[컴퓨터 비전과 딥러닝]에서 p407의 U-Net 코드를 이해하기 위해서는 먼저 Inception과 Xception 이 2 개의 모델을 먼저 이
해해야 된다.
(참조 사이트 : https://www.youtube.com/watch?v=3oFR7ajzAZs&t=1309s)

딥러닝 초창기에 이런 오해가 만연했다.
"신경망 Layer를 깊게 쌓으면 쌓을수록 성능이 더 좋아지지 않을까?"
위 질문은 일견 맞는 것 같다.
그러나 2가지의 문제를 일으킨다.
1. 과적합 문제(Overfitting)
2. 연산량 문제 : Update되는 weight값들이 많아 진다.
이러한 문제를 해결하고자 만들어 진 것이 Inception 기법이고, Inception 기법을 더 개선시킨 것이 바로 Xception이다.

깊은 층을 쌓는 대신, 여러 종류의 Convolution 연산의 Pooling 작업 등을 통하여 이미지의 [국부 구조 최적화], 즉 이미지의
상세 정보에 대해 최대한 상세한 정보(Local Info)를 추출하는 방법을 제시를 하였다.
( 위 이미지에 있는 3 문단의 영어는 아래와 같이 해석이 된다.
1. 이 결정은 필요보다는 편의에 근거한 것이었다
2. 또한, 풀링 연산은 현재의 합성곱 신경망의 성공에 중요한 역할을 한다는 것을 보여주므로, 각 단계마다 대안적인 병렬
풀링 경로를 추가하는 것이 추가적인 이점을 가져올 것으로 보입니다
3. 축소 용도로 사용되는 것 외에도, 그들은 또한 relu 활성화 함수를 사용하여 이중 용도로 활용 )

분홍색 박스 부분은 Inception 모델이다. 각 부분의 커널의 weight 값들은 모두 같다.
즉 신경망 층은 깊어 보이나 실제 업데이트되는 weight 값들은 적다.
위 그림에서 노란색 3개의 부분을 합한 값이 최종 출력값이 된다.
위 모델이 성공을 거두자 사람들이 이 모델이 왜 성능이 좋은지를 고민하기 시작을 했다.
그건 바로 1x1 크기의 커널이 input되는 특징 맵의 각 채널 [간]의 정보를 추출한 후에 채널 [내]의 특징을 추출하기 때문이
라고 생각을 하였다.
이러한 생각을 바탕으로 Inception 모델을 개선시킨 것이 바로 Xception 모델이다

주요 원리는 아래과 같다.
1. 먼저 1x1 필터로 채널 [간]의 정보를 담는 특징 맵을 생성
2. 생성된 1개의 특징 맵에 3x3 필터를 통해 이제서야 채널 [내]의, 즉 이미지 내의 특징을 추출해 낸다.
(위 그림 가운데 그림에 "ouput channels"이라는 부분이 있다. 이 길이는 채널의 크기를 나타내는 데, 이 채널의 크기는 1x1
