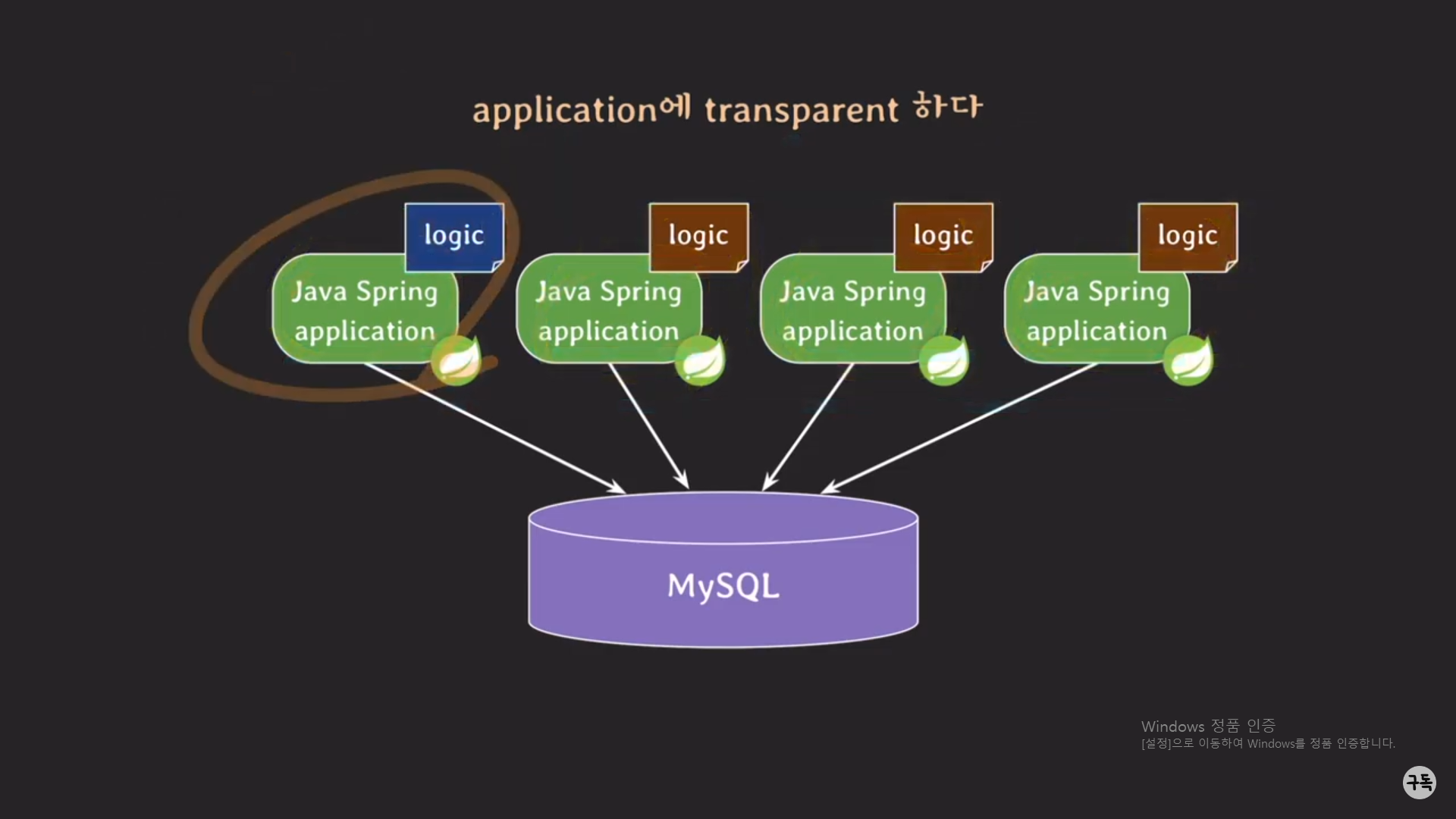
4개의 자바 서버는 똑같은 logic으로 이루어 져 있다.
만약 logic을 바꿔줘야 할 때, 4개를 동시에 바꾸면 안된다.
왜냐하면, 4개의 서버를 동시에 바꾸는 동안에 만약 client에서 어떠한 request가 있을 경우, 그 request에 response가 안됨.
그래서 순차적으로 4개의 서버의 코드를 바꿔야 한다.
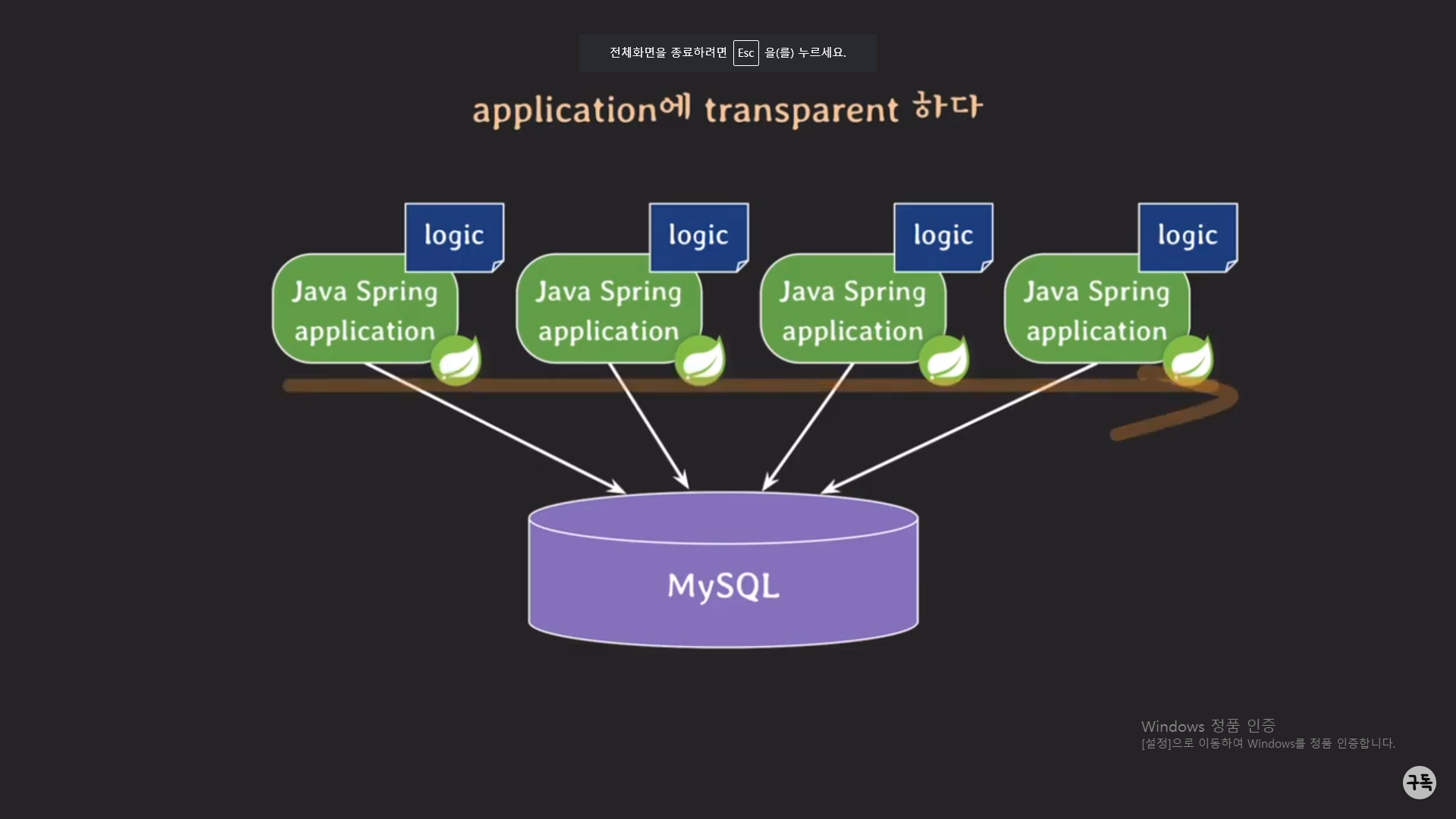
위와 같이 4개의 서버를 업데이트를 하기 위해 새롭게 컴파일하고 또 새로운 배포 파일을 만들고 또 그 배포 파일을 4개의
서버에 순차적으로 업데이트 시키고 , 이런 일련의 과정들이 너무 복잡하다.
이걸 Procedure로 해결이 가능하다.(아래 참조)
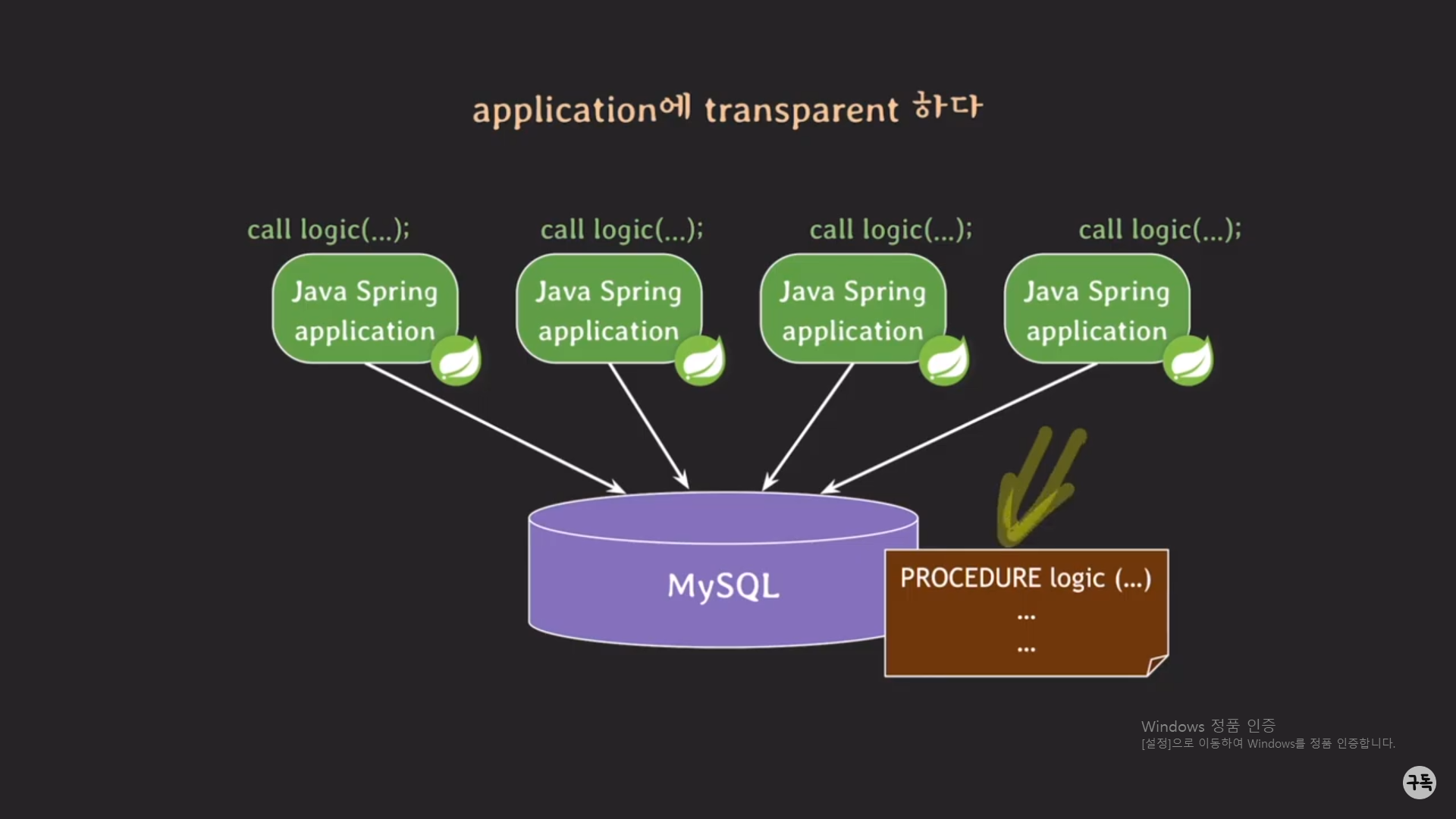
만약 logic이 procedure 안에 모두 정의가 돼 있고, logic tier에서는 "call procedure"의 형태로 호출만 하고 있는 상황이라고
가정을 해보자.
만약 이 logic을 바꾸고 싶다고 하였을 때, [procedure의 이름, 매개변수]에 대한 변경은 없고, procedure의 body부분만 변
경을 시키고 싶다면, logic tier에서는 아무런 변경 작업이 필요가 없고, Data tier에 저장이 돼 있는 procedure의 body 부분
만 변경을 하면 된다.
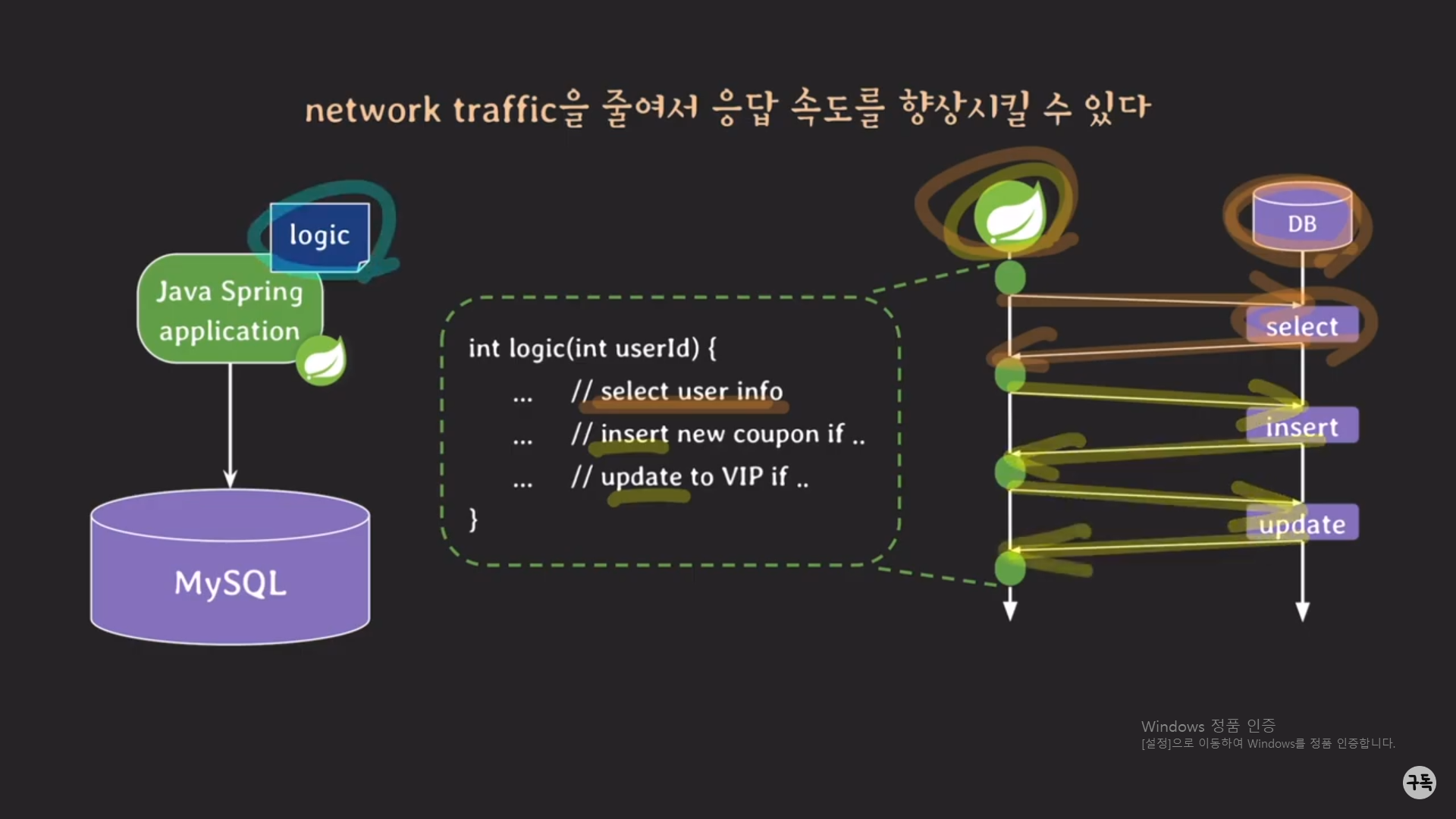
logic이 procedure가 아니라, logic tier에서 구현이 돼 동작하고 있는 경우에는 상당한 traffic이 발생할 가능성이 높다.
logic이 [ SELECT, INSERT, UPDATE ]로 구성이 돼 있는데, Spring과 MySQL은 서로 다른 서버에서 동작을 하고 있기 때문
에 예를 들어, SELECT를 수행하기 위해서는 DB가 동작하고 있는 서버로 REQUEST를 요청하고, 또 DB 서버에서는 그
REQUEST를 처리한 뒤, 이번에는 SPRING이 동작하고 있는 서버로 REPONSE를 보내줘야 한다. INSERT와 UPDATE를
실행할 때에도 똑같은 종류의 TRAFFIC이 생긴다.
