Trigger
데이터 베이스에서 어떠 Event가 발생을 하였을 때, 자동적으로 실행되는 프로시저(procedure).
조금 더 자세히 설명을 하면,
데이터에 변경이 생겼을 때, 즉 DB에 INSERT, UPDATE, DELETE(select는 해당x)가 발생을 하였을 때, 이것
이 계기가 되어 자동적으로 실행되는 프로시저(procedure)를 trigger라고 한다.

users라는 테이블에서 nickname을 UPDATE하였을 때, UPDATE되기 이전의 {id,nickname}과 변경을 한 시간(until)을 자동적으로 user_log에 저장하는 trigger(procedure)를 만들어 보자. (아래와 같은 결과가 나와야 함)


1.[BEFORE] [UPDATE]
2.ON [users]
3.FOR [EACH ROW]
-> trigger가 실행되는 조건을 나타낸 것이다.
1. UPDATE문이 실행 되전 전(BEFORE)
2. users 테이블에 대한 UPDATE
3. UPDATE되는 각 tuple에 대해서 trigger 적용
OLD
1. Trigger가 UPDATE되기 이전(BEFOR)에 실행되는 경우
->UPDATE되기 전의 tuple.
2. Trigger의 촉발 조건이 DELETE인 경우
->DELETE된 tuple.
아래에서 위 예제의 실행 흐름을 살펴보자

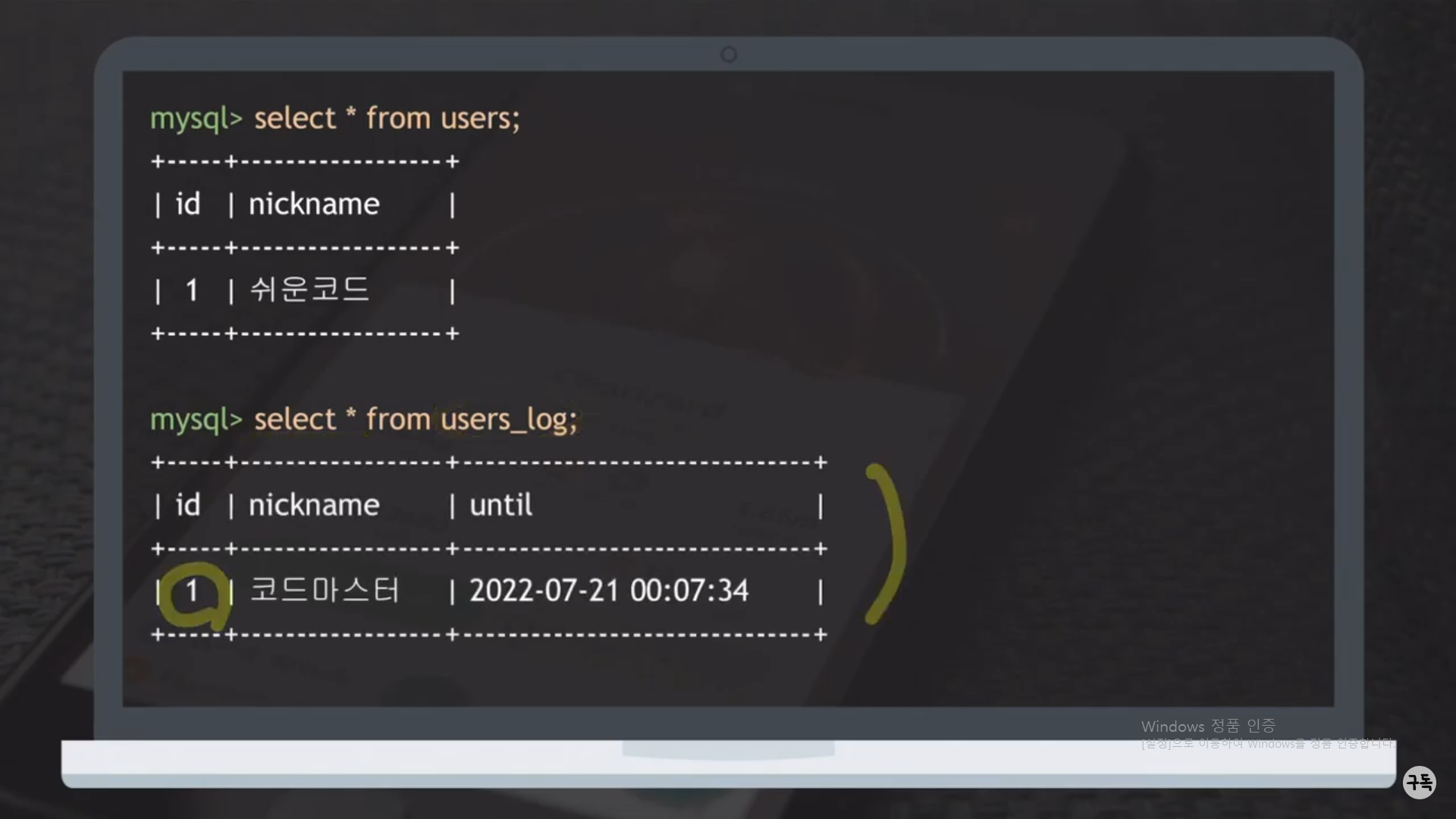
trigger가 실행이 되어서, users_log에 우리가 예상했던 데이터가 들어가 있는 것을 확인 가능하다.
-> 이렇게 데이터의 변경 이력, History 같은 것을 저장하고 싶을 때, trigger가 사용이 된다.