필터의 개수에 의해 결정)
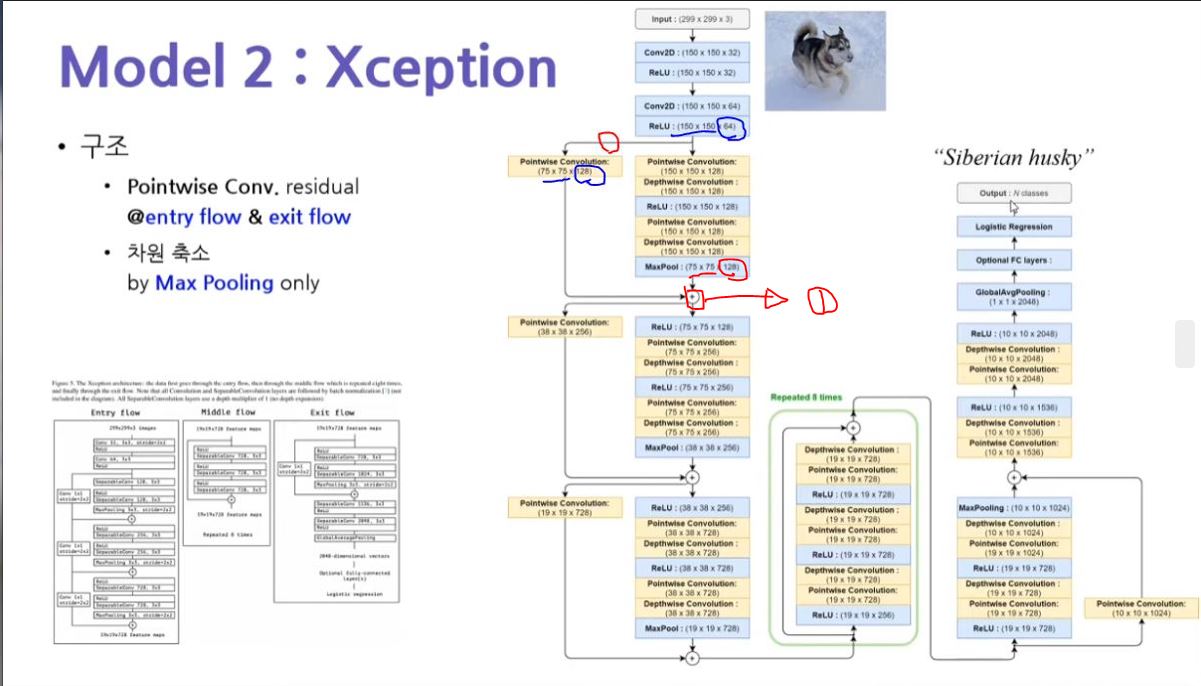
Entry Block은 Conventional CNN 모델이다.
여기서 Short Cut(지름길) 부분이 나오는 데, 이 부분은 자세한 설명이 필요하다.
(위 그림에서 빨간색 1번 부분이 Short Cut 연결 부분이다)
위 모델에서 왼쪽 부분은 entry flow(다운 샘플링 경로와 비슷한 개념)이다.
다운 샘플링은 Layer가 깊어 질수록 상세 정보를 잃어 버리게 된다.
이러한 이유로 만족스러운 성능을 얻지 못하게 된다. 그래서 나온 개념이 바로 Short Cut(지름길)이다.
핵심은 이전 Layer의 출력 특징맵을 다음 Layer의 출력 특징맵과 합함으로써 잃어 버린 상세 정보에 대한 보완 작업을 거
치는 것이다.
Q. 그럼 이전 Layer의 출력 특징맵을 그대~~로 다음 Layer의 출력 특징맵에 더하면 될까?
A. Nope~~!!! 우리는 이전 Layer의 특징맵을 다음 Layer의 출력 특징맵에 더할 수 있게 이전 Layer의 특징맵 크기
(150x150x64)를 다음Layer의 출력 특징맵(75x75x128)에 맞추어 줄 필요가 있다. 그 역할을 하는 것이 바로 빨간색으로 칠
한 부분의 경로에 있는 PointWise Convolution Block의 역할이다.
특징 맵의 크기를 변경하는 방법은 주로 보폭(Stride), 덧대기(Padding), 풀링(Pooling)을 통해서 한다.
여기에서는 보폭(Stride)를 이용해서 특징 맵의 크기를 변경한다(정확히는 덧대기와 보폭을 이용)
이전 Layer의 특징맵에 (padding="same", stride = 2, filter개수=128)의 Convolution을 적용하면 이전 Layer의 특징맵의
크기는 (150/2 x 150x2,128)로 변경된다.
이렇게 되면 다음 Layer의 출력 특징맵과 더해질 준비가 된 것이다.
(참고로 위 Xception 모델은 최종적으로는 회귀 모델을 사용하기에 오른쪽의 exit flow(업-샘플링 경로와 비슷한 개념)의
Global Avg Pooling의 결과로1x1x2048이 되어 사실상 2048 차원의 특징 벡터가 되어, Optional FC Layers의 Input 값이 되
고, 1개의 Hidden Layer에 해당하는 Logistic Regression을 통과하여 최종적으로 softmax의 activation으로 이루어진
Output Layer을 통해 최종적으로 이미지를 Siberian husky로 예측해 낸다.
