
DB에 {x=10, y=20}이 있을 때, Transaction1,2이 동시에 실행됐을 때 일어나는 현상을 살펴보자.

두 개의 트랜잭션이 nonserial(비순차적)으로 동시에 실행되고 있는 상황이다.

트랜잭션1에 대해 commit이 일어나서, x는 10에서 80으로 영구적으로 저장이 되었다.
그런데, 트랜잭션2에 대해 어떠한 종류의 에러가 발생을 하여 roll back이 실행이 되었을 때를 생각을 해보자.
roll back의 실행에 의해, 트랜잭션2가 시작되기 이전의 상태, 즉 y=20으로 데이터를 복구하게 된다.

근데, DB에 저장된 x의 값 80은 read(x)에 얻은 10과 트랜잭션2 유효하지 않은 write(y)의 결과값인 70을 더하여서 나온
값이다. 이 유효하지 않은 Operation인 write(y)의 값을 읽어서 x=80을 DB에 저장을 하였기 때문에,
DB에 저장된 X=80도 유효하지 않은 값이 되버린다.
이렇게 트랜잭션1처럼 read(y) 부분에서, commit되지 않은 변화를 읽어 들여서 생기는 이상 현상을 dirty read 라고 한다.
또 다른 예제를 살펴 보자.

트랜잭션1,2를 동시에 실행을 시켰을 대, 어떤 현상이 나오는지를 알아 보자.

트랜잭션1,2가 동시에 nonserial(비순차적)하게 실행이 되고 있다.

트랜잭션1,2의 실행이 끝나고, 각각의 트랜잭션에 대해 commit까지 완료된 상황이다.
이때 트랜잭션1의 실행들을 살펴보자.
1번째로 읽은 x의 값은 10
2번째로 읽은 x의 값은 50이다.
이것은 트랜잭션의 속성인 isolation을 위배하는 것이다.
같은 트랜잭션 내에서 똑같은 데이터 x를 읽었는데 그 값이 서로 다르기 때문이다.
트랜잭션의 isolation이란
여러 트랜잭션이 동시에 실행이 되어도 마치 단독으로 실행되는 것처럼 동작해야 한다는 것을 의미한다.
고로, 트랜잭션1,2과 비록 동시에 실행이 되었어도, 트랜잭션1이 단독으로 동작한 것처럼 되어야 하니깐
읽어들인 2번의 x값은 모두 같아야 한다.
트랜잭션1과 같이 똑같은 값을 읽었는데도 그 값이 서로 다른 현상을 Non-repeatable read 또는 Fuzzy read라고 부른다.
또 다른 예제를 살펴 보자.

트랜잭션1,2를 동시에 실행시켜보자.

write(t2.v=10)에 의해 DB의 tuple2의 상태가 위의 그림과 같이 변경이 될 것이다.

이 예제의 결과도 트랜잭션의 isolation 관점에서 봤을 때 이상한 현상이다.
같은 트랜잭션 내에서 같은 조건으로 데이터를 읽었는데, 첫번째 read에서는 t1이 읽히고, 두번째 read에서는 t1과 더불어
t2까지도 읽혀 버린다.
이와 같이 같은 트랜잭션에서 똑같은 조건에서 read를 하였을 때, 없었던 데이터가 읽히는 경우를 phantom read 라고 한
다.
위에서 dirty read, non-repeatable read 그리고 phantom read라는 현상에 대해 알아 보았다.
이러한 현상은 되도록이면 안 일어나게 하는 것이 best이다.
그러나 이런 이상한 현상들을 일어나지 않게 만들 수는 있지만, 그러면 제약 사항이 많아져서 동시 처리 가능한 트랜잭션
수가 적어져서 결국 DB의 전체 처리량(throughput)이 하락하게 된다.
위와 같은 문제점을 해결하고자 나온 아이디어가 바로 isolation level이다.
isolation level
일부의 이상한 현상은 허용하는 몇 가지 level을 만들어서 사용자(개발자)가 필요에 따라서 적절하게 선택할 수 있ㄷ록 한 것.

isolation level이 아래로 갈수록 이상한 현상이 잘 일어나지 않는 반면, 그만큼 트랜잭션의 동시 처리량은 줄어 든다.
특히, Serializable level은 dirty read, non-repeatable read, phantom read 이 3가지 이상한 현상 뿐 아니라, 그 이외의 어떠한 이상한 현상도 일어나지 않는다.(그러나 동시 처리량이 매우 적다.)