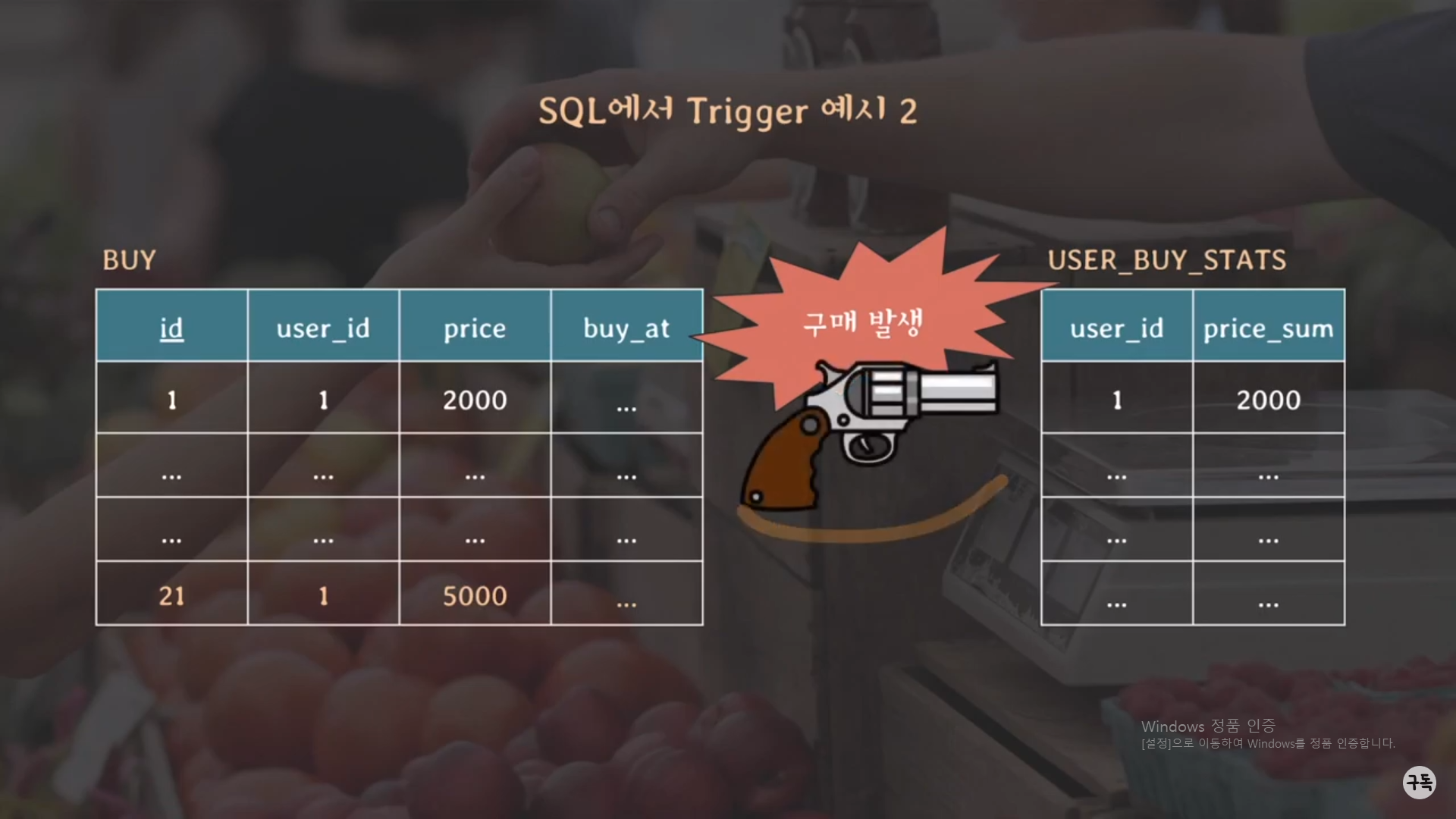

이제 이 trigger를 이용하여 보자

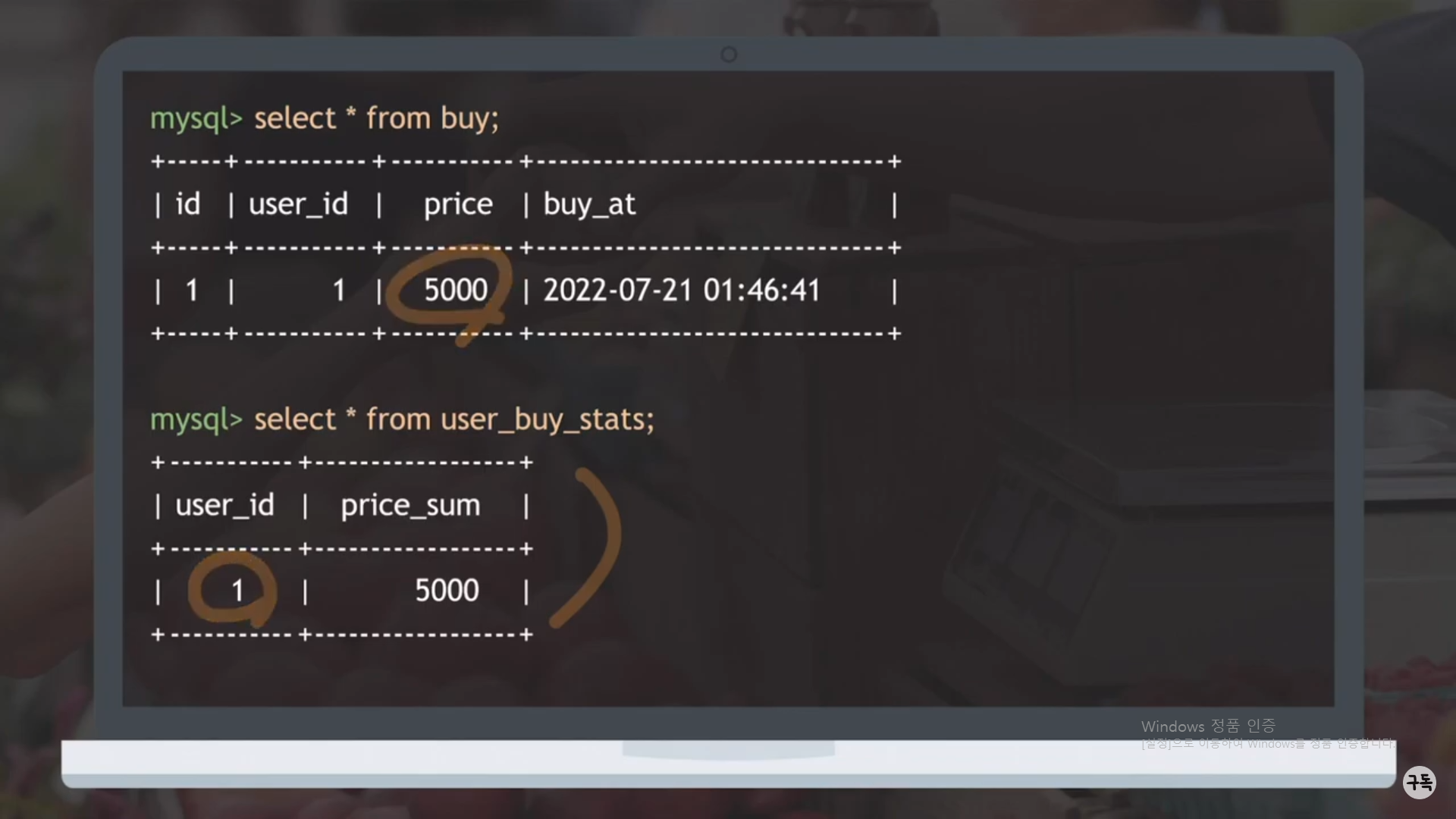


위와 같이 변화에 따른 통계값(평균값, 최대값, 최소값, 중앙값 등등)을 구하고 싶을 때, trigger는 요긴하게 쓰인다.

EACH ROW vs EACH STATEMENT

FOR EACH ROW의 경우, 해당 tuple이 5개이면 procedure 또한 5번 실행해야 하니 매우 비효율적이다.
아래에 나오는 FOR EACH STATEMENT를 사용하면, Procedure가 단 1번만 실행되게 할 수가 있다.(MySQL은 불가)


