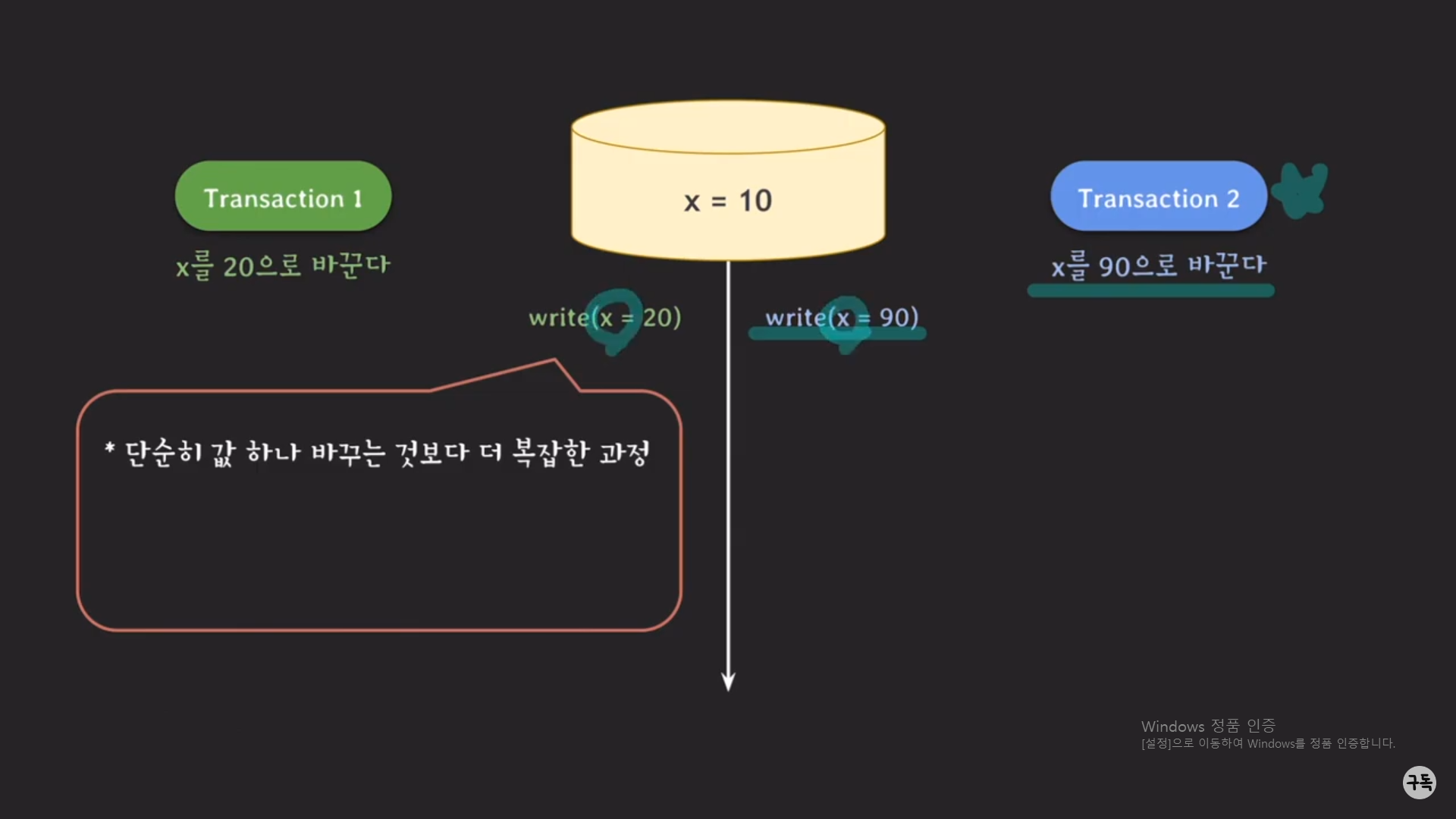
트랜잭션 1의 목적을 달성하기 위해서는 write(x=20) 작업이 필요하다.
그러나, 위 그림은 설명을 쉽게 하기 위해서 단순히 write(x=20) Operation 하나만 실행을 해주면 되는 것처럼 적어놨다.
그러나 write를 하게 될 때, 만약 index가 걸려 있다면 거기에 대한 처리도 해야 할 것이고, 이 데이터가 실제로 저장되는 파
일에 대해서도 이런 저런 처리를 해줘야 하므로, 실제로는 복잡한 실행 과정을 거쳐야 한다.
이때, 트랜잭션1의 write와 트랜잭션2의 write가 동시에 실행이 된다고 해보자.
어떠한 데이터를 write하는 과정은 복잡한 과정이므로, 같은 데이터를 트랜잭션2에서 write를 동시에 처리하게 되면, 최종
적으로 데이터가 깔끔하게 처리되지 않을 가능성이 높다.
그럼, 이러한 같은 데이터에 대해 동시에 read/write를 할 때 발생하는 문제를 해결하기 위해서는 어떻게 해야 할까??
Lock을 이용하면 된다.
Lock : 운영체제에서 말하는 Lock이며, 간략히 설명을 하자면 테이터마다 Lock을 가지고 있는데 데이터를 read/write할려
면 Lock을 취득해야 한다. 만약 Lock을 취득하지 못하면 Lock을 취득할 때까지 기다려야 read/write 작업을 수행할 수가 있
다.