개발자들은 isolation level을 통해 전체 처리량(throughput)과 데이터 일관성 사이에서 어느 정도 거래(trade)를 할 수 있다.
참고로, 위의 isolation level은 표준SQL의 내용이다.
그러나 이 isolation level에 대해서 마이크로스프에서 아래와 같은 반박 논문을 냈다.

그러면, 이 논문에서 말하는 3가지 이상한 현상외의 또 다른 이상한 현상이 무엇이 있는지 아래에서 살펴보자.

트랜잭션1,2,를 동시에 실행을 시켜보자.

트랜잭션1의 write()에 의해 DB의 X가 10으로 변경됨.

트랜잭션2의 write()에 의해 DB의 X가 100으로 변경됨.

트랜잭션 1에서 abort가 발생을 하게 되면, 트랜잭션 1이 시작되기 이전의 상태 즉, x가 0으로 복구된다.
그런데 이렇게 되면 트랜잭션 2에서 write한 100이라는 값이 사라져 버린다.
이렇게 되는 게 싫어서 abort를 실행시키지 않았는데, 그 다음의 트랜잭션2 에서 operation 에러가 나서 abort가 발생한 경
우 roll back이 실행되어 트랜잭션 2가 시작되기 이전의 상태인 x = 10인 상태로 복구가 된다.
그러나 x = 10은 트랜잭션 1의 유효하지 않은 operation( write(x=10) )에 의한 값이기에 x=10로 roll back이 돼서는 안된다.
이렇게, 2개 이상의 트랜잭션에서 write를 실행하다 roll back이 실행이 됐을 때 생기는 이상한 현상을 dirty write라고 한
다.
roll back 시 정상적인 recovery는 매우 중요하기 때문에 모든 isolation level에서 dirty write를 허용하면 안된다.
또 다른 예제를 살펴보자



자 우리가 상상을 한 번 해보자
본인의 계좌에 처음에 50만원이 있었다고 하자.
근데, 50만원을 입금함과 동시에 150만원을 입금을 했으면 250만원이 돼야 하는데, 잔고를 확인하니 100만원이 찍혀 있었
다. 이건 매~~~우 심각한 상황이다.
이렇게 된 이유는 트랜잭션 1의 write(x=100)에 의해서 트랜잭션 2의 실행 결과가 덮어 씌여졌기 때문이다.
이러한 이상한 현상을 Lost Update 라고 한다.

앞에서 배운 Dirty Read이다.
트랜잭션 1의 read(y)에서 commit되지 않은 변화(write(y=70))을 읽음으로, 트랜잭션2가 roll back됐을 때, DB에 잘못된 데
이터가 저장되는 경우이다.
하지만 표준SQL에서 정의한 Dirty Read와는 다르게 마이크로소프트의 반박 논문에서는 꼭 roll back이 안 돼도 DB에 이상
한 값이 저장될 수 있다고 말한다. 아래를 살펴 보자.

X와 Y를 계좌라고 생각을 하면 좋을 듯!!!

여기에서 roll back은 일어나지 않았다.
DB에 저장된 X는 10이고 Y는 90이다.
트랜잭션 2에서 똑같이 X ,Y를 읽어 들였는데, X는 10이나, Y가 50으로 DB에 저장된 Y값과는 이상한 값을 읽어 들였다.
이와 같이 ABORT가 일어 나지 않아도 commit되지 않은 데이터를 읽어 들였을 때 이상한 현상이 일어날 수가 있다.
또 다른 예제를 보자

이때에도 트랜잭션 2에서 읽어 들은 x값이 DB의 x값가 불일치하는 데이터 불일치 현상이 일어 났다.
위와 같이 inconsistent한 데이터 읽기를 Read Skew 라고 부른다.
Read Skew vs Non-repeatable read
똑같은 데이터를 읽어 들였는데 값이 다르면 -> Non-repeatable read
서로 다른 데이터를 읽어 들였는데 값이 다르면 -> Read Skew
-> 매우 비슷하지만 미묘한 차이가 존재
또 다른 예제를 살펴 보자

이번 예제에서는 x+y >= 0이라는 제약사항이 있다.

각가의 트랜잭션은 핵심 Operation들의 실행 전, 제약 조건의 만족 여부를 확인하기 위해, x와 y값을 읽어 들인다.