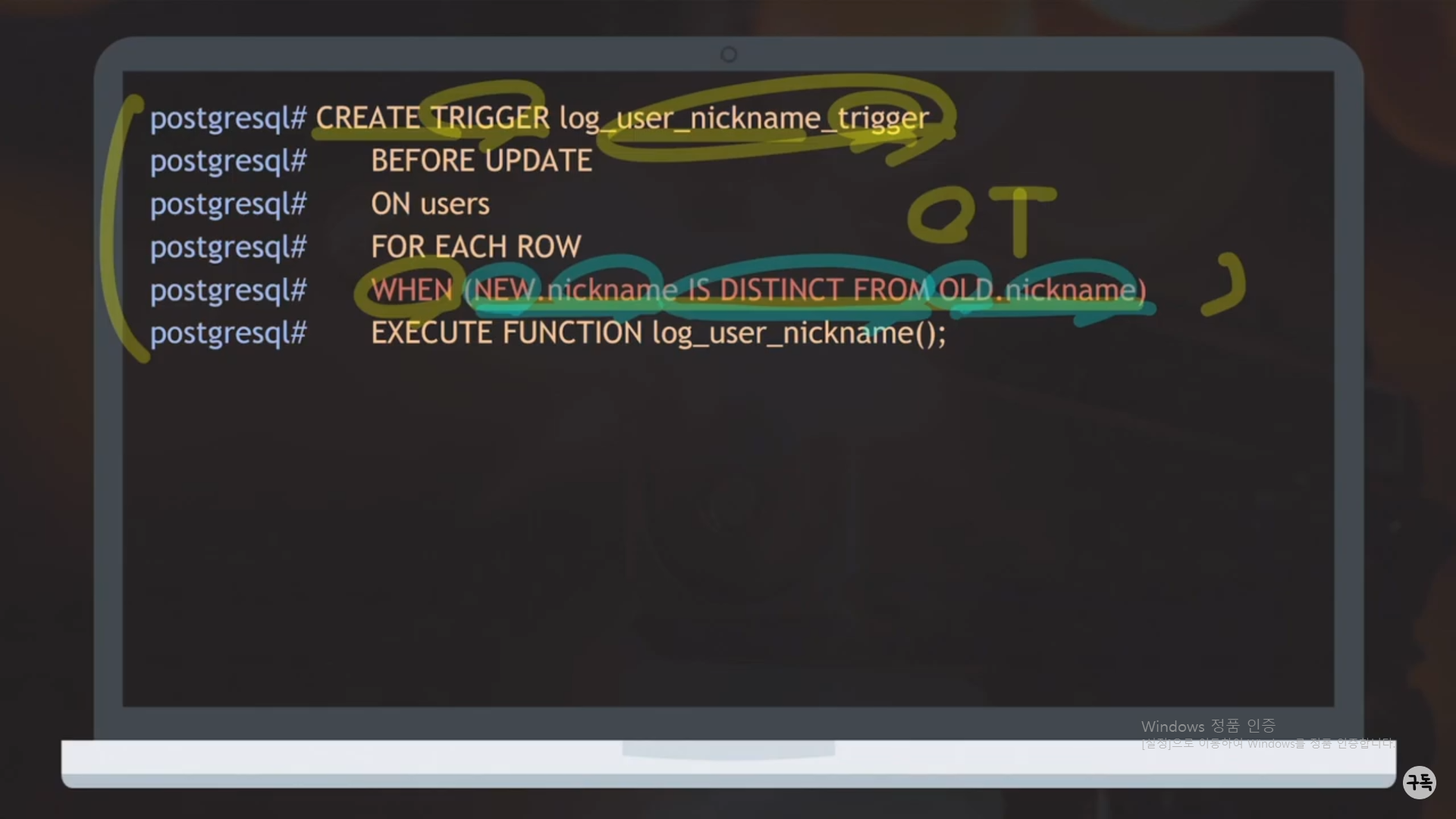
업데이트시킬 기존의 닉네임과 새로운 닉네임이 서로 다를 때에만 Trigger를 실행한다.
Trigger 사용 시 주의 사항