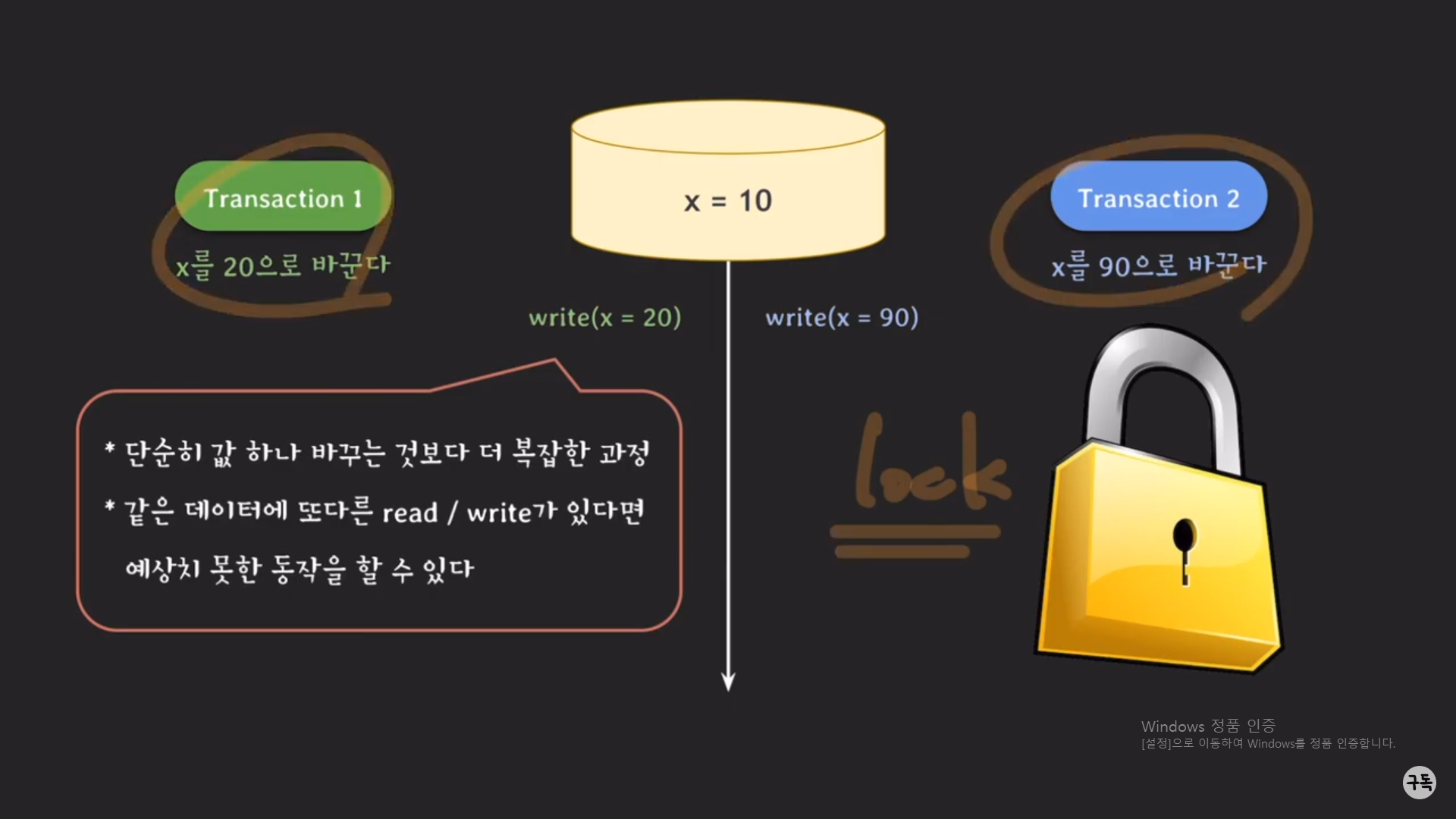
아래에서 lock을 이용하여 문제점을 해결하는 예제를 살펴보자
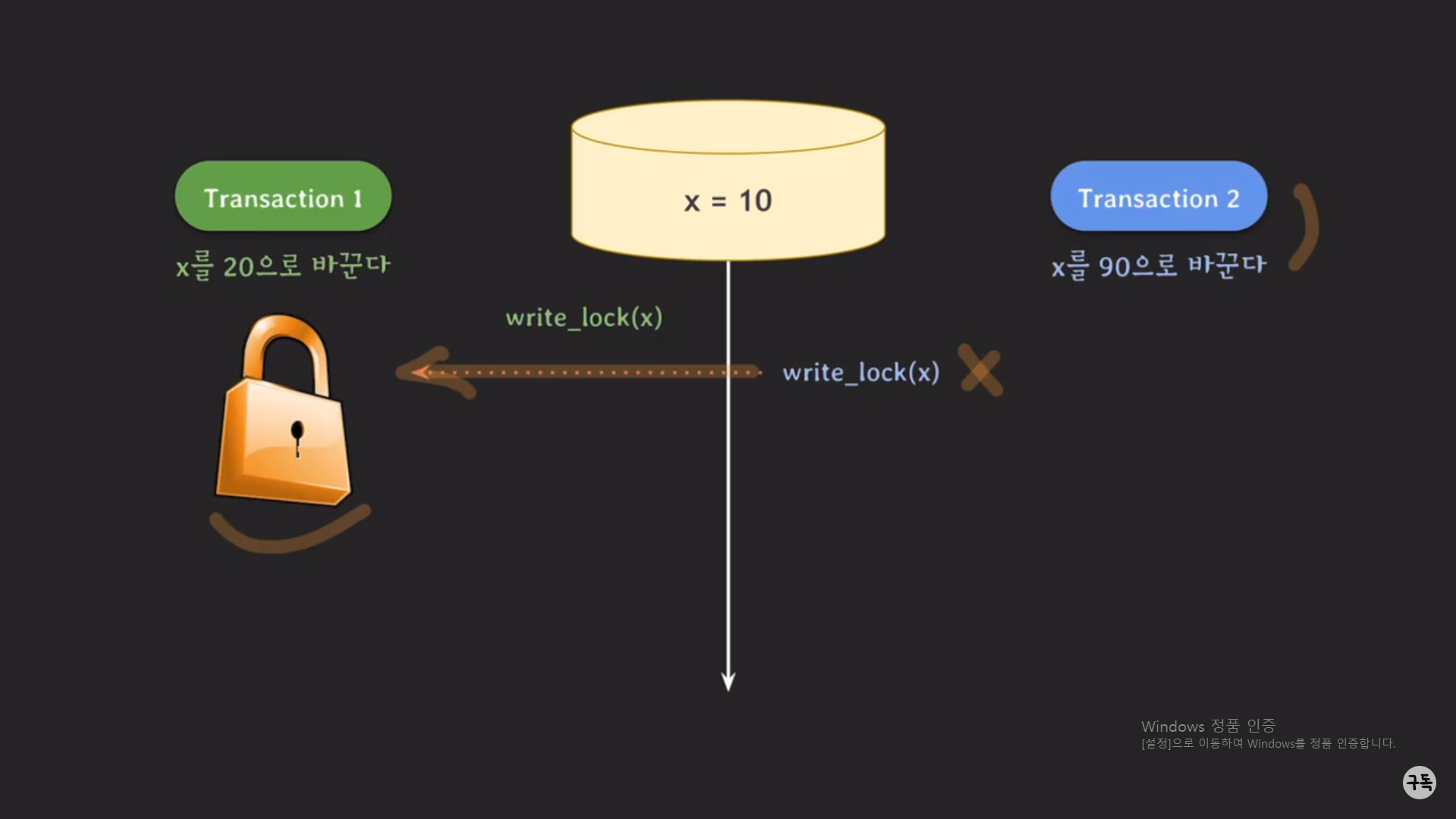
트랜잭션1이 먼저 실행이 됐다고 하자.
트랜잭션1은 x의 값을 write하기 위해 먼저 x에 대한 lock을 획득을 해야 한다.( write_lock(x) )
그런데 이때, 트랜잭션 2가 실행이 돼서, 트랜잭션 2번도 x의 값을 write하기 위해 lock을 요구를 하게 되는데,
이미 트랜잭션 1번이 x에 대한 lock을 반환을 하지 않았기 때문에, 트랜잭션 2번의 Operation은 lock이 반환될
때까지 기다리며, 트랜잭션 1번은 다음 Operation들을 진행한다.