근데 만약 logic이 procedure로 관리가 되고 있다면???(아래 참조)
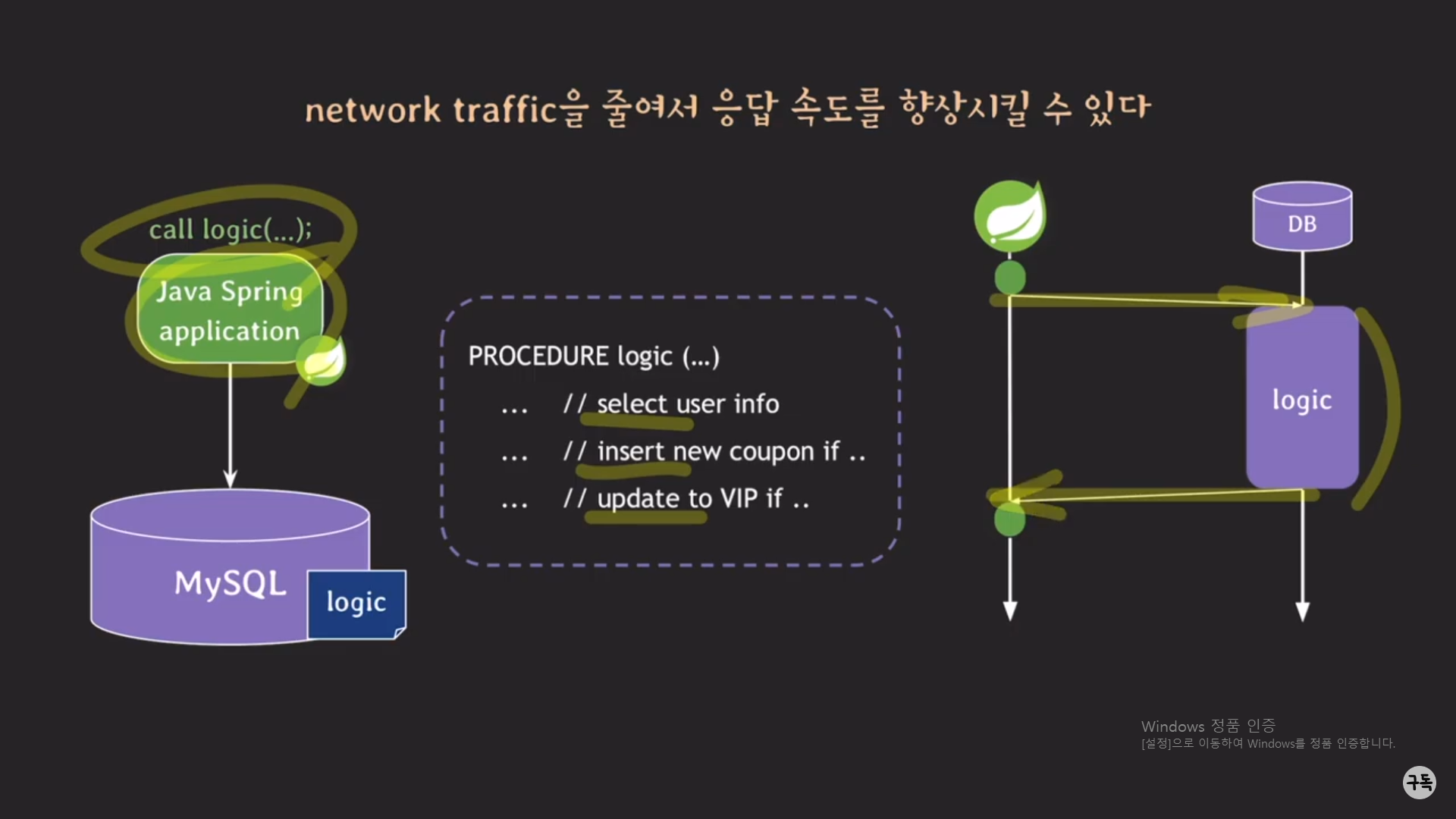
Spring은 딱 한번의 call logic()의 호출로 DB 서버에 REQUEST를 하게 되며, 위와 같이 traffic이 굉장히 줄어든다.
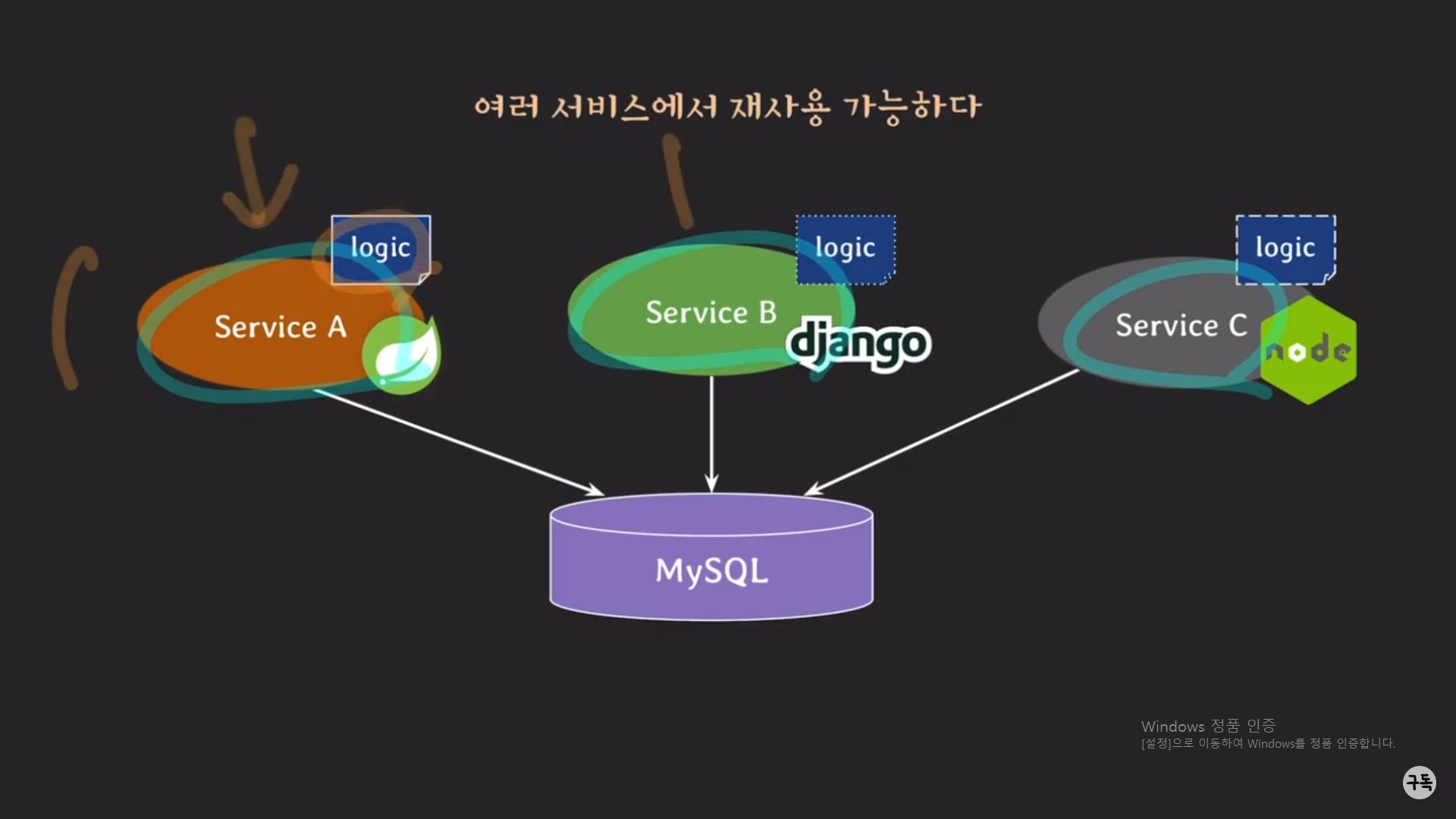
위 그림처럼 3개의 서버가 있고, 이 3개의 서버는 1개의 DB 서버(MySQL)를 공유하고 있다고 하자.
하나는 Spring으로 구성이 돼 있고, 또 하나는 Python으로 구성이 돼 있고, 나머지 하나는 Java Script로 구성이 돼 있다.
이때, 각각의 서버에 똑같은 기능을 하는 logic을 만들어야 한다고 했을 때, 각 서버는 각각의 언어로 logic을 구현을 해야 한
다.. 똑같은 기능을 하는 logic임에도 불구하고....
그런데 만약, 해당 logic이 아래의 그림과 같이 DB 서버에 procedure의 형태로 저장이 돼 있다면 어떨까??
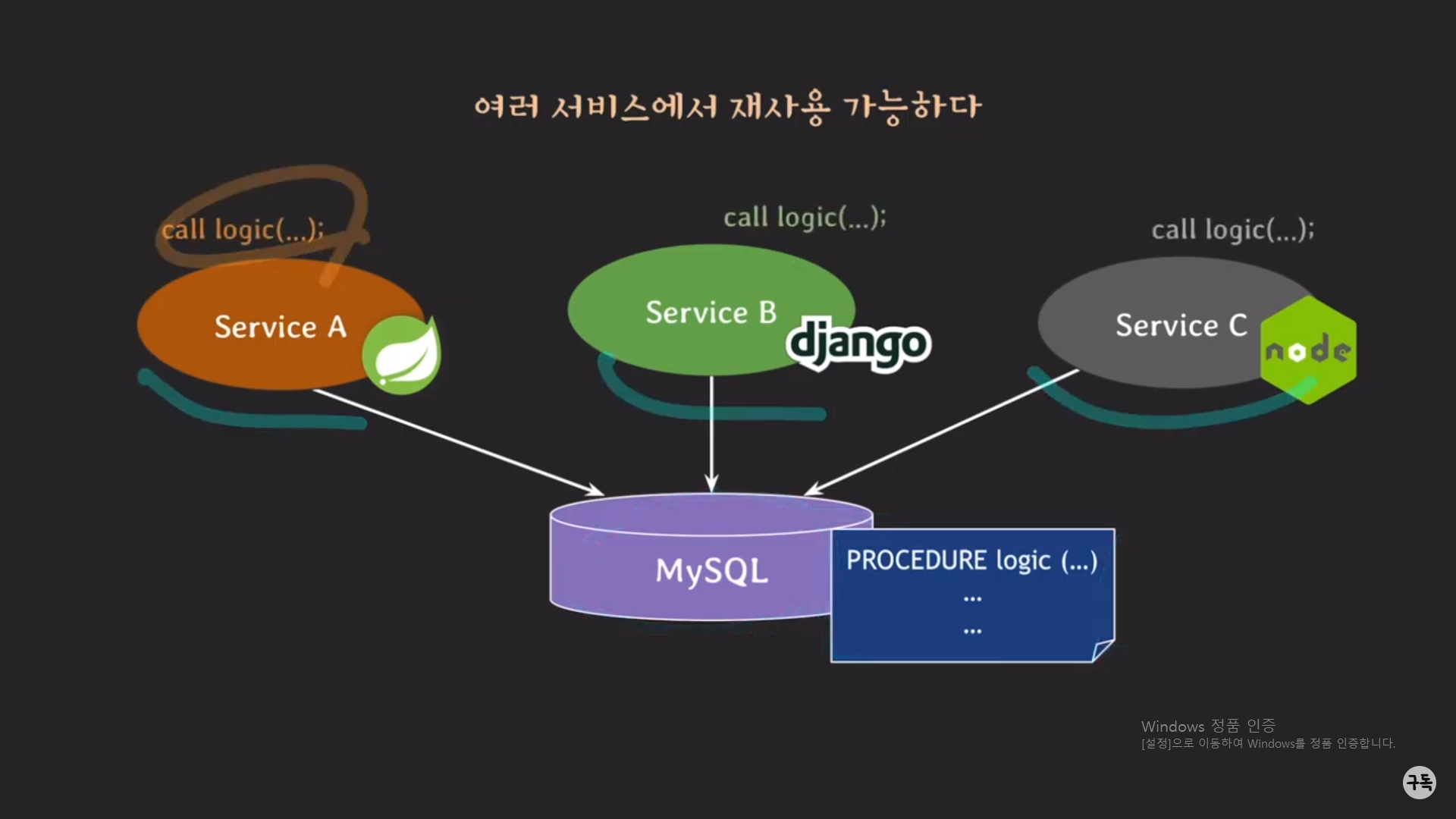
각 서버는 call logic() 명령어로 procedure를 호출만 해주면 된다.
이렇게, procedure는 여러 종류의 서비스에서 사용이 될 수가 있다.