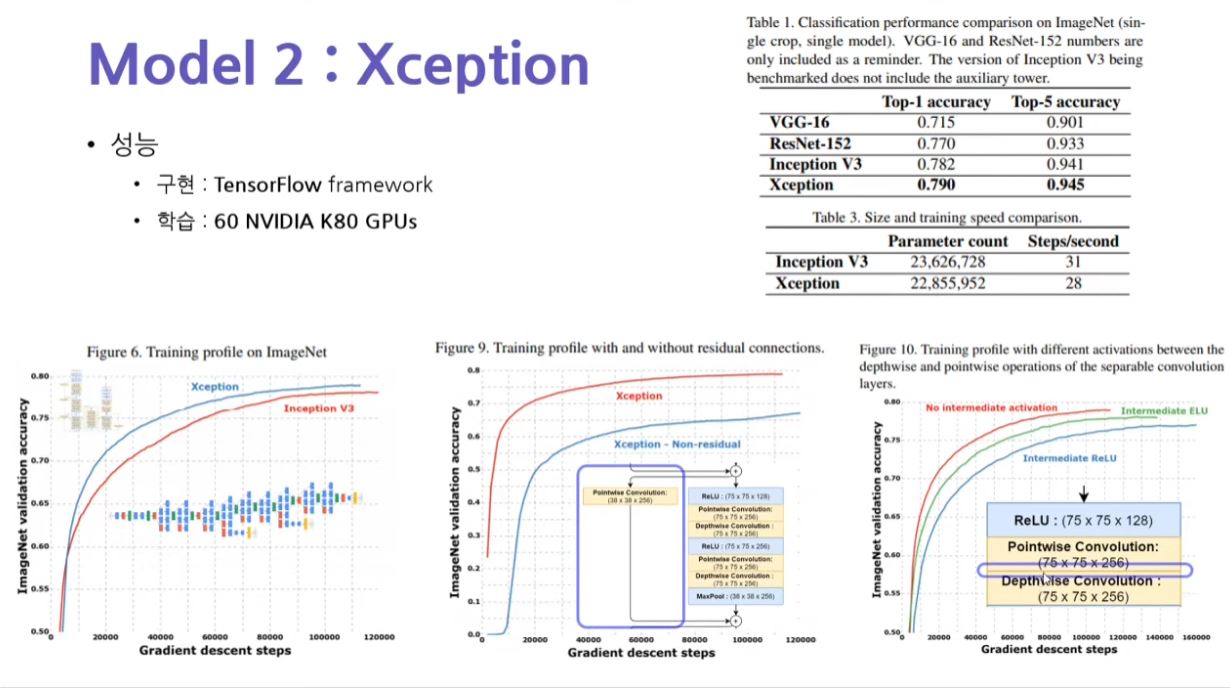
Figure 6의 의미
Inception 모델이 Gradient Step을 거칠수록, 즉 오차 역전파(Back-Propagation)에 의해 weight값이 변경되는 횟수가
Xception 모델과 같았을 때, 훨씬 더 정확도가 높았다는 의미이다.
이 말은 Xception의 학습율이 Inception 모델모다 훨씬 빠르다는 말로 귀결된다.
Figure 9의 의미
Xception - Non-residual(잔류 학습하지 않은 모델), 즉 PointWise Convolution으로 이전 Layer의 출력 특징 맵을 더하지 않
는 것과 Xception(잔류 학습한 모델), 즉 PointWise Convolution을 통해 잔류학습을 하여서 이전 Layer의 출력 특징 맵을 더
한 것과 성능 비교를 한 결과 잔류 학습을 한 Xception 모델의 성능이 더 좋았다는 것을 의미
Figure 10의 의미
위 그림에서 파란색으로 칠한 부분(Block의 중간 부분)에 ELU 활성화 함수를 넣었을 때의 모델, 넣지 않았을 때의 모델
그리고 relu 활성화 함수를 넣은 3가지 case의 모델의 성능을 비교한 것이다.
비교의 결과, Block의 중간에 아무런 활성화 함수를 넣지 않은 Xception 모델이 가장 성능이 좋다는 것을 의미한다.