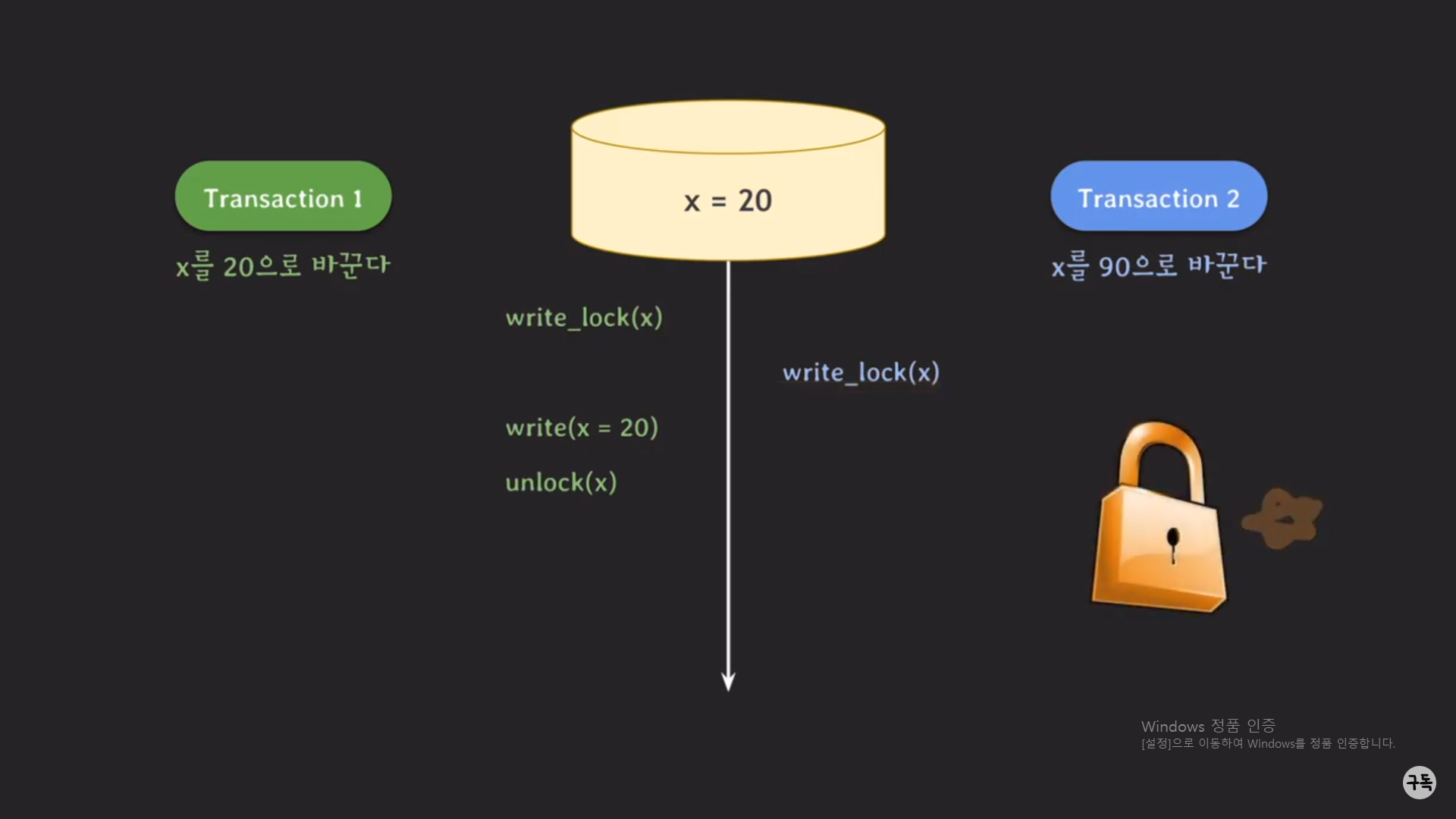
트랜잭션 1번의 실행이 모두 끝나게 되면, unlock(x)를 통해 트랜잭션 1번이 가지고 있던 lock을 반환을 하여, 이제 드
디어 write_lock(x)에서 lock이 반환되기만을 기다렸던 트랜잭션 2번이lock을 취득하게 되어, 다음 Operaion을
실행해 나간다.
트랜잭션 2번도 실행이 모두 끝나면, 다른 트랜잭션들도 x에 대한 lock을 필요로 할지도 모르기에 unlock(x)를 통해
lock을 반환을 해준다.
또 다른 예제를 살펴 보자.
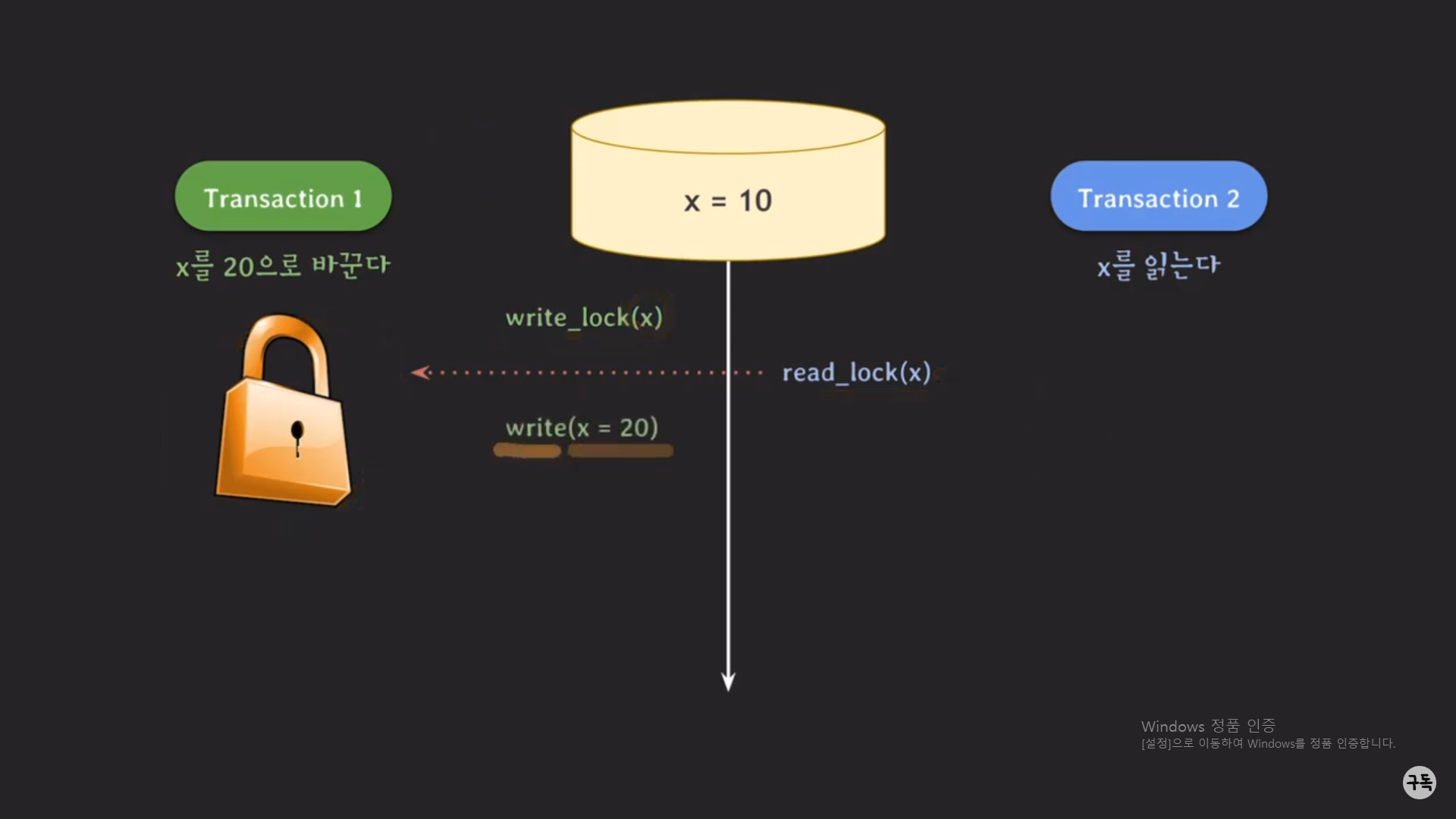
트랜잭션 1번이 X를 20으로 write하기 위하여 lock을 요청하여 획득을 한다.