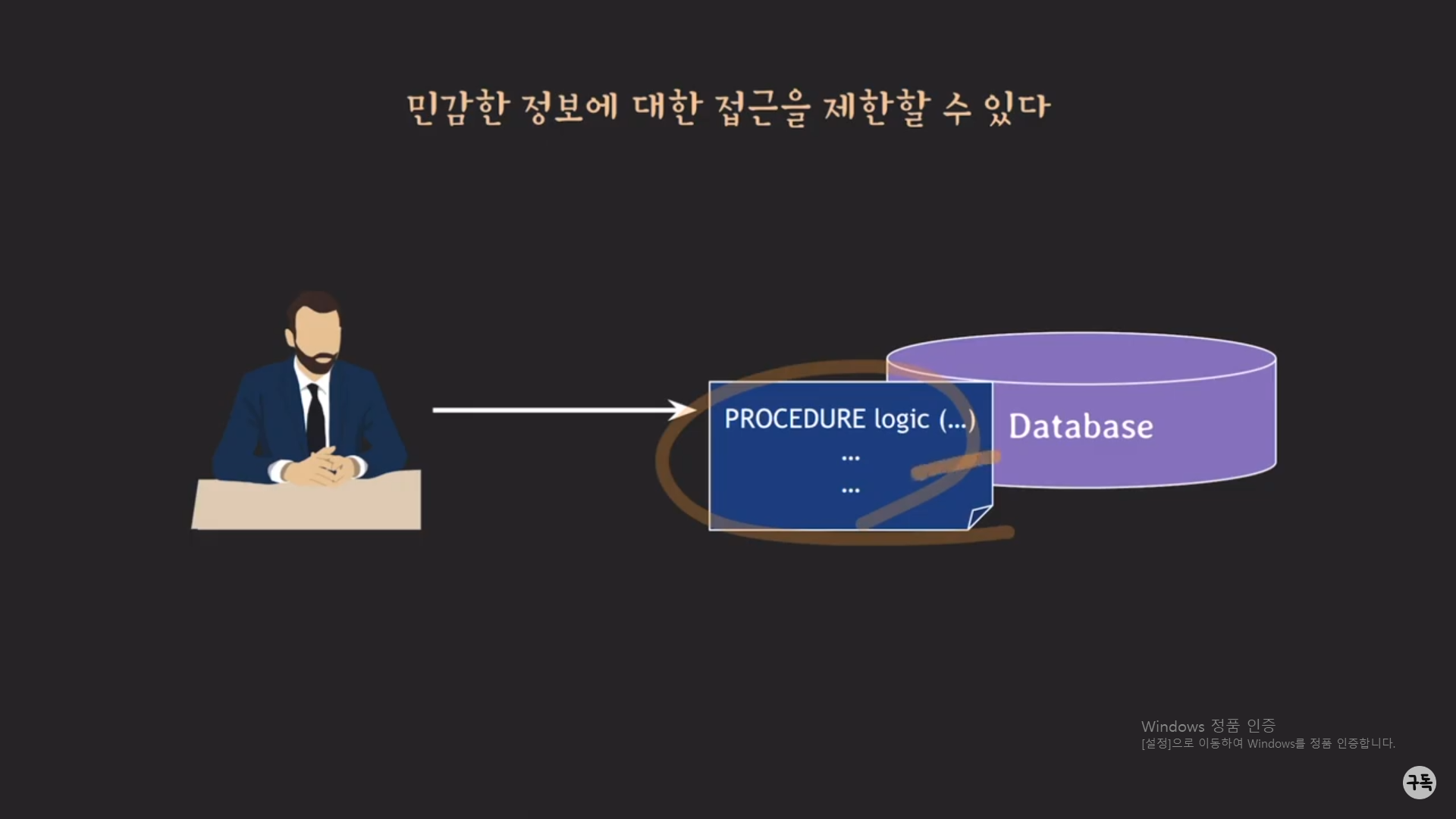
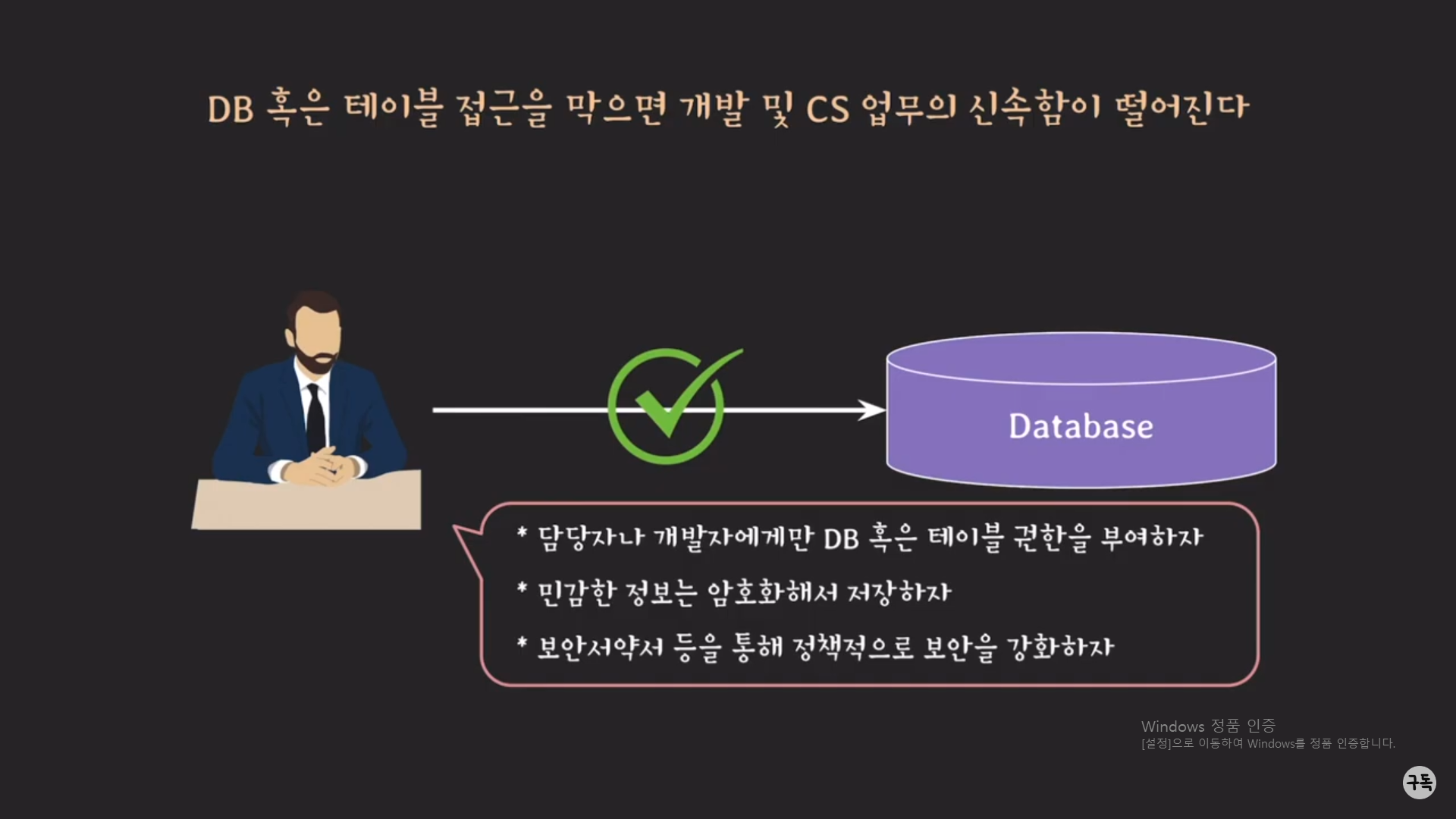
아무리 개발자라고 하더라도, 예를 들어 DB에 있는 고객의 신용카드 비밀번호, 계좌번호 등의 민감한 데이터에 접근할 수
없게 해야 한다.
그런데 그러한 민간한 데이터라도 Manipulating하여 서비스를 개발을 해야만 하는 것이 개발자의 입장이다.
이때 개발자는 procedure를 통하여 민감한 데이터에 직접적인 접근은 불가능하지만, procedure를 호출하여 DB에 간접적
으로 접근을 함으로서 서비스를 개발할 수 있기에, procedure은 정보 보안 측면에서도 유리하다.
stored procedure의 단점 및 실무에서 쓰기 조심스러운 이유
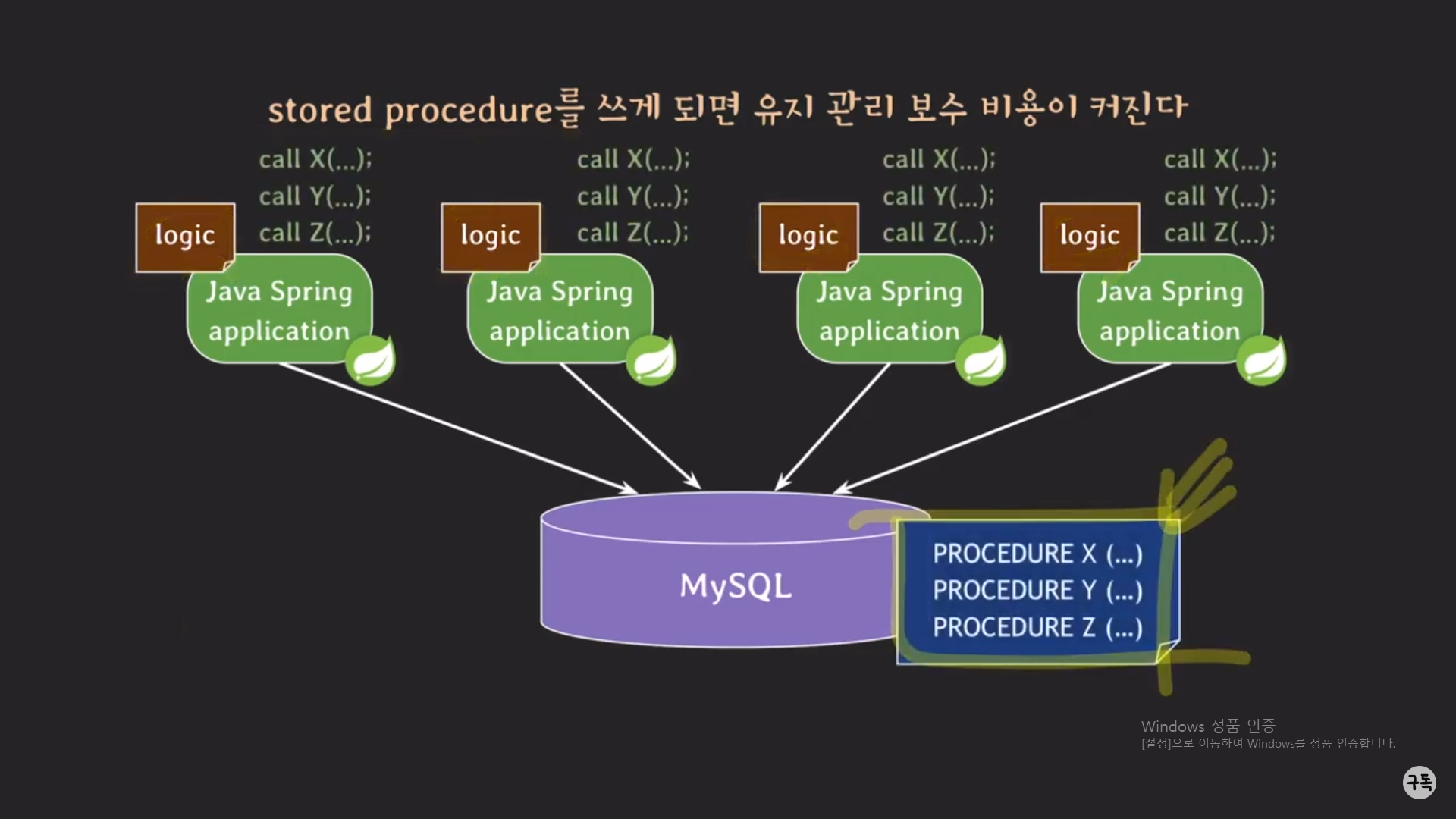
logic tier에 X,Y,Z라는 일부 비즈니스 로직이 있다고 하자.
이 말은 DB 서버에도 일부의 비즈니스 로직이 존재한다는 뜻이다.
이렇게 되면, logic tier에 있는 비즈니스 로직 코드를 봤다고, Data tier에 있는 비즈니스 로직 코드를 봤다가 왔가 갔다 해
야 한다. 이렇게 되면 아래와 같은 단점이 생긴다.
1.비즈니스 로직을 파악하는데 시간이 더 오래 걸리고,
2.버전 관리도 logic tier, data tier 둘 다 해줘야 한다.
3.모든 비즈니스 로직 코드가 logic tier에만 있다면, 개발자는 Spring과 Java만 알면 개발이 가능하지만 만약 procedure를 사용하게 된다면, procedure와 관련된 SQL문법도 더불어 알아야 하는 비용이 발생한다.
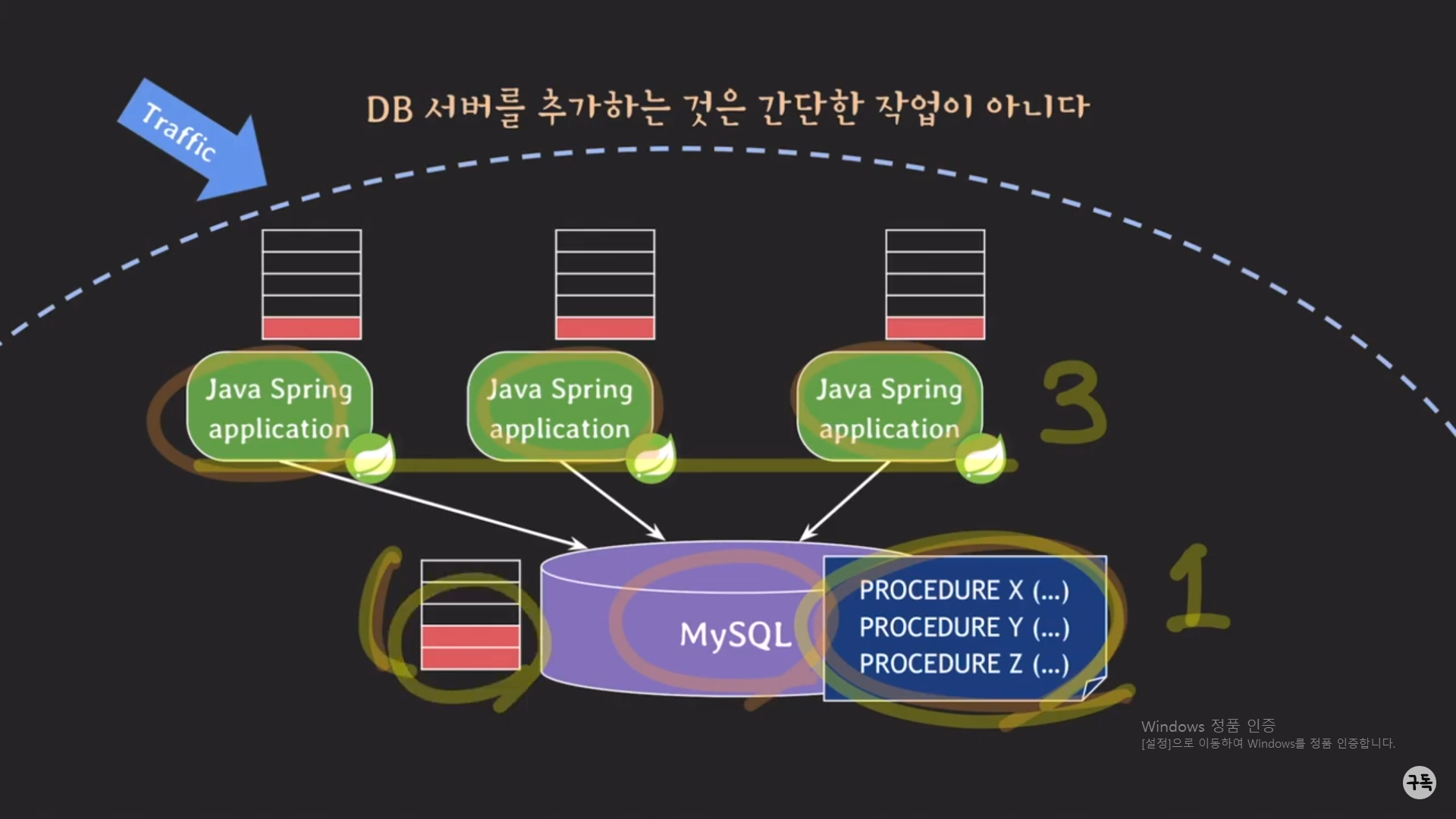
Spring 서버 3대, MySQL 서버 1대가 있고, 비즈니스 로직의 일부가 procedure형태로 DB에 들어 가 있다고 하자.
이때 클라이언트 3명이 각각의 Spring 서버에 Request를 했면, 각 Spring 서버는 1개의 Request에 대해서만 처리를 해주
면 된다. 그러나 비즈니스 로직이 MySQL 서버에 procedure형태로 저장이 돼 있으므로, Request에 대해 처리를 해주기위
해 3대의 Spring 서버가 동시에 call logic()의 형태로 MySQL에 저장돼 있는 procedure를 호출하여, MySQL 서버는 3개의
procedure를 처리한다.