최종 결과은 x=-30과 y=-40은 제약 조건을 충족시키지 못한다.
RDBMS는 트랜잭션의 Consistency 특성을 위해 모든 트랜잭션의 실행들이 끝이 나면, 제약 사항들을 위반한 것이 없는
지 검사를 해준다.
RDBMS가 트랜잭션들이 ACID 특성들을 지키도록 잘 구현이 돼 있다면, 최종 결과에 대해 제약 사항 위반이라고 판단을 하
여 트랜잭션 2의 commit을 만나는 순간 ABORT가 발생하게 된다.
그런데 만약 ABORT가 발생되지 않고 정상 처리가 되면 이것또한 이상한 현상에 해당이 된다.
왜냐하면, 서로 다른 데이터인 X와 Y에 대해 write했음에도 불구하고 inconsistent한 데이터, 즉 데이터 불일치라는 현상이
생기기 때문이다.
(보통, 데이터 불일치는 같은 데이터에 대해 write했을 때에 발생을 한다. )
이러한 이상한 현상을 write skew라고 부른다.

같은 트랜잭션에서 똑같은 조건에서 데이터를 읽어 들였는데 없던 데이터가 새로 생기는 이상한 현상을 phantom read라
고 배웠는데, 마이크로소프트에서의 반박 논문에서는 이 phantom read가 더 넓은 의미로서 확장을 시켜야 한다고 한다.
아래의 예제를 살펴 보자.

cnt값은 DB에 존재하는 tuple 중, v의 값이 10보다 큰 tuple의 갯수를 의미한다.