그 다음 트랜잭션 2번이 실행이 되고, x의 값을 read하기 위하여 lock을 요청하지만, 이미 lock을 트랜잭션1번이 가지고 있
기 때문에 트래잭션 2번은 lock을 반환될 때까지 실행을 멈추고 기다린다.
반면, 트랜잭션 1번은 계속해서 실행을 이어나가면 된다.
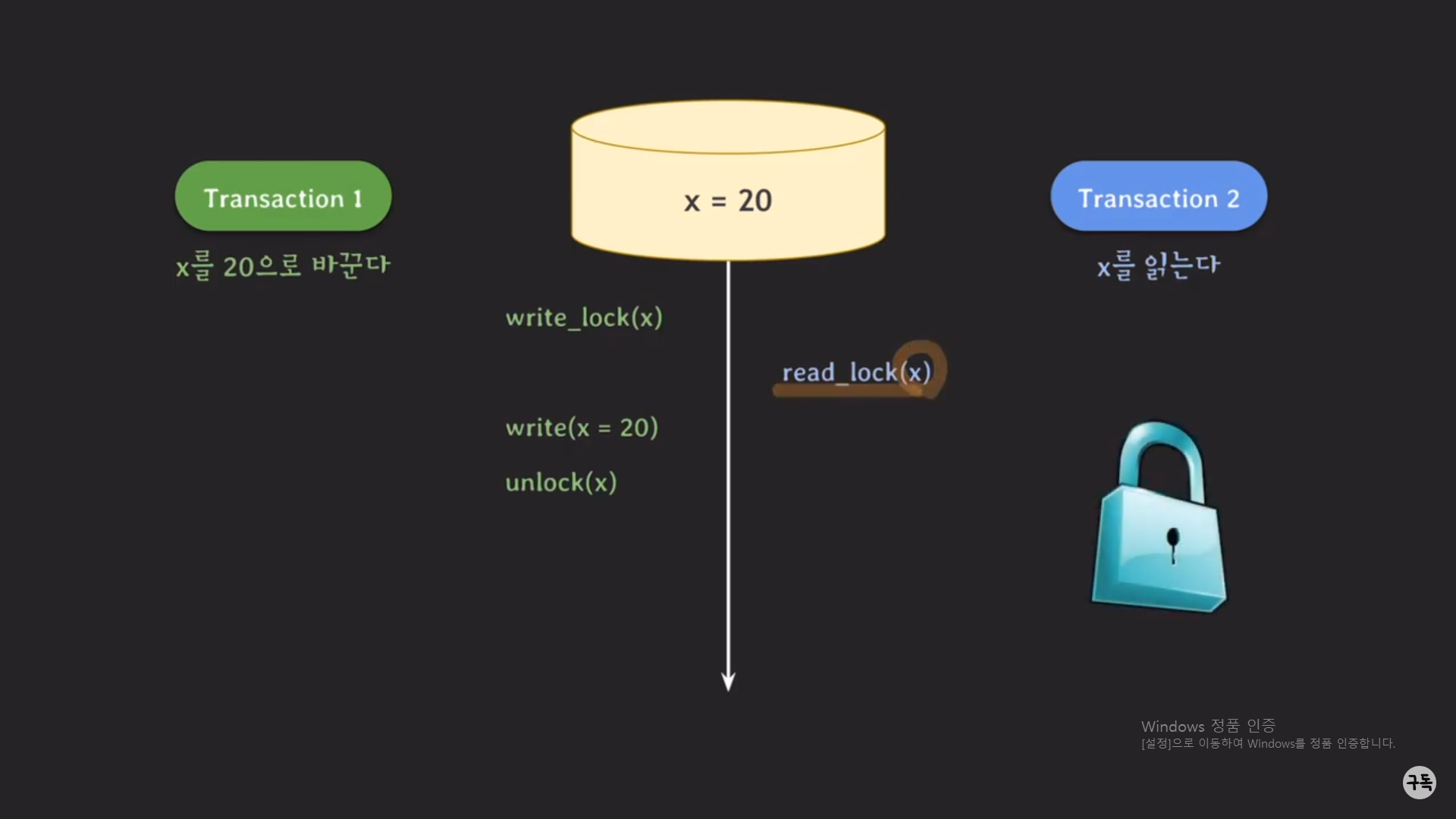
트랜잭션 1번의 실행이 끝나면 unlock()을 통하여 x에 대한 lock을 반환을 한다.
실행을 멈추고 기다리고 있었던 트랜잭션2번은 이제 lock을 취득하게 돼서, 실행을 이어 나갈 수 있다.