이때의 Spring 서버와 MySQL 서버에 가해지는 부하를 생각해보자
각Spring 서버는 1개의 Request에 대해서만 처리를 하면 되므로, CPU와 메모리에 여유가 있다.
반면, MySQL 서버는 3대의 Spring 서버의 Request를 처리하기에 약 3배의 부하가 CPU와 메모리에 가해진다.
그럼 아래와 같이 클라이언트가 3명이 아니라 굉장히 많은 클라이언트가 Traffic을 보내면 어떻게 될지 살펴보자.
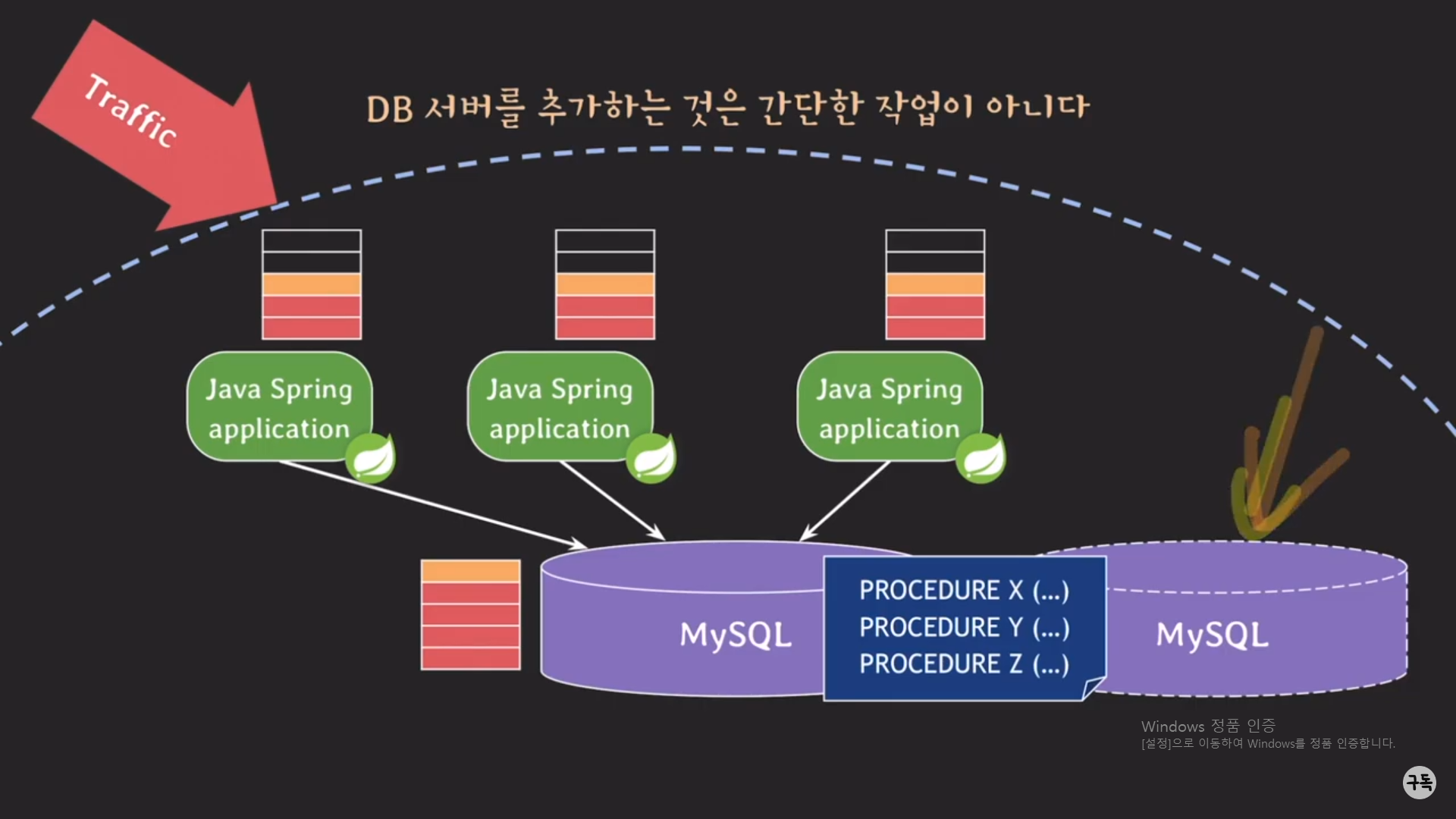
이때의 MySQL 서버는 Spring 서버로부터 수많은 procedure이 호출이 돼어, procedure들의 처리로 인해 CPU와 메모리
에 엄청난 부하가 일어나서, 클라이언트가 보낸 Request에 대해서 굉장히 늦게 반응을 할 것이다. 그것은 서비스를 제공하
는 업체 입장에서는 피해야 할 것이다.
Q. 아니 그럼, 걍 MySQL 서버를 1대 더 늘리면 안돼나?? 그게 무슨 문제가 있다고 호들갑이지???
A. 아니, 현재 사용 중인 MySQL 서버의 CPU와 메모리의 사용량이 90%인데, 이 상태에서 어떻게 새로운 MySQL 서버에
DB 내용을 복사를 해주냐??? procedure에 대한 처리도 지금 제대로 못하고 있는데...
-> 이 상황에서는 DB 서버를 추가해주는 것이 거의 불가능에 가깝다.
그러나 logic tier의 서버를 추가하는 것은 간단한다. 왜냐하면 DB 서버처럼 데이터를 갖고 있지 않기 때문에 신규 서버에
무언가를 복제해줘야 하는 비용이 발생하지 않기 때문이다. 아래에서 자세히 보자.
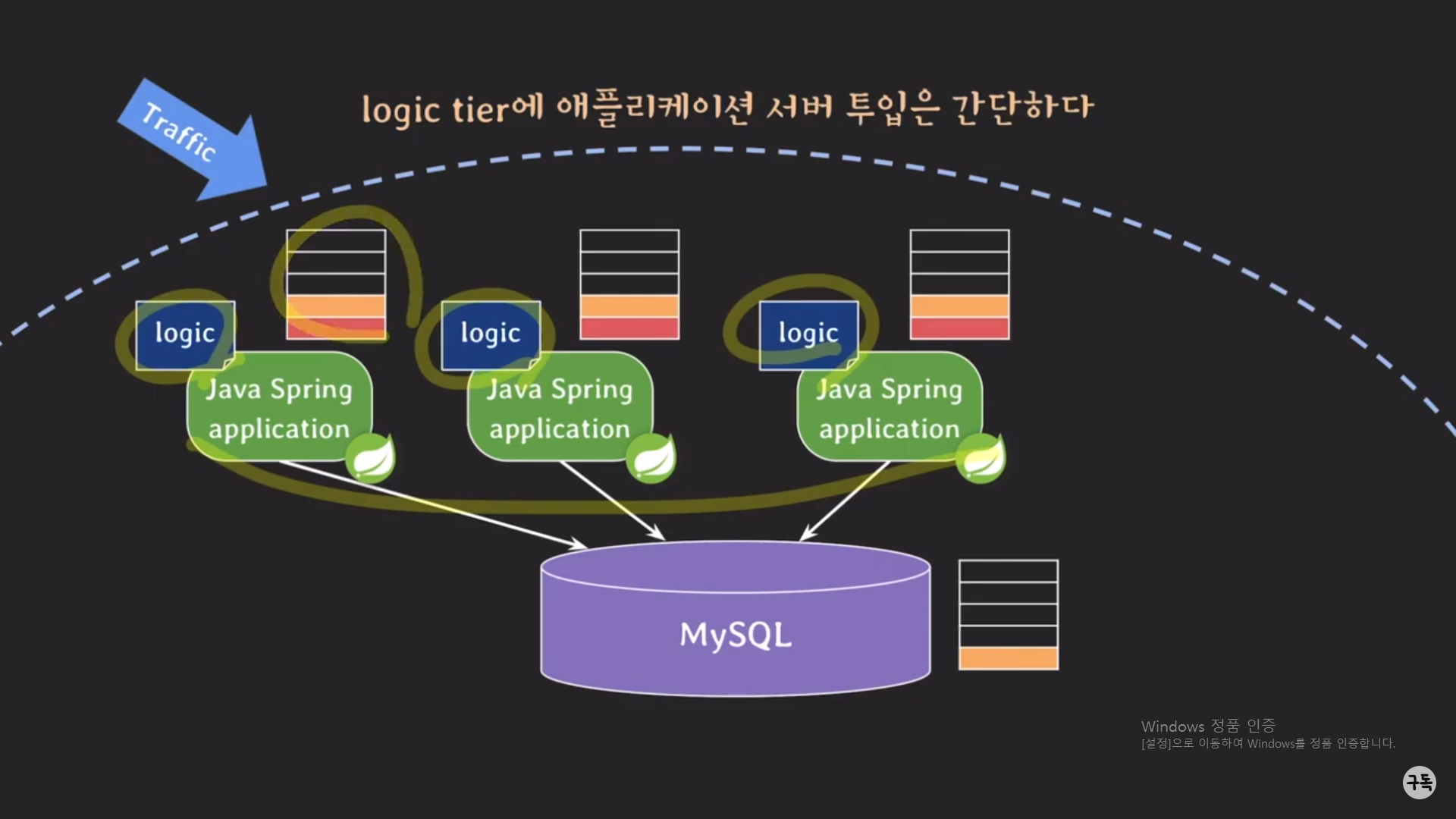
비즈니스 로직에 더 이상 procedure를 호출하지 않으므로, MySQL 서버의 CPU와 메모리 사용량은 적어 진다.
이제 거의 모든 Request는 3대 Spring 서버에 골고루 분산이 돼서 처리가 된다.
그럼 이제 트래픽이 엄청나게 몰려 왔다고 가정을 해보자.
그럼 역시나 Spring 서버의 CPU와 메모리의 사용량이 엄청나게 늘어나서 작업 속도가 현저히 떨어 질 것이다.
이때, Spring 서버를 증설하면 어떻게 될까??
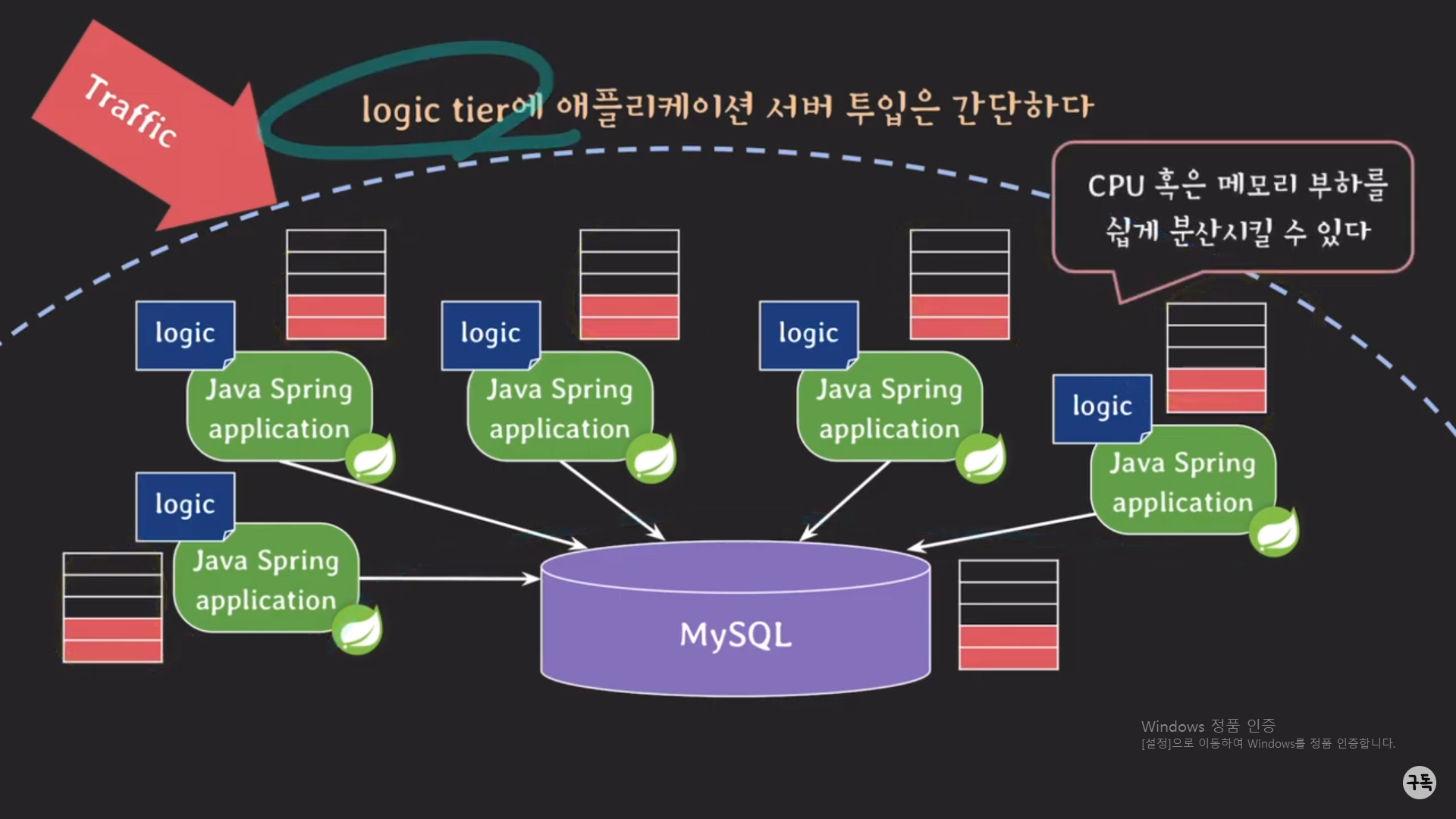
위에서도 한 번 언급을 하였지만, Spring 서버에는 DB 서버와 같이 데이터를 가지고 있지 않기 때문에 서비스 중이라도 언
제든지 Spring 서버를 증설하면 된다. ( 위 그림에서는 2대의 Spring 서버를 증설한 것이다.)
2대의 Spring 서버를 증설함에 따라, 굉장히 많았던 트래픽들이 분산이 돼서 원할히 클라이언트의 Request에 대해서
Response해 줄 수가 있게 됐다.