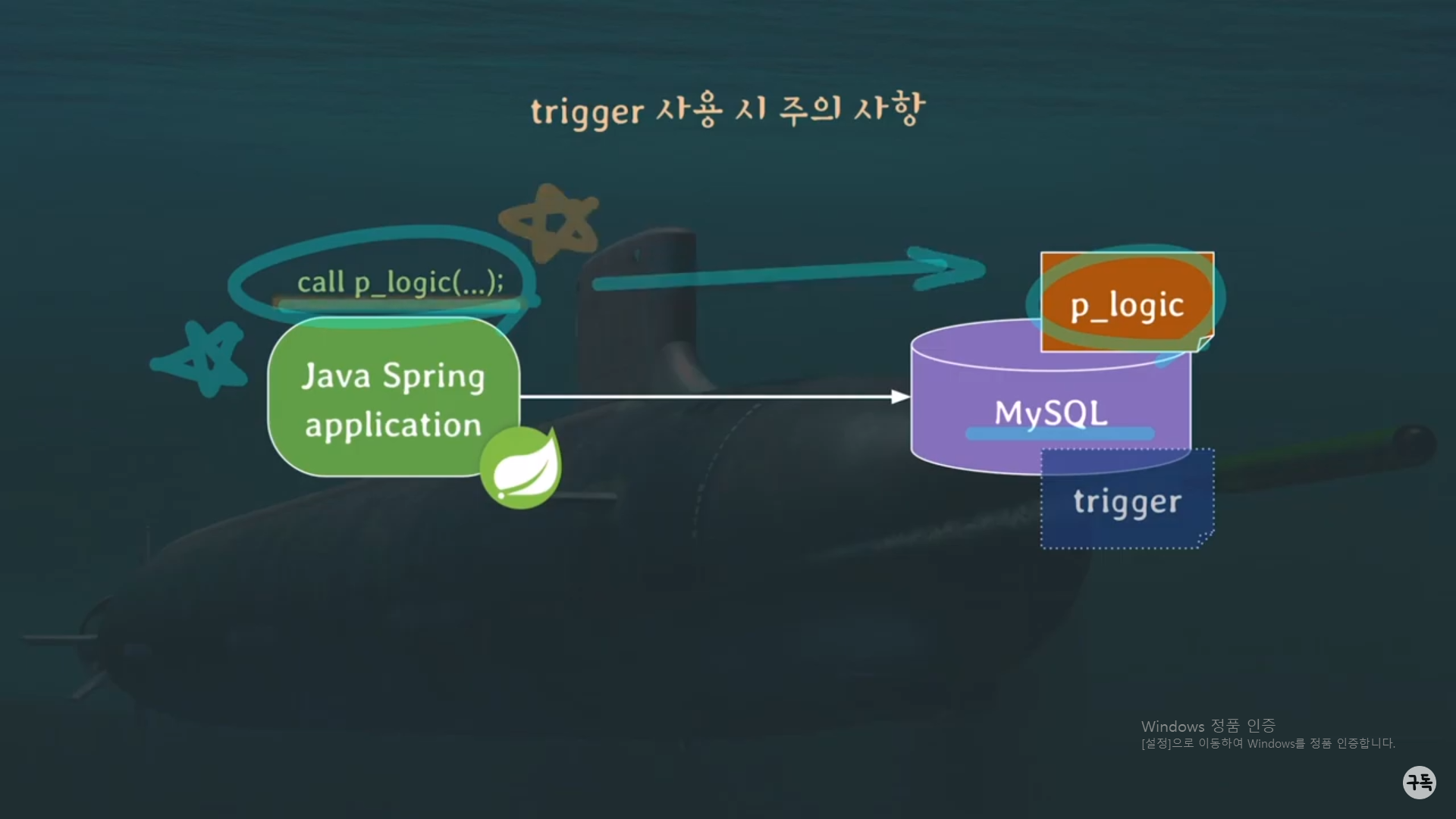
trigger는 RDBMS에 저장되어 DB상에 어떠한 Event(UPDATE,INSERT,DELET)가 발생할 때 동작을 한다.
Procedure vs Trigger
procedure은 Spring의 코드 상에 call procedure의 형태로 실존한다. 그렇기에 스프링 소스 코드를 보다가 call 부분을 발
견하면 그때 procedure를 까서 읽어 보면 된다.
그러나 trigger는 스프링 코드 상에서 명시적으로 호출되서 실행되는 것이 아니라, 위에서도 언급을 하였듯이 어떠한
event가 발생 시, 자동으로 마치 수면 아래에서 실행이 되는 것이기 때문에 불가시적으로 동작을 한다.
고로, 개발 관리 유지 보수가 힘들어 진다. 또한, 트리거가 또 다른 트리거를 호출하고, 그 트리거가 또또 다른 트리거를
호출하게 되면 그때부터는 ㄹㅇ 멘붕이 온다.
개인적인 생각으로는 trigger는 최후의 보루로서, 되도록 사용하지 않는 것이 좋다고 생각한다.

'CS 과목(CS科目) > 데이터 베이스(データベース)' 카테고리의 다른 글
| 15. concurrency control(Serial schedule, NonSerial schedule) - Part1 (1) | 2022.12.10 |
|---|---|
| 14.Transaction (0) | 2022.12.10 |
| 12. stored procedure PART 2 (0) | 2022.12.09 |
| 11. stored Procedure PART 1 (1) | 2022.12.08 |
| 10. stored function (0) | 2022.12.08 |