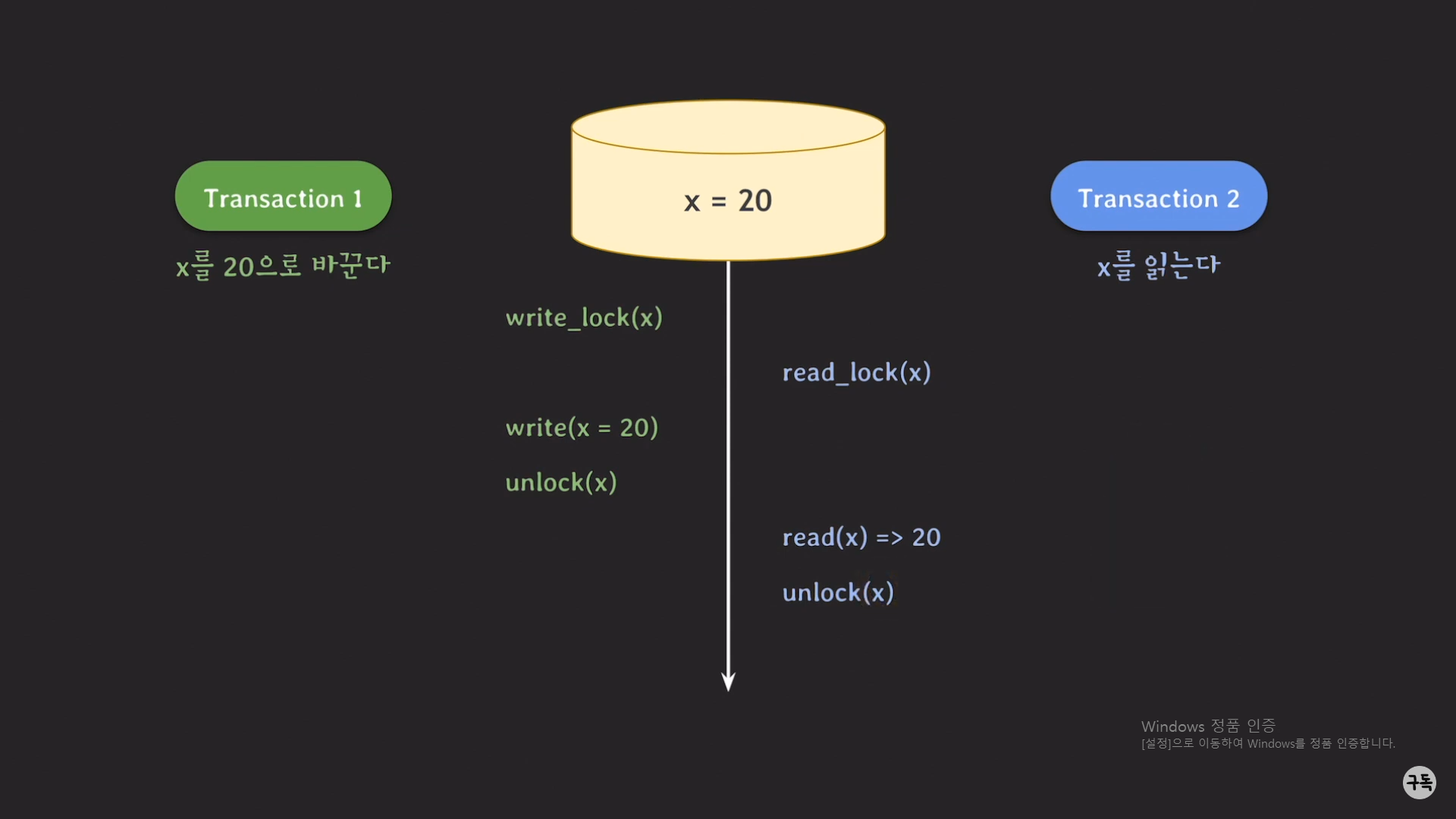
트랜잭션 2번도 종료가 되고, 다른 트랜잭션에서도 x에 대한 lock을 기다리고 있을 수 있으므로 unlock(x)를 통하여 lock을
반환해 준다.


write-lock과 read-lock을 잘 이해하기 위해서 아래에서 2가지 예제를 추가로 살펴보자
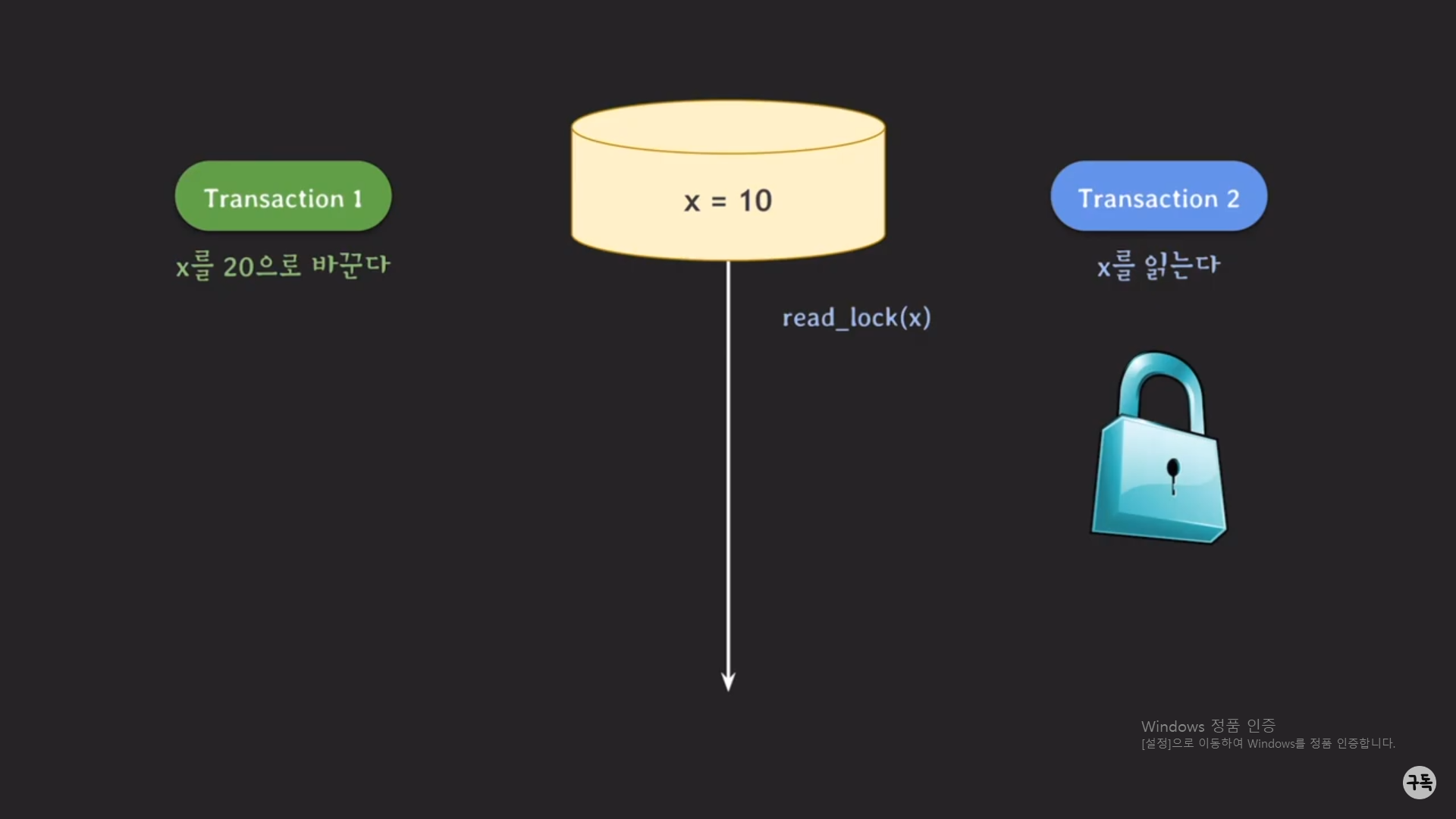
이번에는 트랜잭션 2가 먼저 실행이 된다고 해보자.