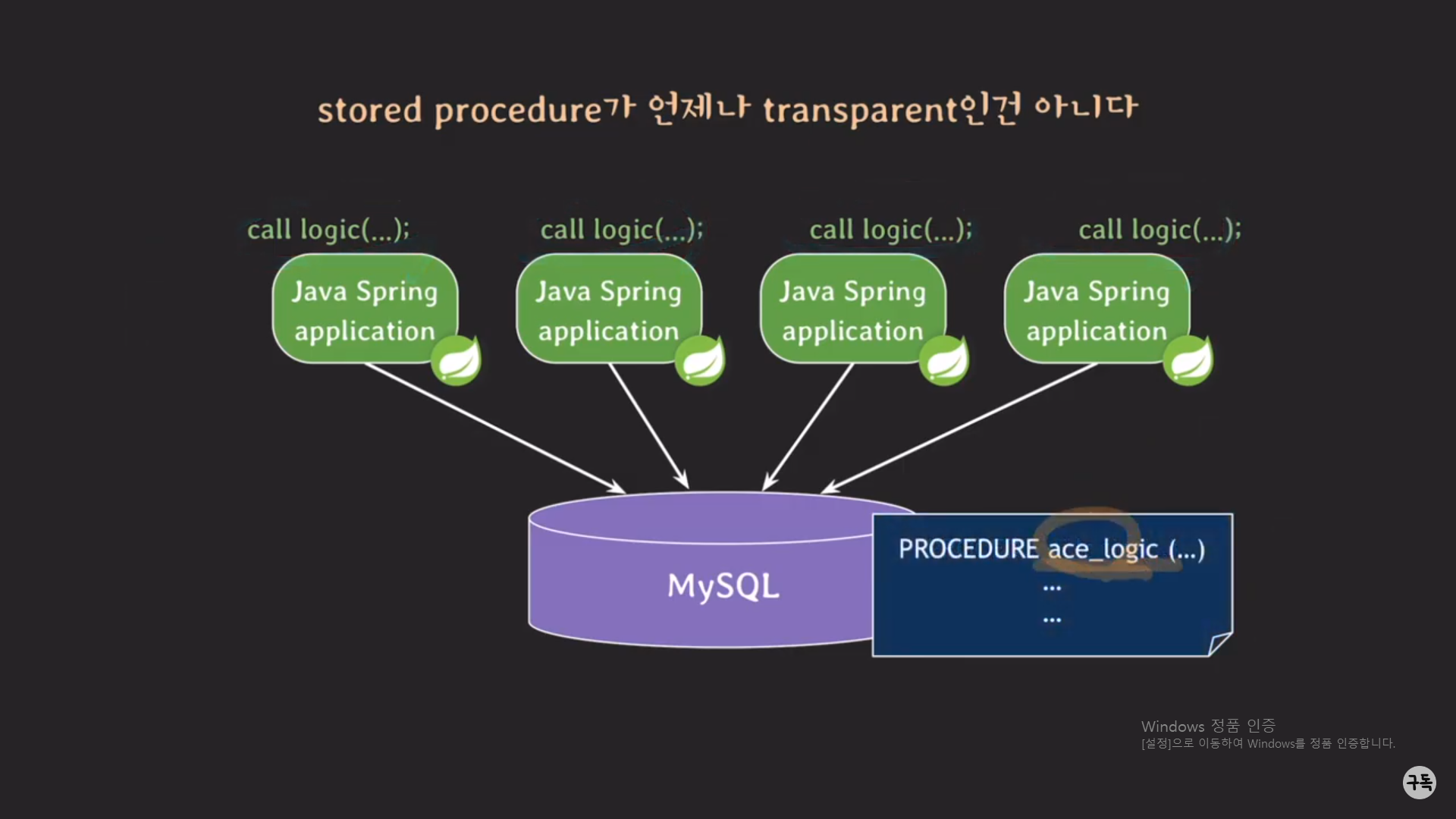
만약 비즈니스 로직인 담긴 procedure의 이름을 "logic"에서 "ace_logic"으로 바꿔 주고 싶을 때 어떻게 되는지를 보자.
MySQL 서버에 저장돼 있는 procedure의 이름만 "ace_logic"으로 바꾸면 되는 것이 아니라, Spring 서버에서 호출되고 있
는 procedure의 이름도 같이 바꿔 줘야 한다.
그런데 이 과정이 굉장히 번거롭다. 아래에서 자세히 살펴보자.
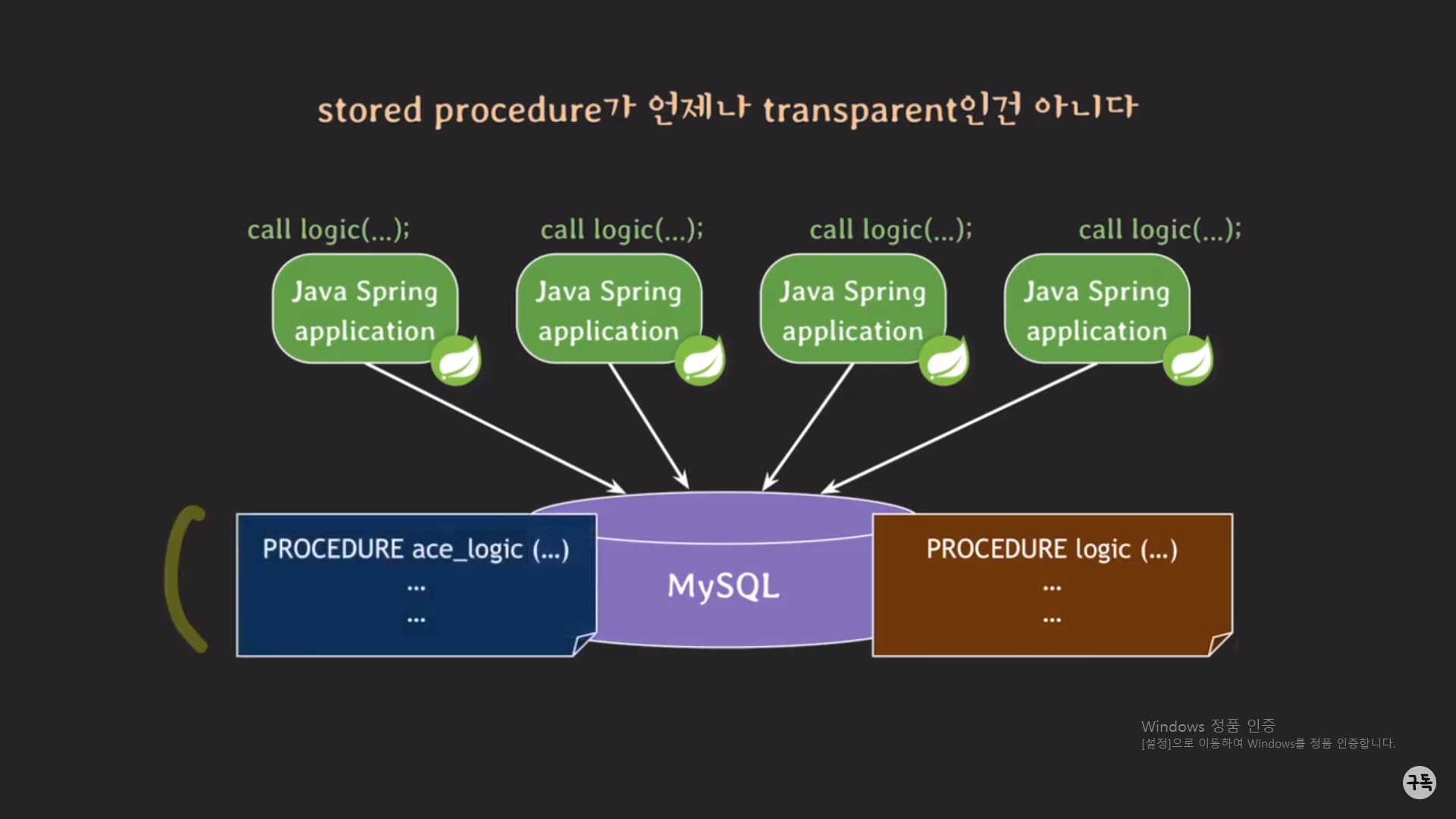
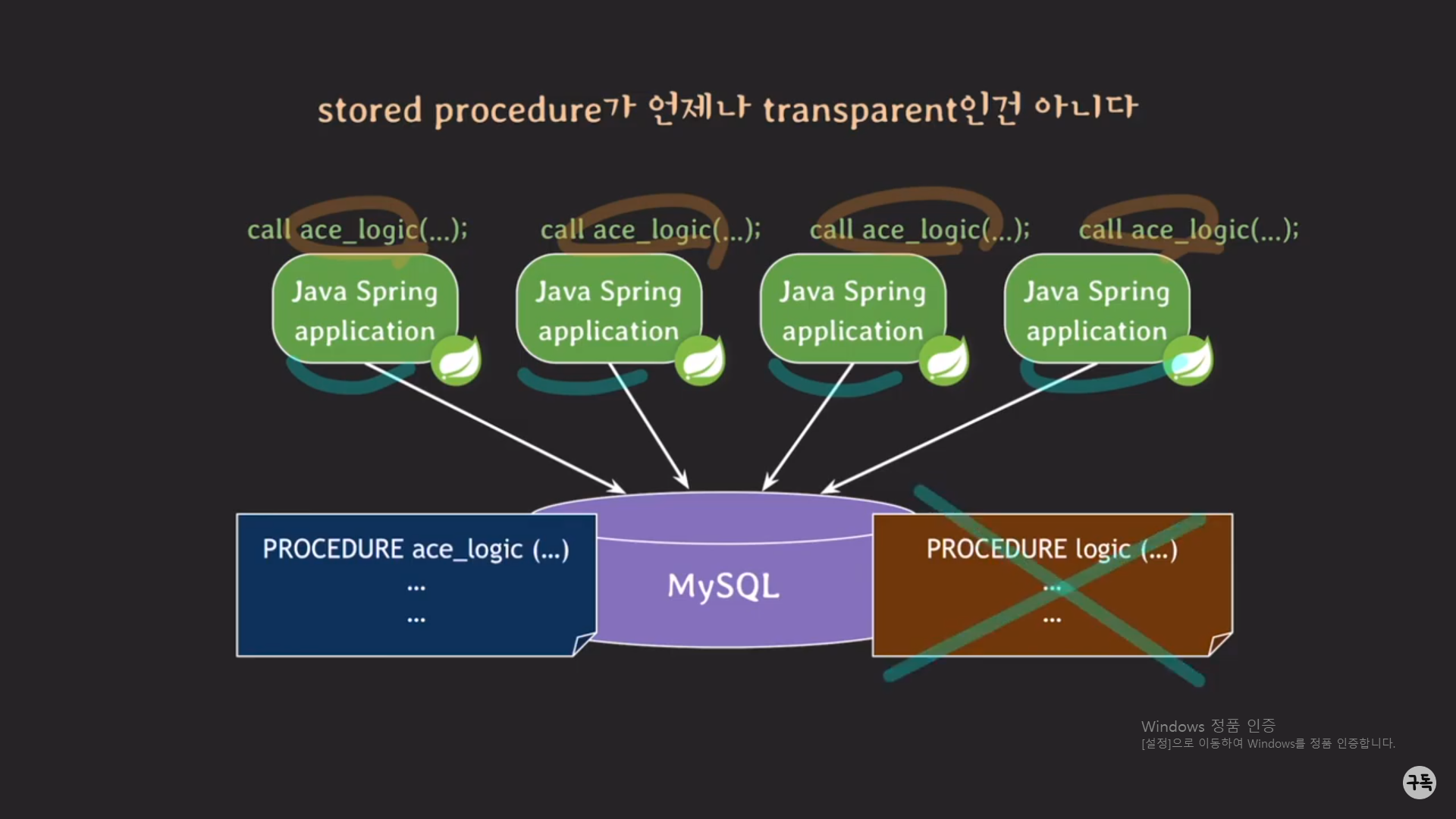
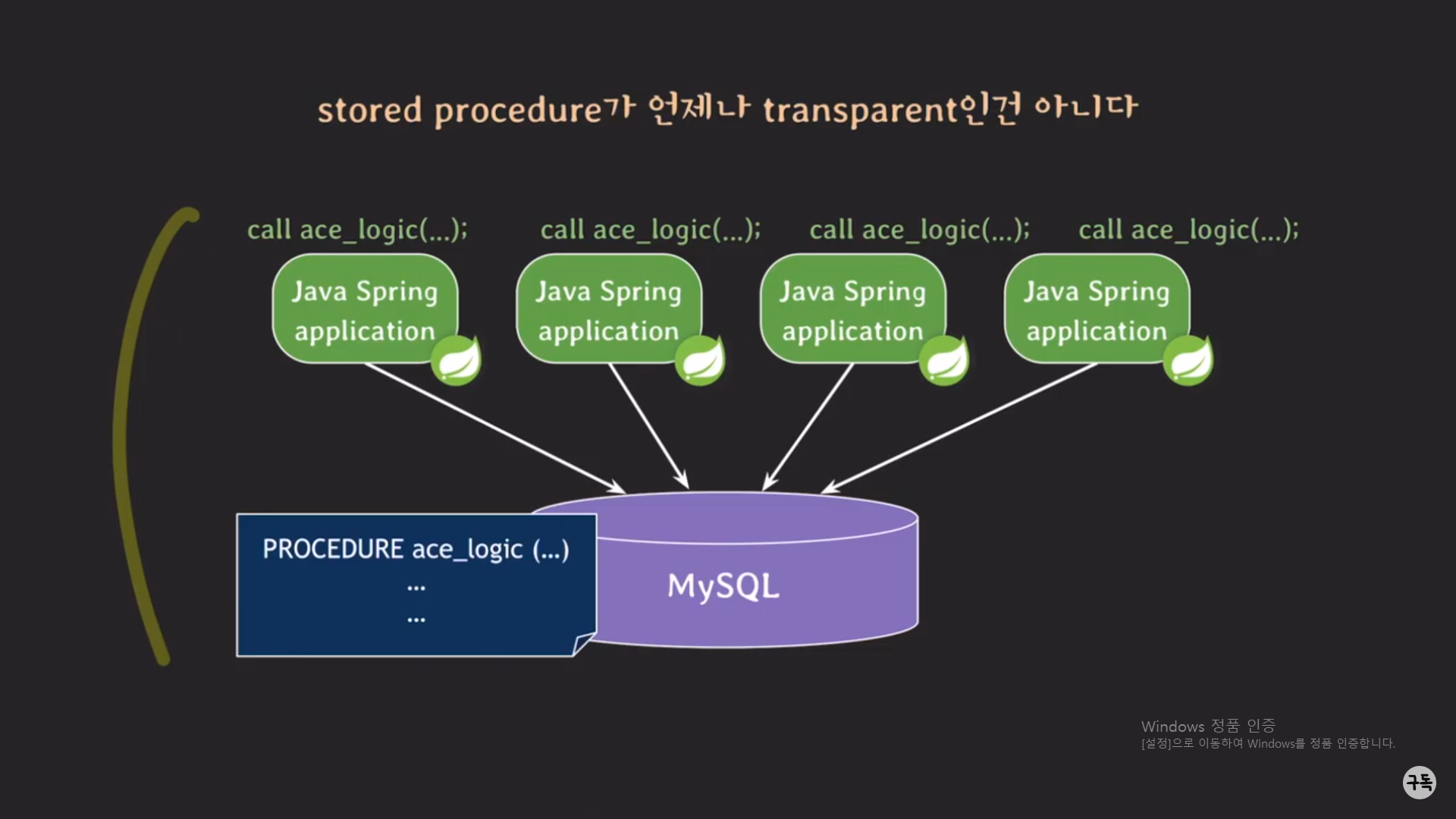
1. 먼저 DB에 ace_logic이라는 procedure를 등록을 시켜줘야 한다.
2.그 다음 서비스를 멈추고, Spring 서버의 call logic()부분을 새로운 procedure 이름인 ace_logic으로 바꾸고 다시 컴파일
및 빌드 후에 배포를 해준다.
3. 마지막으로 기존의 procedure logic()을 제거해준다.
-> 이렇듯이, stored procedure가 항상 trasparanet한 것이 아니다.