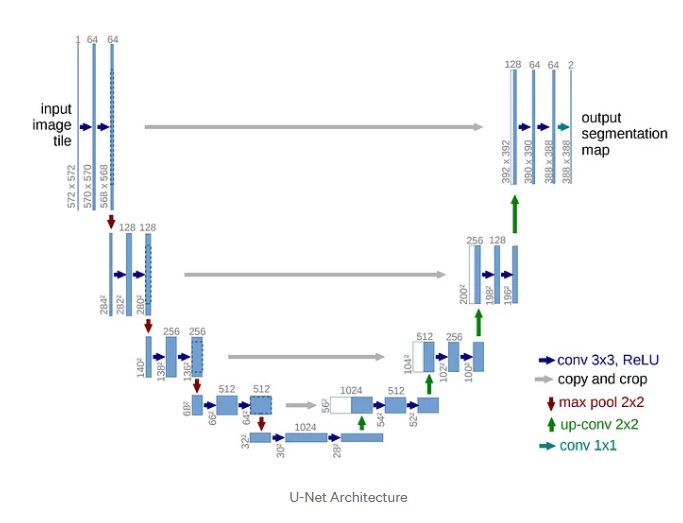
자, 이제 U-Net Xception Style의 신경망 구조를 이해할 준비를 마쳤다.
본격적으로 U-Net Xception Style 신경망을 코딩으로 알아 보자
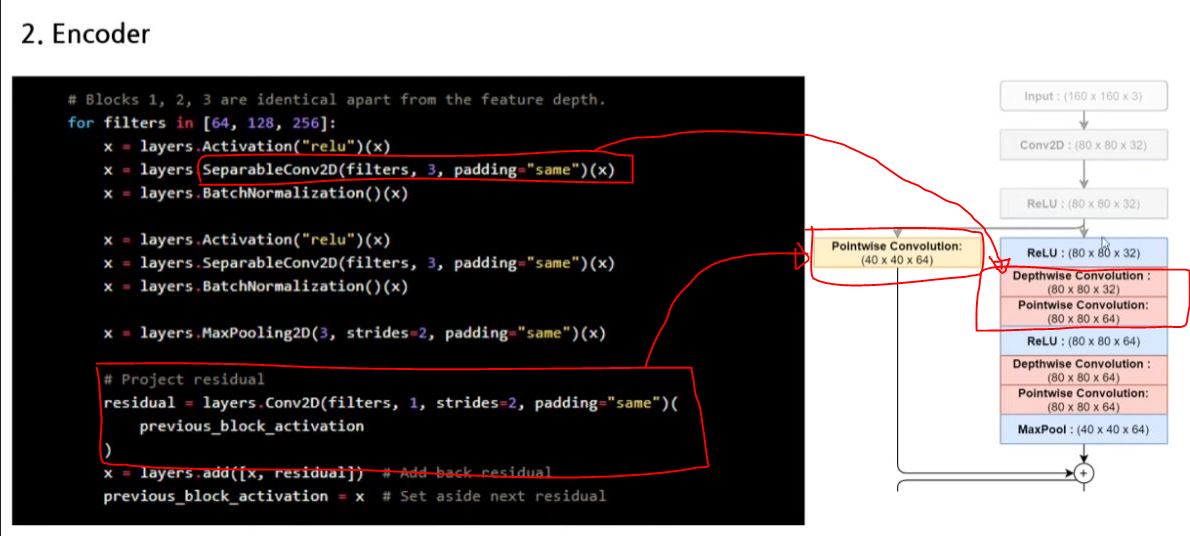
SeparableConv2D(filters,3,padding="same")(x)
-> 이 함수 안에 DepthWise Convolution과 PointWise Convolution, 이 2개가 수행이 된다.
residual = layers.Conv~~~~(previous_block_activation)
-> 이 부분은 잔차 연결(Skip Connection) 부분에 해당
'딥러닝(Deep Learning) > 컴퓨터 비전' 카테고리의 다른 글
| cv2.VideoCapture(0,cv.CAP_DSHOW)(Feat. [컴퓨터 비전과 딥러닝 중 P 418] (0) | 2024.04.17 |
|---|---|
| categorical_crossentropy VS sparse_categorical_crossentropy (0) | 2024.04.17 |
| Batch Normalization(Feat. 배치 정규화, U-Net, Inception) (0) | 2024.04.13 |
| padding,stride,pooling의 개념(Feat. Same Padding, Valid Padding) (0) | 2024.04.13 |
| 딥러닝(비전) 관련 survey 논문 목록 (0) | 2024.03.05 |