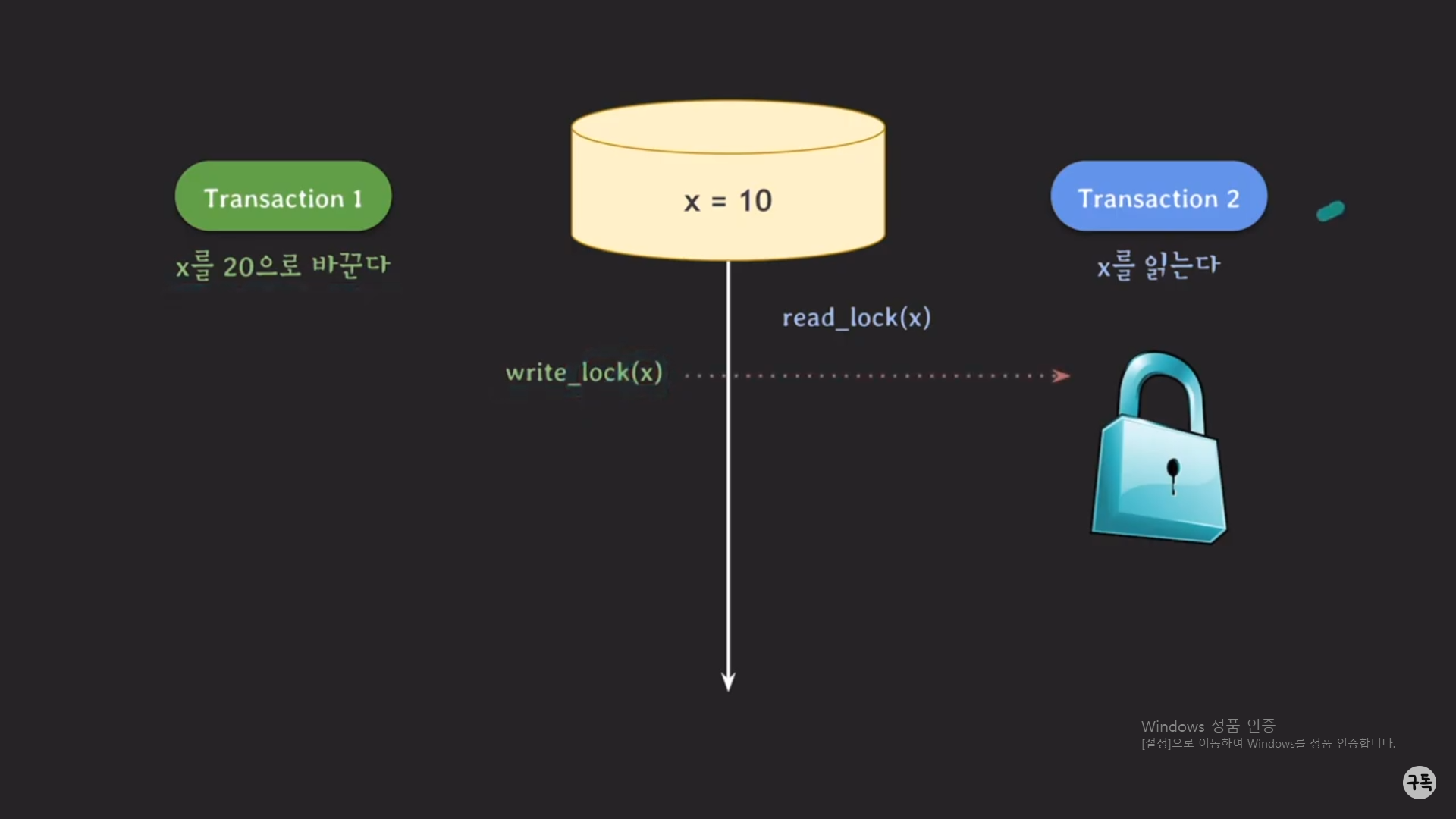
트랜잭션 2에서 lock을 가지고 있기 때문에, 트랜잭션 1은 block이 되며, lock이 반환이 될 때까지 실행을 대기한다.
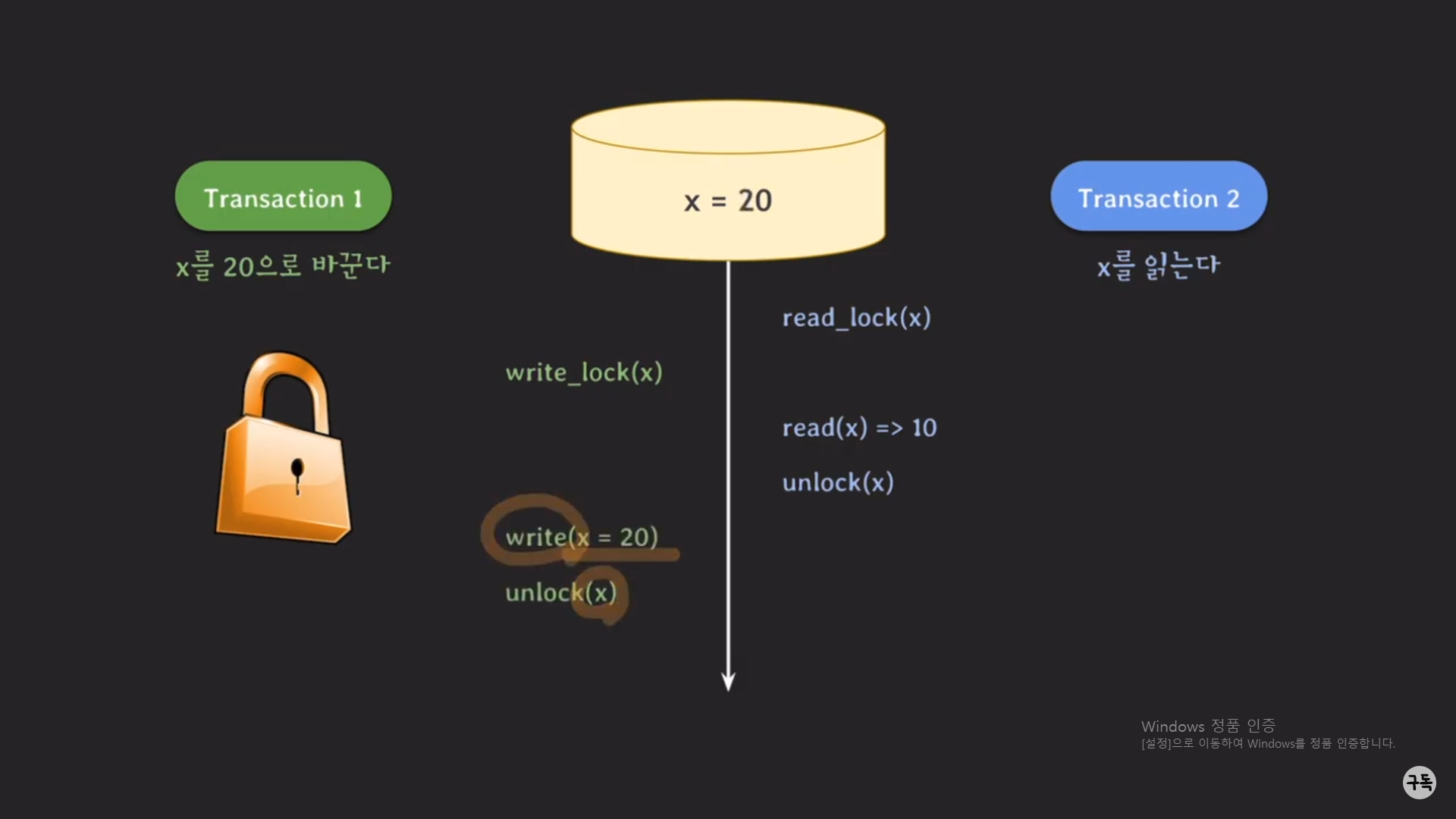
트랜잭션2는 x의 값을 읽어 들이는 것이 목적이다.