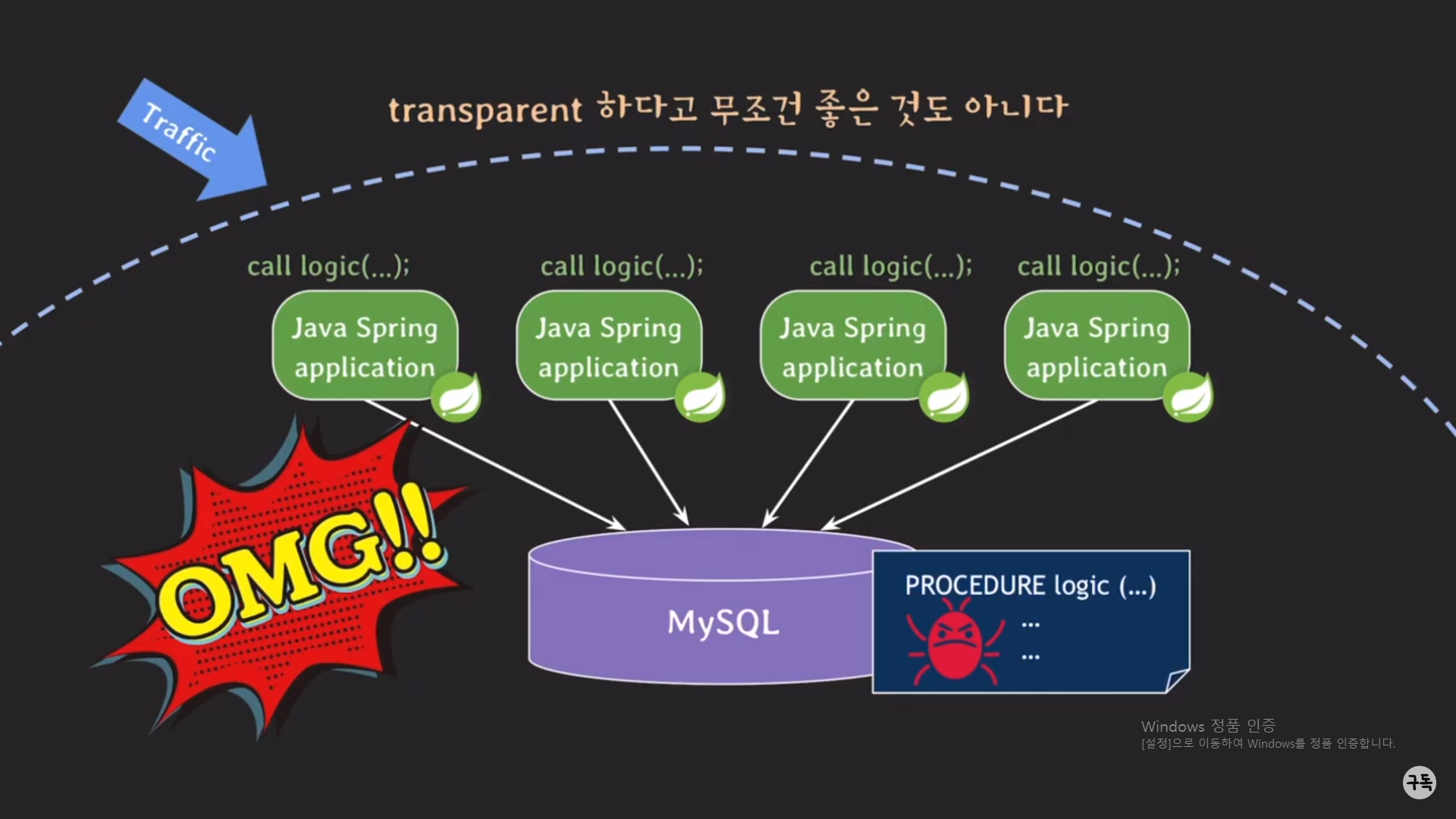
만약 procedure의 body를 바꾼다고 하였을 때에는, stored procedure은 일견 transparent할지도 모른다.
그러나, 그 변경한 코드에 버그가 있다면 어떻게 될까??
다시 이전 procedure로 roll back을 하더라도 버그가 있는 procedure를 사용하는 동안 클라이언트들의 Request에 대해 제
대로된 처리가 일어 나지 않았을 가능성이 매우 크다.
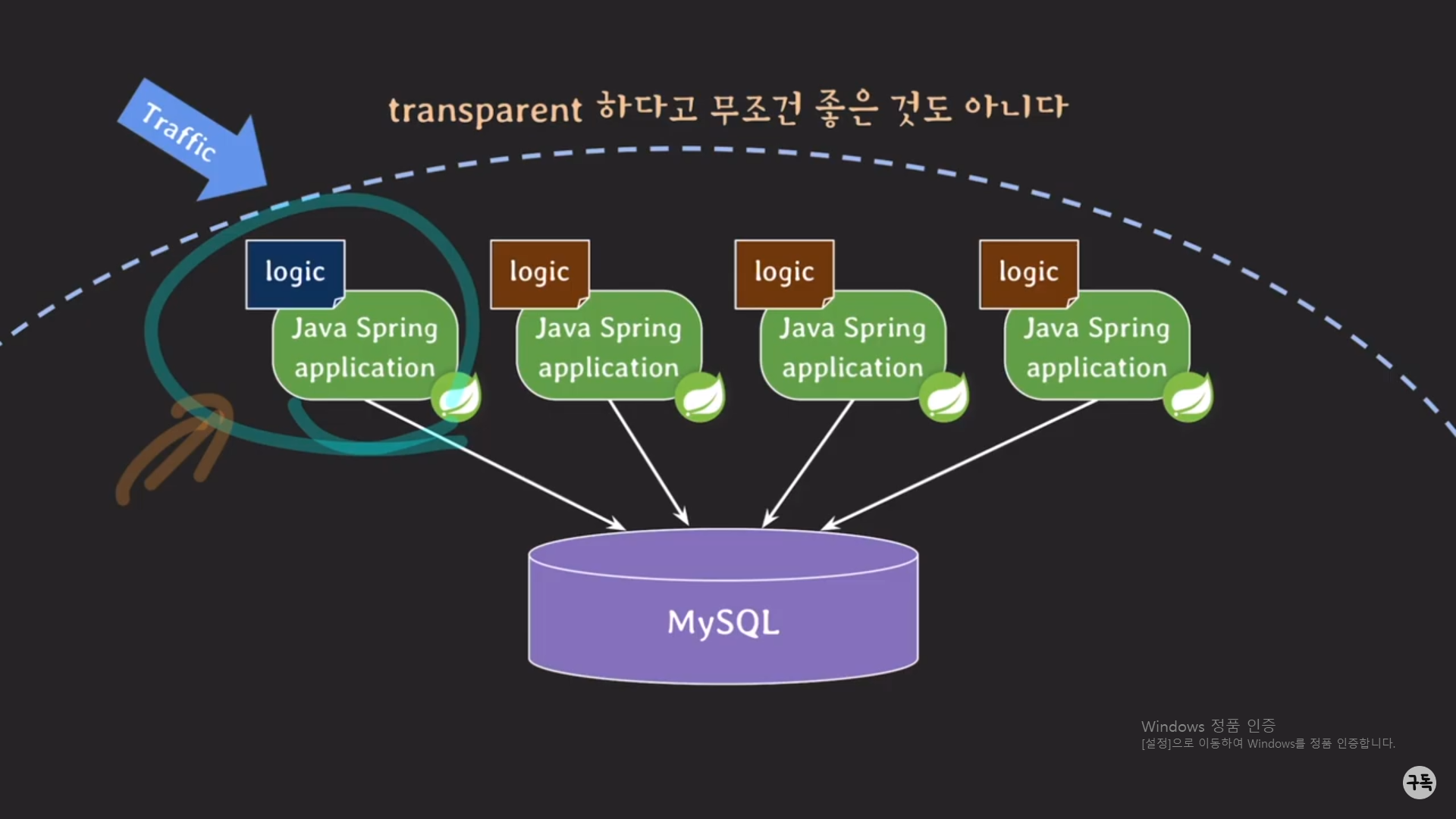
그럼 이번엔 procedure가 비즈니스 로직에서 사용되지 않고, 모든 비즈니스 로직이 Spring 서버에 코드로 올라 와 있는 상황을 가정해 보자.
이때는 번거롭기는 하지만, 순차적으로 Spring 서버의 코드를 변경을 해야 한다. ( 모든 Spring 서버를 동시에 변경을 하게
되면 그 동안에 클라이언트들이 서비스를 이용하지 못하기 때문이다.)
요즘에는 클라우드 서비스가 잘 되어있으므로, auto scaling이라는 옵션을 이용하여 서버의 증설이 쉬울 것이다.
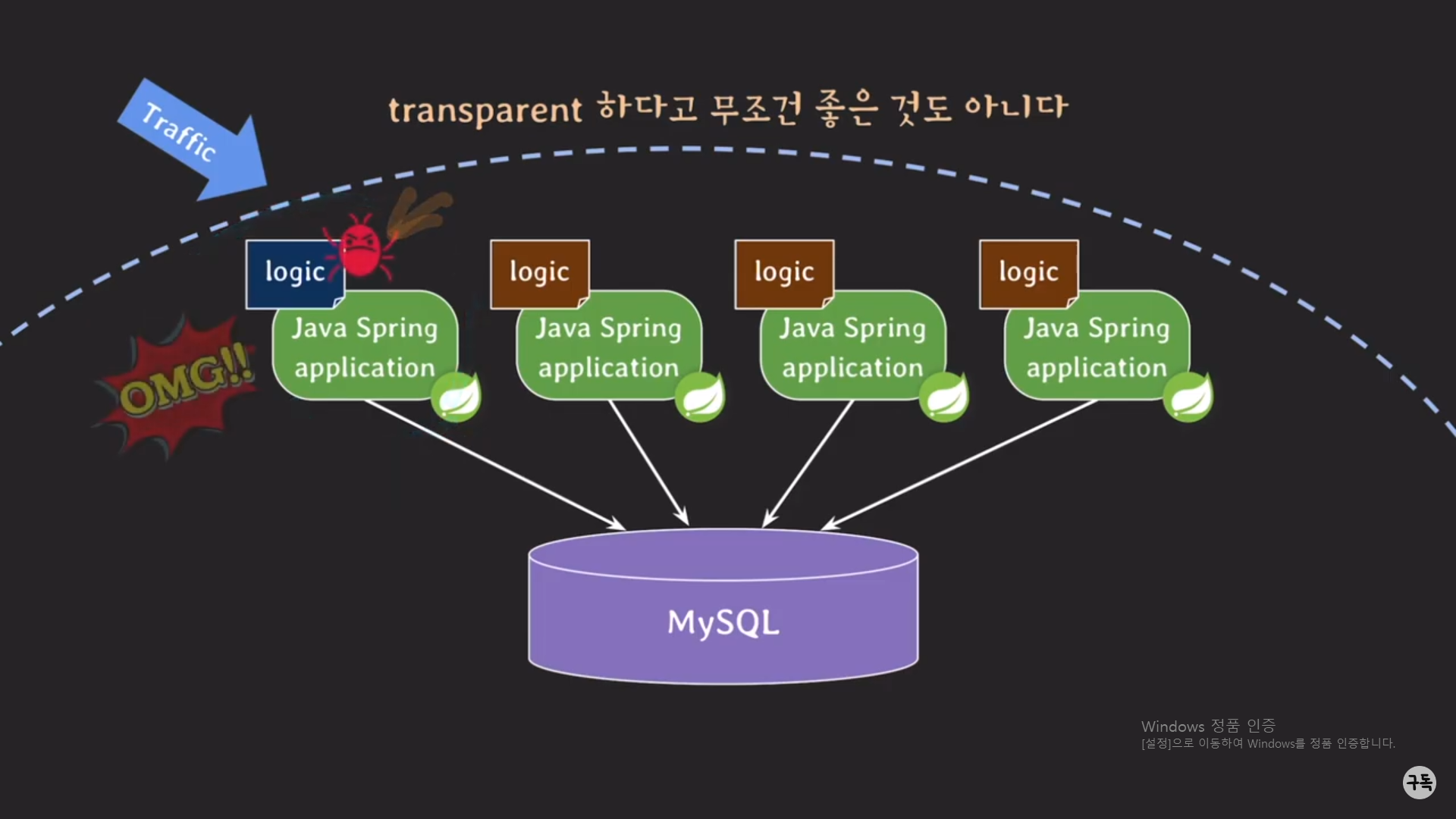
근데 이때, 변경된 코드에서 또 버그가 발생을 했다. 그래서 개발자가 허겁지겁 roll back을 하여 이전의 코드로 돌려놓았
다.
이때에도 잘못된 코드로 인해 클라이언트의 Request에 대해 잘못된 Response를 만들었을 가능성이 매우 크다.
하지만!!!!
procedure를 변경시켜서 버그가 발생됐을 때는, 모든 Spring 서버가 버그가 있는 그 procedure를 사용하기 때문에 모든 클
라이언트의 Request에 대해서 잘못된 Response가 발생을 하지만
이번 경우에는 클라이언트의 Request 중, 첫번째 Spring 서버에 트래픽을 보낸 Request에 대해서만 잘못된 Response가
만들어 지므로
잘못된 처리가 발생한 건수로만 보면, procedure를 사용했을 때가 훨씬 더 많다.