트랜잭션1의 2번에 걸친 read에 값은 서로 다르다.
근데 우리가 배운 phantom read는 똑같은 조건에서 여러 읽었을 때의 데이터 불일치 현상이라고 배웠다.
그러나 트랜잭션1의 read의 조건은 서로 다름에도 불구하고, 그 2개의 read 사이에서 실행된 Operation에 의해서 데이터
불일치가 발생하였다.
마이크로소프트에서는 read의 조건이 달라도 데이터 불일치가 발생을 하면, 그것도 phantom read라고 봐야한다고 주장
했다.
snapshot isolation
표준 SQL에서 정한 isolation level을 대체하는 isolation level.
구체적인 것은 아래에서 살펴보겠다.
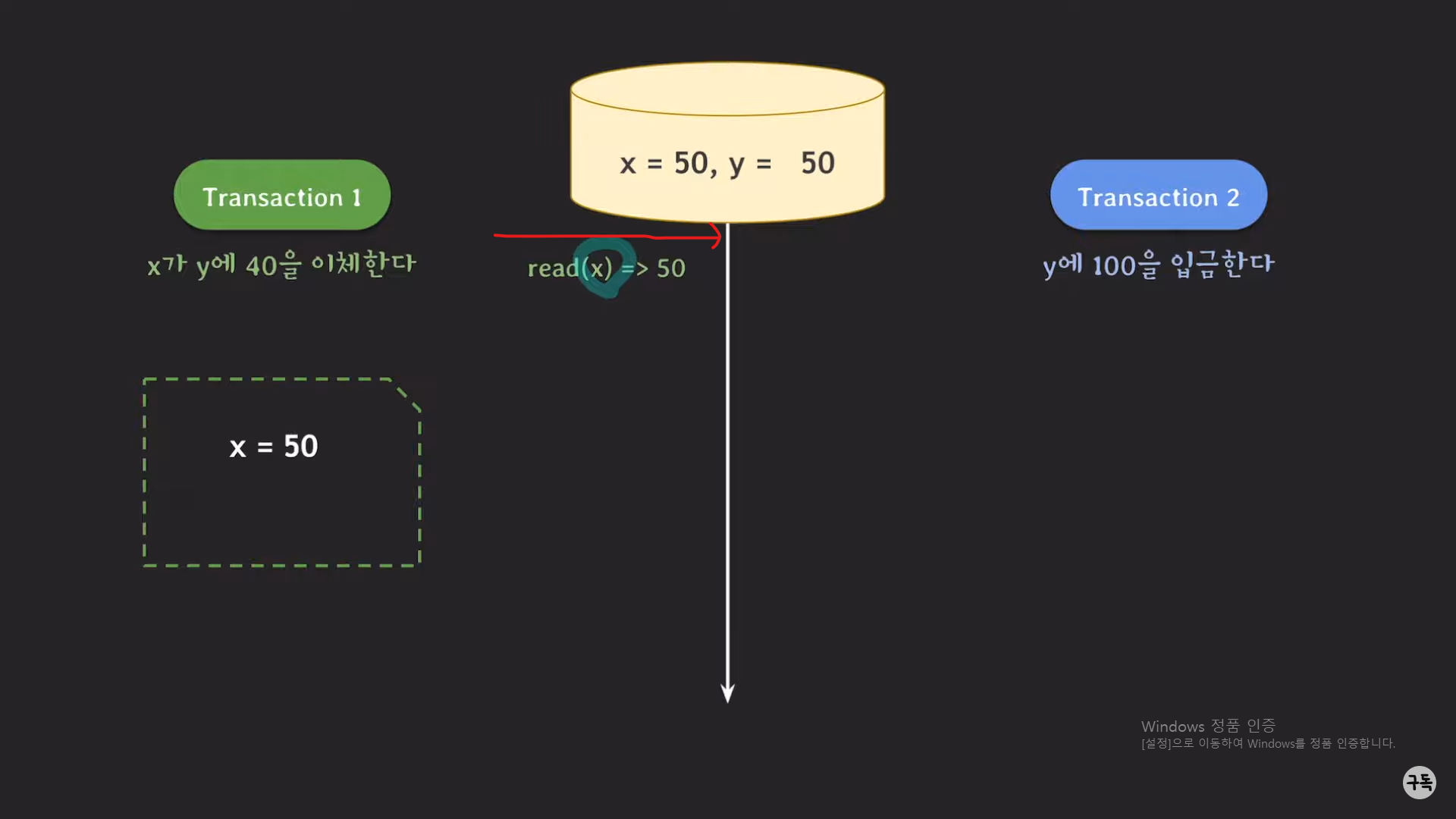
트랜잭션이 시작된 시점에서의 DB의 데이터들에 대해서만 읽고, 쓴다.
트랜잭션1의 시작 시점은 read(x)인데 이 시점의 x,y는 각각 50,50이므로, read(x)의 결과는 50이다.
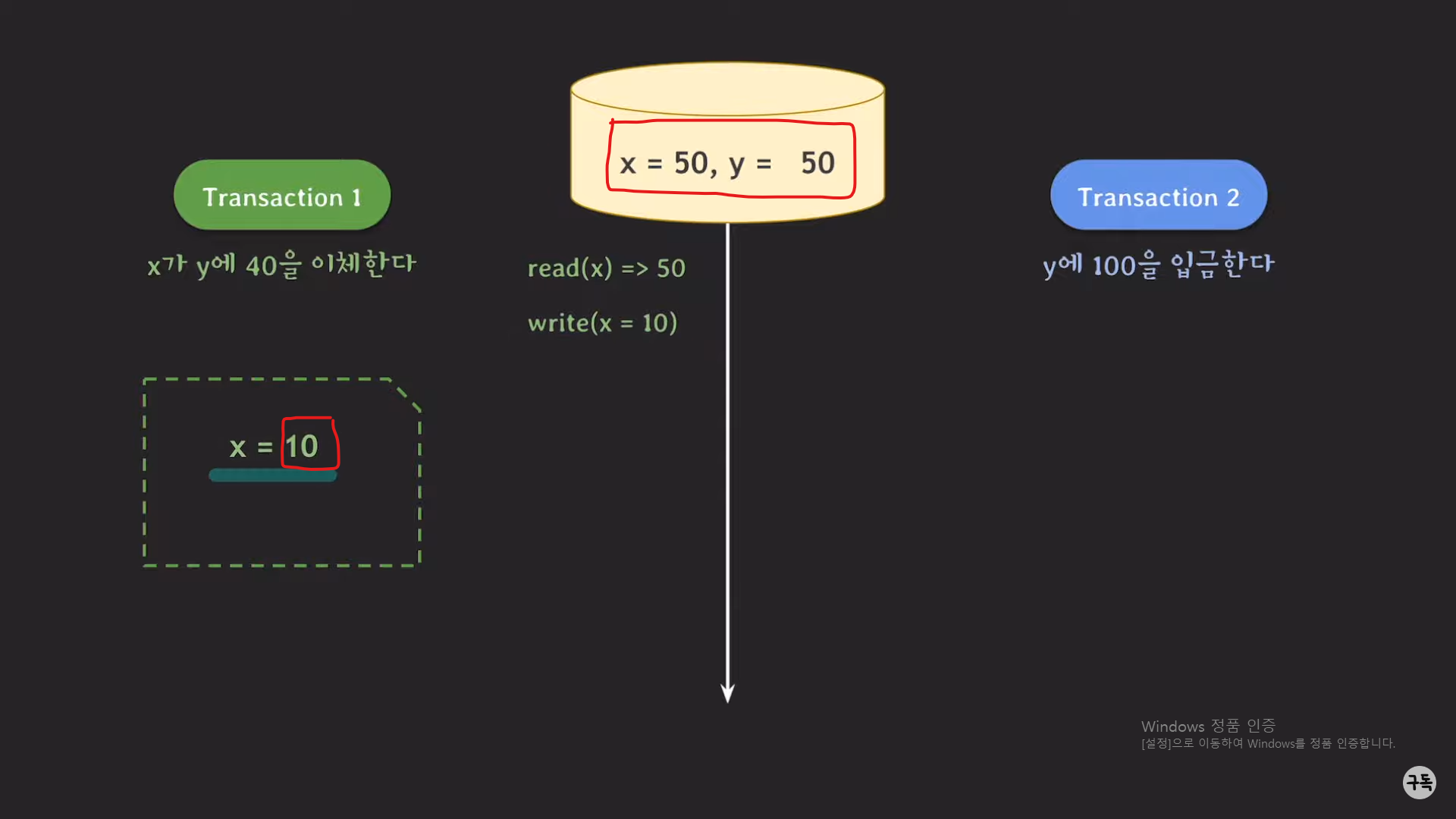
write(x=10)에 의해서 DB에 바로 적용이 될 것 같지만, snapshot level에서는 그렇게 동작하지 않는다.
x = 10은 트랜잭션1의 snapshot에 적용이 된다.