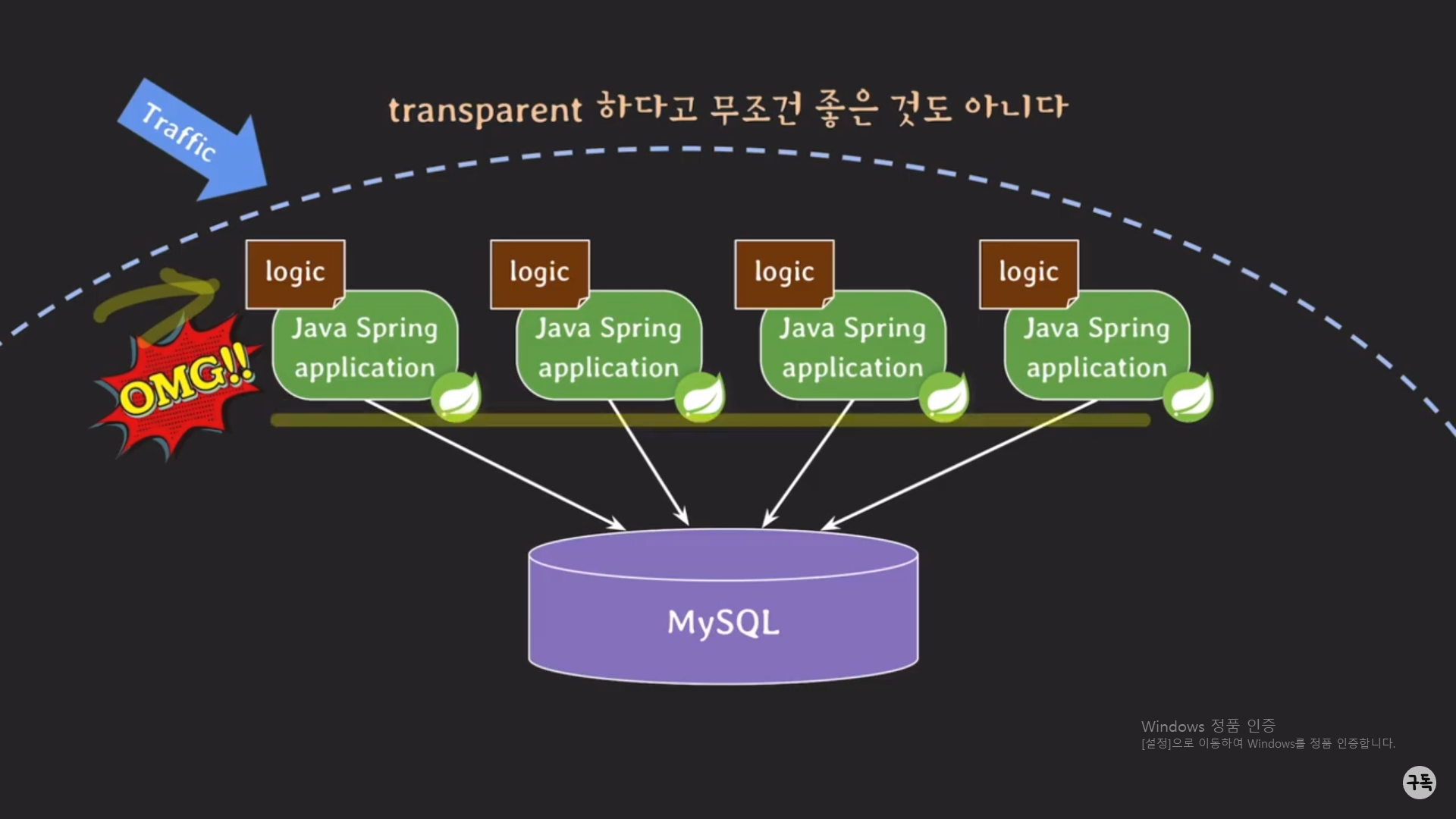
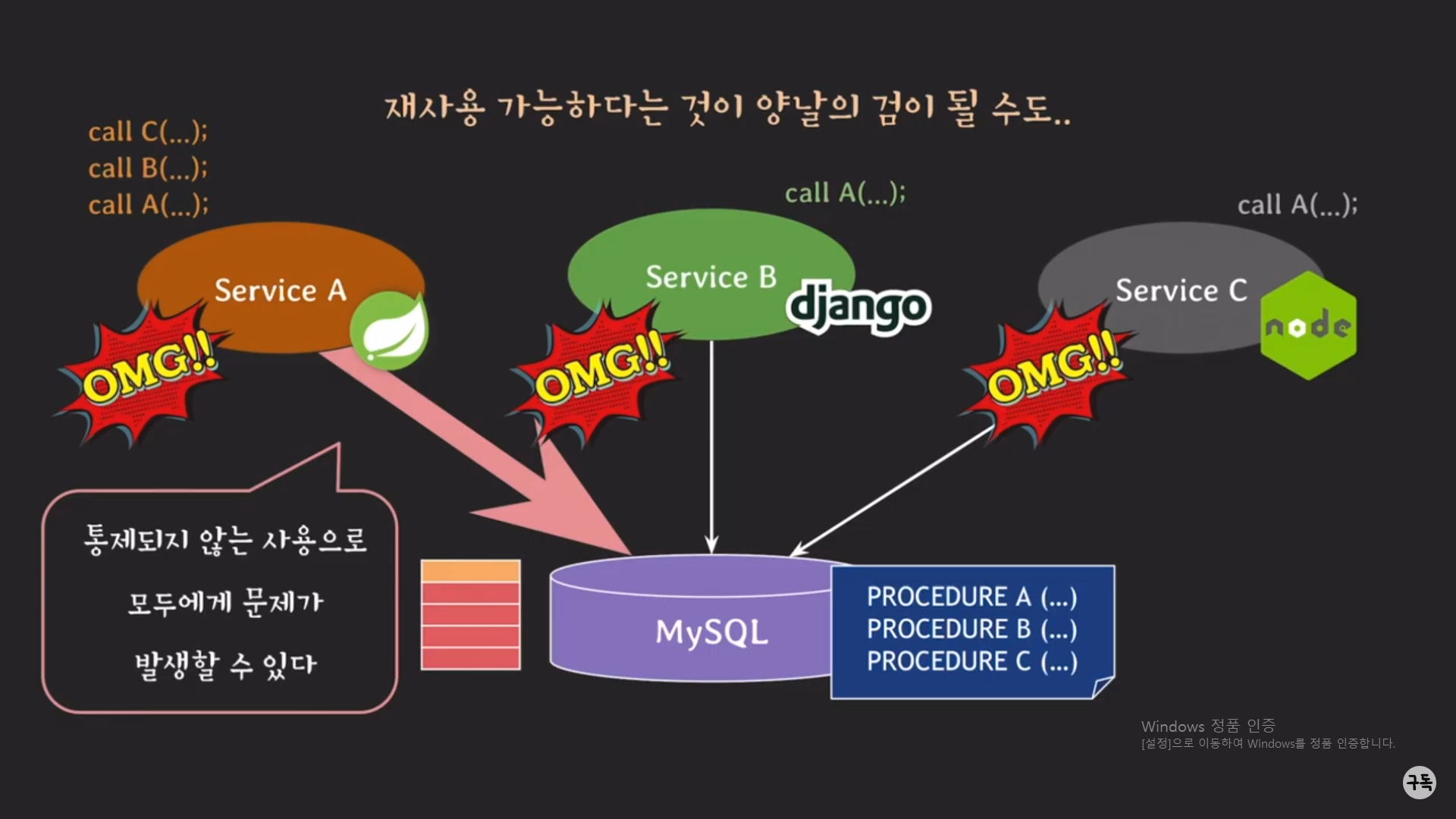
3대의 서버가 동시에 A라는 procedure를 호출하고 있다고 가정을 해 보자.
그런데 이때, Spring 서버에서 A procedure 이외에도 B,C procedure를 마구잡이로 호출한다고 가정을 해보자.
그럼 당연히 MySQL 서버에서는 Spring 서버에 의해서, 많은 procedure를 처리해야 되다 보니, CPU와 메모리에
과부하가 올것이며, 이는 3대의 서버에 정상적으로 응답을 해 주는 것이 어려워 질 것이다.
-> 이렇게 logic tier의 서버에서 procedure를 재사용한답시고 남발하게 되면, 정상적인 서비스가 어려워 진다.
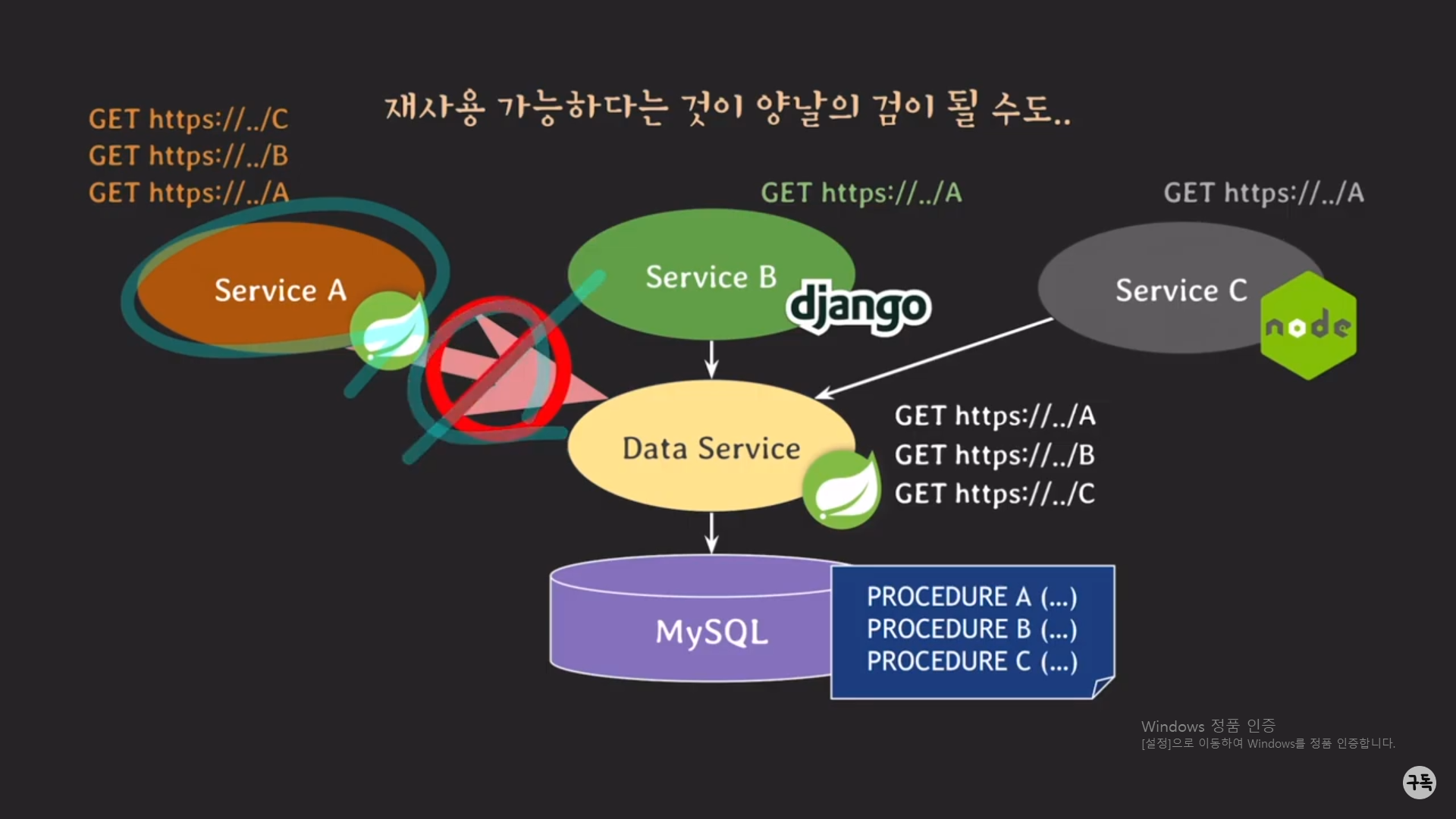
Solution : MySQL 서버 앞 단에 Data Service라는 징검다리를 만들어서, 이제는 3개의 logic tie 서버에서 call procedure의
형태로 직접 호출하는 것이 아닌, Data Service에서 제공하는 Rest API로 procedure를 호출하면 된다.
3대의 각 logic tier의 서버들은 API로 인해 간접 호출을 하게 되었다.
이게 무슨 말이냐면, 만약 Spring, Django, node js의 각 서버들이 API를 호출하면, 곧바로 procedure가 호출되는 것이 아니
라 Data Service에서 각 서버에 대해 공평하게 procedure를 호출해준다.
만약, Spring 서버에서 procedeure를 너무 많이 호출하려고 한다 싶으면, Data Service에서 Spring 서버의 procedure 호출
을 승인해주지 않는다.
그러므로, Spring 서버는 다운이 될 수도 있지만, Django, node js 서버는 서버가 다운되는 일이 생기지 않는다.
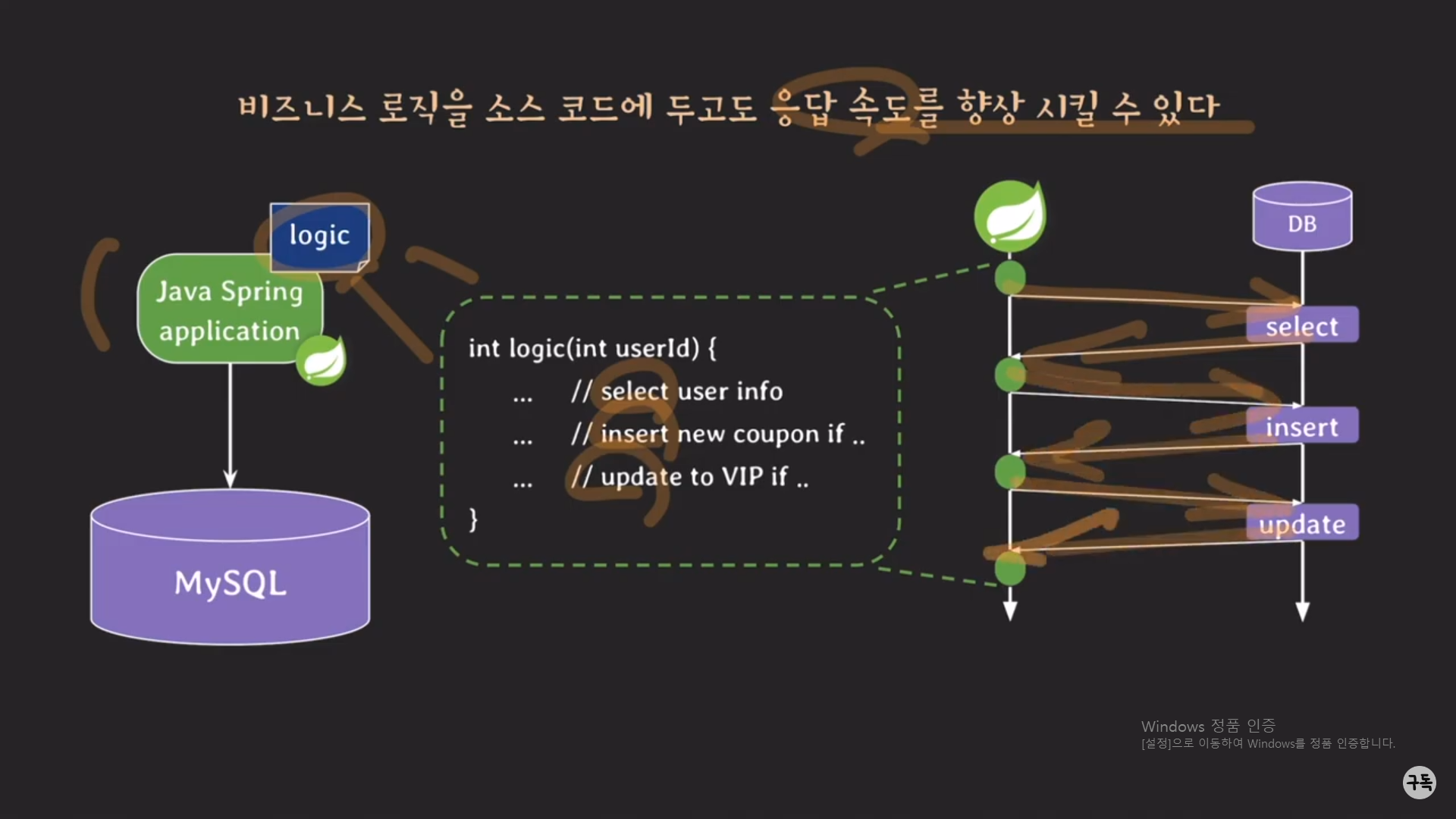
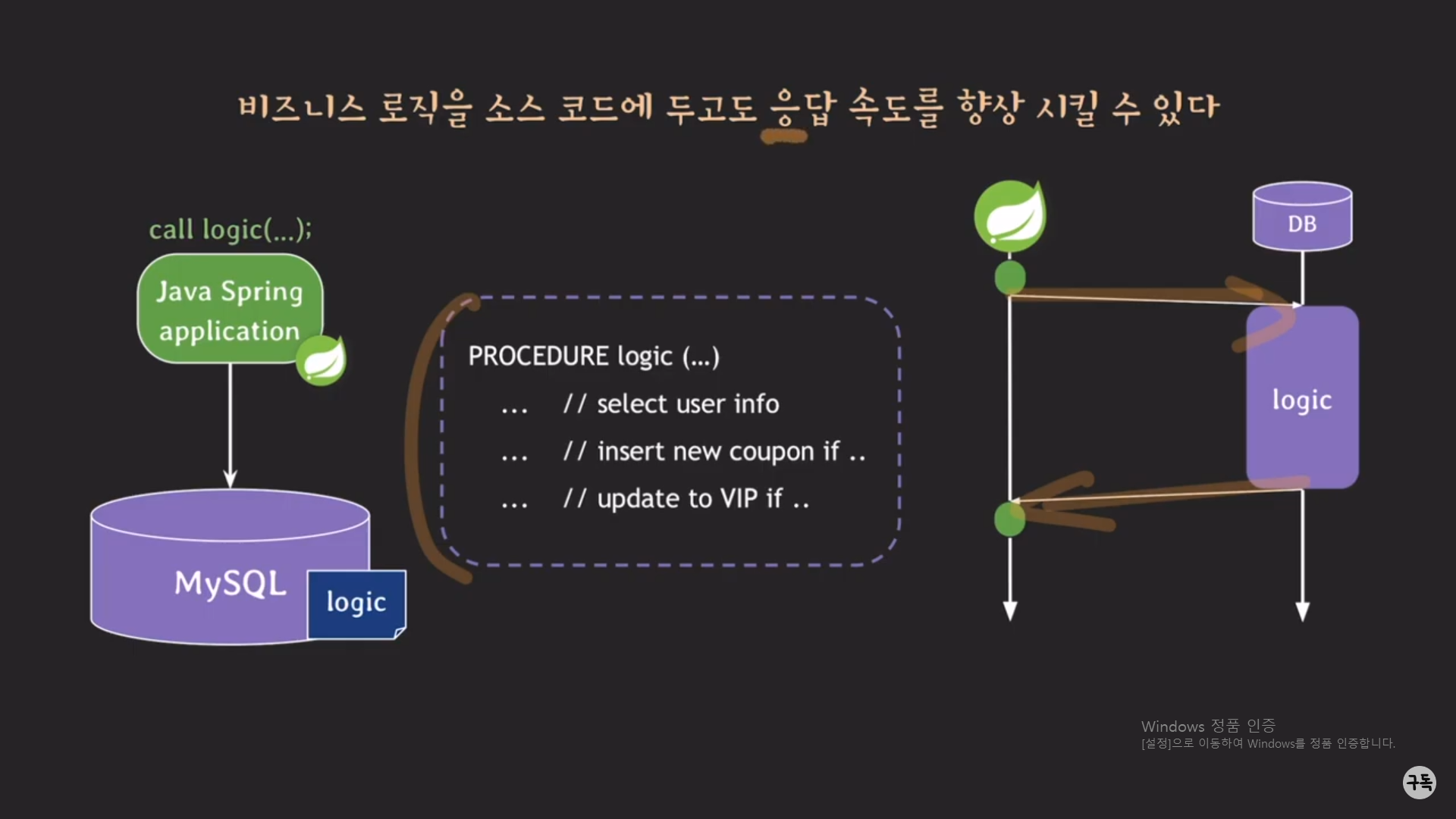
내가 생각하는 procedure의 가장 큰 장점은 응답 속도 향상에 있다.
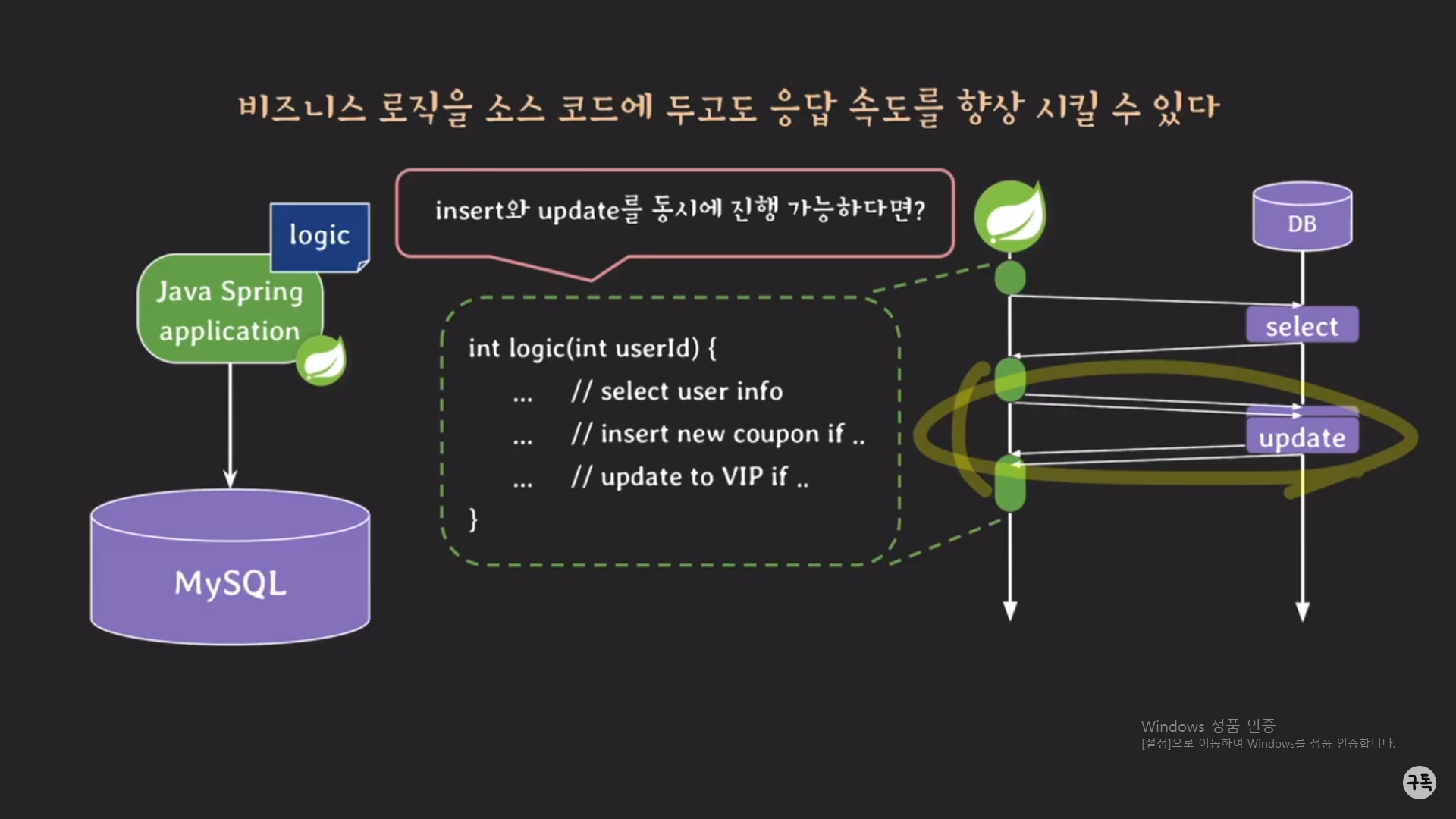
insert문과 update문을 순차적(절차 지향적)으로 실행할 필요가 없다면???
Thread pool이나 non-blocking 등을 이용하여 동시에 실행시키도록 하나로 묶어서 Traffic을 DB 서버에 보내어, 트래픽이
2번 반복해서 왔다 갔다 할 것을 아래처럼 1번의 왕복으로 끝낼 수가 있기에
비즈니스 로직에서 procedure 사용하지 않고도 응답 속도를 향상시킬 수가 있다. (아래 참조)
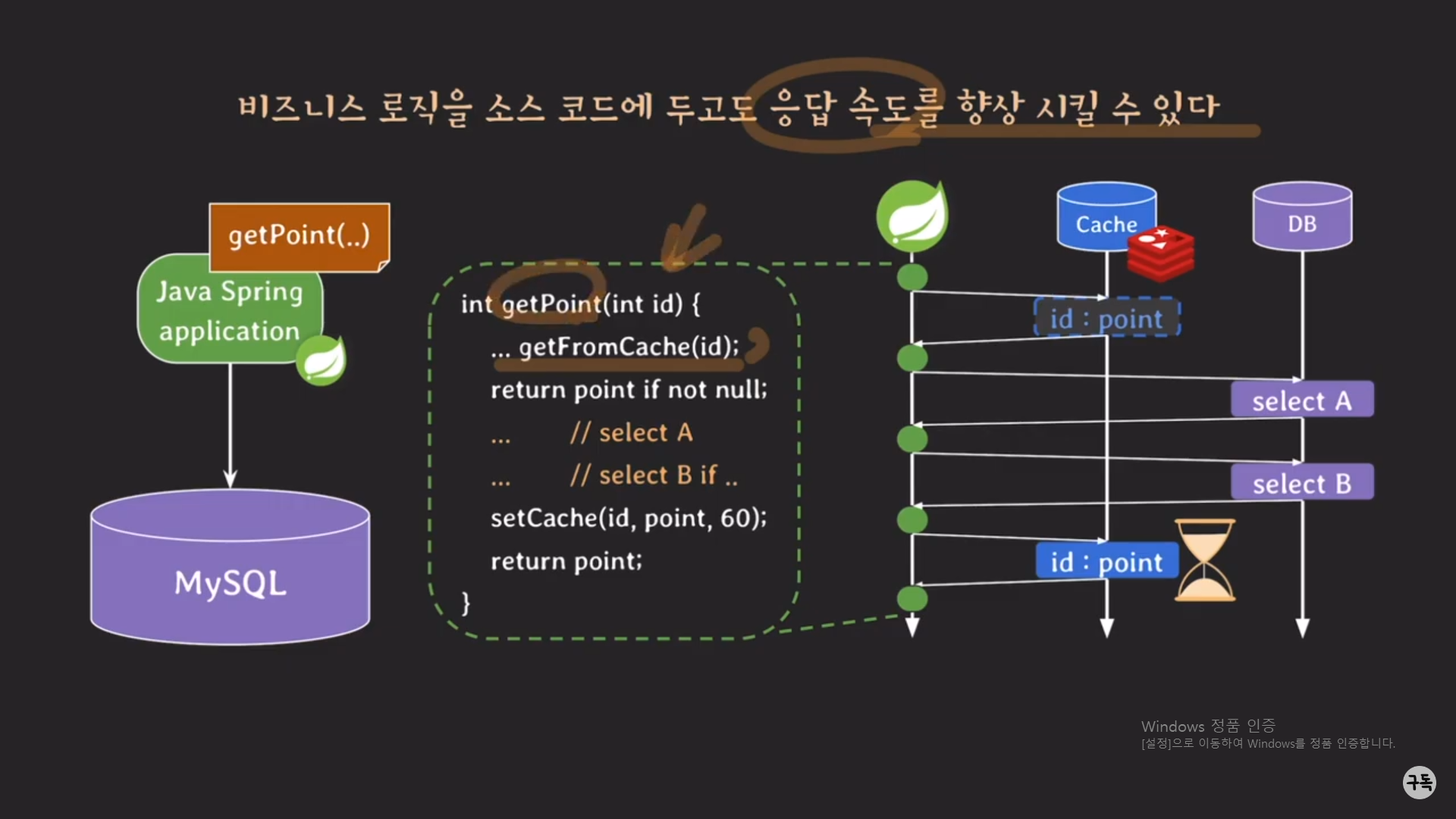
Spring 서버의 getPoint 메서드 안에 2개의 SELECT문이 있고, 이것을 순차적으로 실행을 해야만 한다고 가정을 해보자.
이때 어떻게 하면 응답 속도를 향상을 시킬 수가 있을까??
Cache용 DB(여기서는, Redis DB)를 이용하면 된다.
getFromCache(id)로 Cahe DB에 key값인 id에 매칭되는 point value가 저장돼 있는지 확인을 하고
만약 value가 저장돼 있지 않는다면(value==NULL)이라면, 2개의 SELECT문을 실행하기 위해 DB 서버에 할 수 없이 트래
픽을 보내야 한다.
그러나 응답 속도의 향상의 KEY는 이 이후에 있다.
2개의 SELECT문을 실행한 결과값을, 즉 point라는 value를 <key,value>=<id,point>의 형태로 Cache DB에 저장을 해 놓는
것이다. (참고로, Redis DB는 해쉬 테이블처럼 <Key, Vavlue>의 형태로 DB에 저장이 된다.)
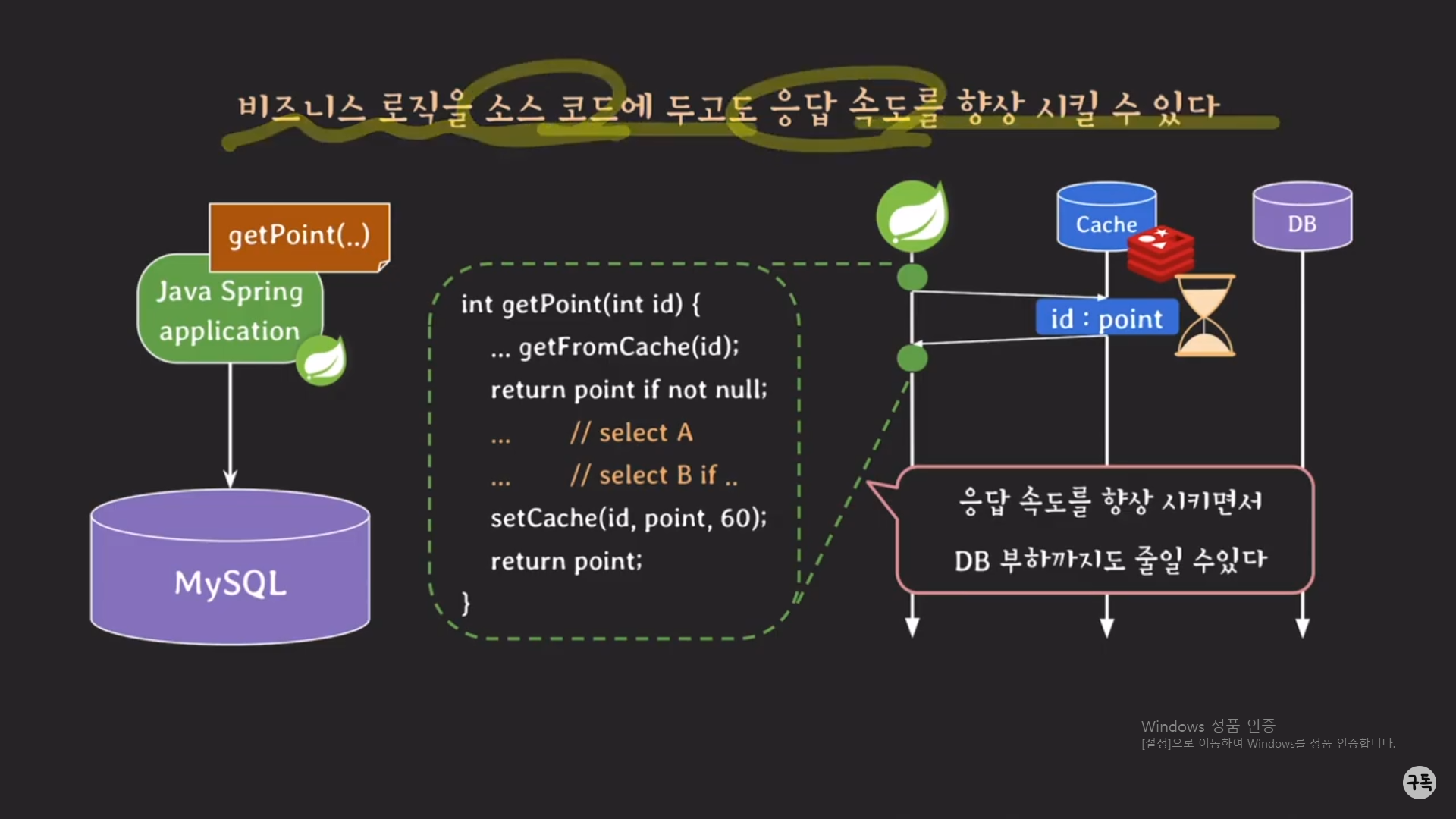
이렇게 Caching을 해 놓으면, 앞으로는 똑같은 id에 대해서 point 값을 가져와야 할 때, 2개의 SELECT문을 DB에서 실행을
하지 않아도 Cache DB에서 바로 point값을 가져올 수 있으므로,
응답 속도 향상뿐 아니라, DB 서버의 부하도 줄일 수가 있다.(왜냐면, SELECT문을 실행하지 않아도 되니깐!!!)

개발자가 DB에 직접적으로 접근을 못하게 막는닥 하더라도, procedure의 body 부분으 " return ~~; "의 형태로 민감한 정보
를 반환(출력)받을 수 있게 할 수가 있기에 완벽히 접근을 차단할 수는 없다.


'CS 과목(CS科目) > 데이터 베이스(データベース)' 카테고리의 다른 글
| 14.Transaction (0) | 2022.12.10 |
|---|---|
| 13. Trigger(부제 : 방아쇠를 함부로 땡기지는 말자 ㅋㅋ) (0) | 2022.12.09 |
| 11. stored Procedure PART 1 (0) | 2022.12.08 |
| 10. stored function (0) | 2022.12.08 |
| 9. SQL로 데이터 조회하기(SQLでデーター照会)PART 5 (2) | 2022.12.08 |