트랜잭션2의 시작 시점은 read(y)인데, 이떄의 DB의 x,y값도 50,50이므로 read(y)의 결과값으로 50이 읽혀서 트랜잭션2의
snapshot에 적용된다.

write( y = 150 )에 결과가 DB에 적용되지 않고, 트랜잭션2의 snapshot에 적용이 된다.

트랜잭션2의 commit을 만나서야 비로서 트랜잭션 2의 snapshot의 데이터 값들이 DB에 영구적으로 저장이 된다.

트랜잭션1의 read(y)의 값은 무엇일까??
DB에 Y=150으로 저장돼 있으니 150이라는 값을 읽어 올 것 같지만 그렇지 않다.
위에서도 언급을 하였듯이 snapshot level에서는 트랜잭션의 시작 시점의 DB 데이터를 읽고, 쓴다.
고로, read(y)의 결과값은 50이다.


트랜잭션1이 commit을 하려고 하면 abort가 발생이 된다..
write-write conflict가 발생 시, 먼저 commit된 것을 우선시하므로 write(y=90)의 실행결과를 commit하려는 순간 우선 순위
에서 밀리게 되면서 abort 발생.(만약 write(y=90)이 db에 적용이 되면 그건 Lost Update 현상이다.)
snapshot isolation의 특징 2가지
1. write-write conflict 발생 시, 먼저 commit한 것에 우선권을 주고, 우선 순위에 밀리 것에 대해서는 abort 처리를 한다.
2. 각 트랜잭션은 트랜잭션이 시작하는 시점에서의 DB 데이터만을 읽고, 쓴다.
3. snapshot isolation은 표준 SQL의 isolation level 중 serializable level에서 실행된다고 보면 된다.
MVCC(Multi Version Concurrency Control)
뭔지는 몰겠지만 snapshot isolation은 MVCC의 한 종류라고 한다.





'CS 과목(CS科目) > 데이터 베이스(データベース)' 카테고리의 다른 글
| 19.MVCC - Part 1 (0) | 2022.12.12 |
|---|---|
| 18. LOCK을 활용한 concurrency control (1) | 2022.12.12 |
| 16. concurrency control - Part 2 (0) | 2022.12.10 |
| 15. concurrency control(Serial schedule, NonSerial schedule) - Part1 (1) | 2022.12.10 |
| 14.Transaction (0) | 2022.12.10 |