그런데, 트랜잭션1에서 x의 값을 20으로 바꾼뒤에 값을 읽게 되면, 그것은 바람직하지 못한 읽기 작업이 될 것이다.
트랜잭션 2의 작업은 isolation 관점에서 여러 트랜잭션이 동시에 실행이 되더라도 마치 단독으로 트랜잭션 2가 실행된 것
처럼 되어야 하기 때문에 x의 값 10을 읽어 들이는 것이 바람직하다.
근데 만약 위 그림들처럼 lock이라는 것을 걸어 두지 않았더라면 트랜잭션 1의 write 작업에 의해 트랜잭션 2에서는 x의 값
을 10이 아닌 20을 읽어 들이게 되었을 가능성이 매우 높았을 것이다.
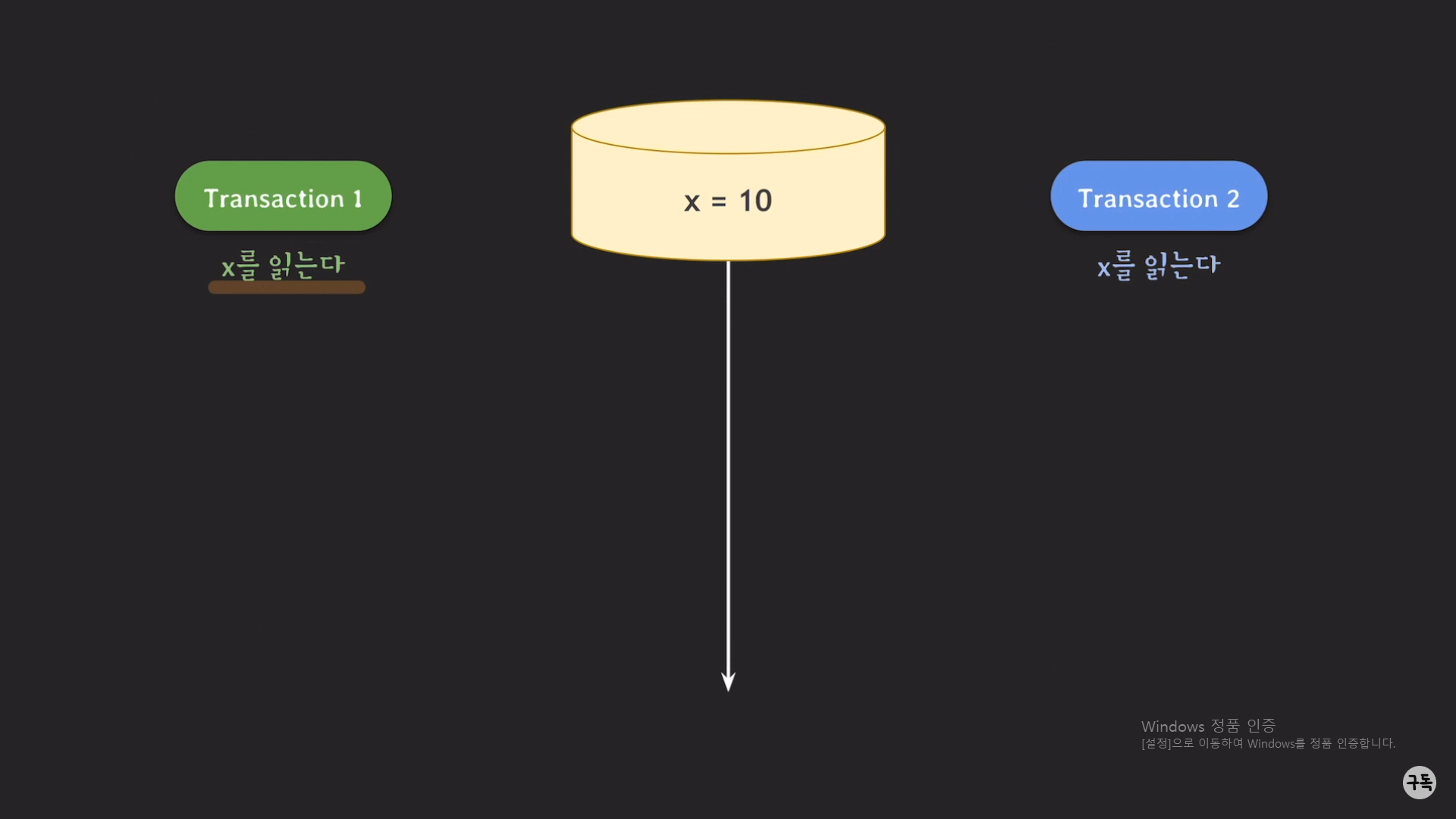
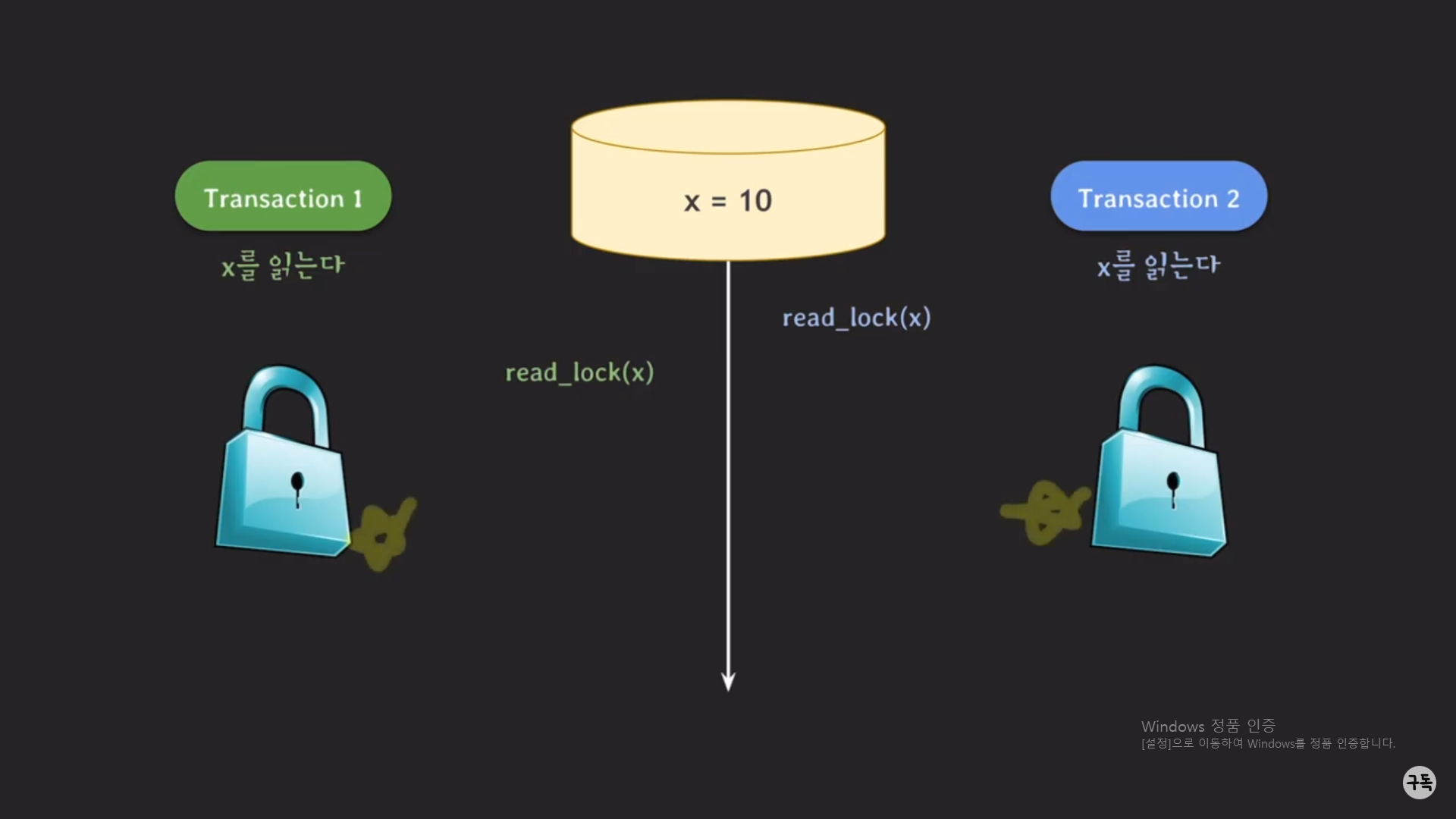
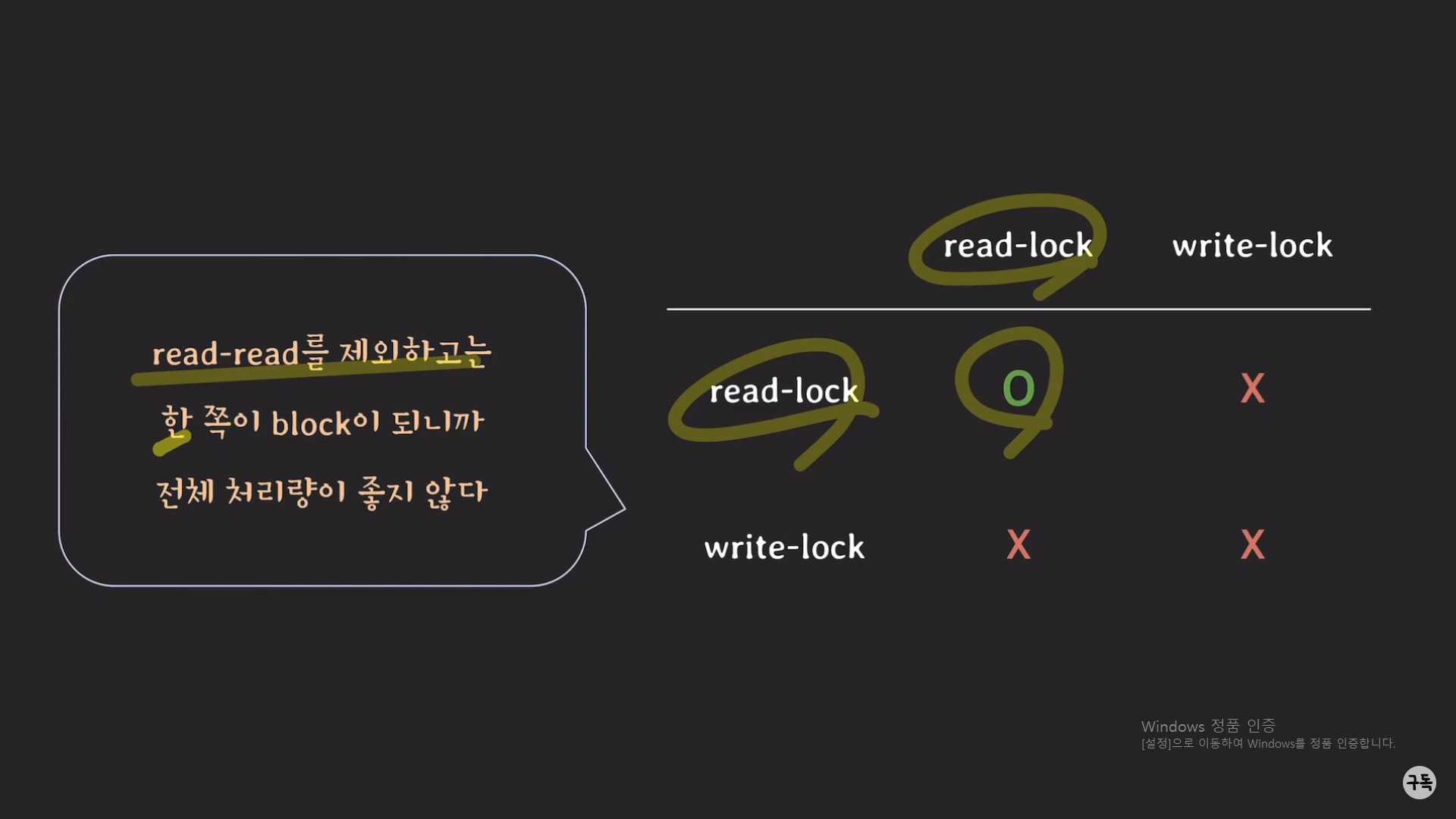
read 작업 같은 경우는, 비록 트랜잭션 2에서 먼저 lock을 갖고 있는 것과는 상관이 없이 read 작업이 가능하다.
그래서 트랜잭션1의 read_lock(x)의 결과로 트랜잭션1도 lock을 갖는 상태가 된다.
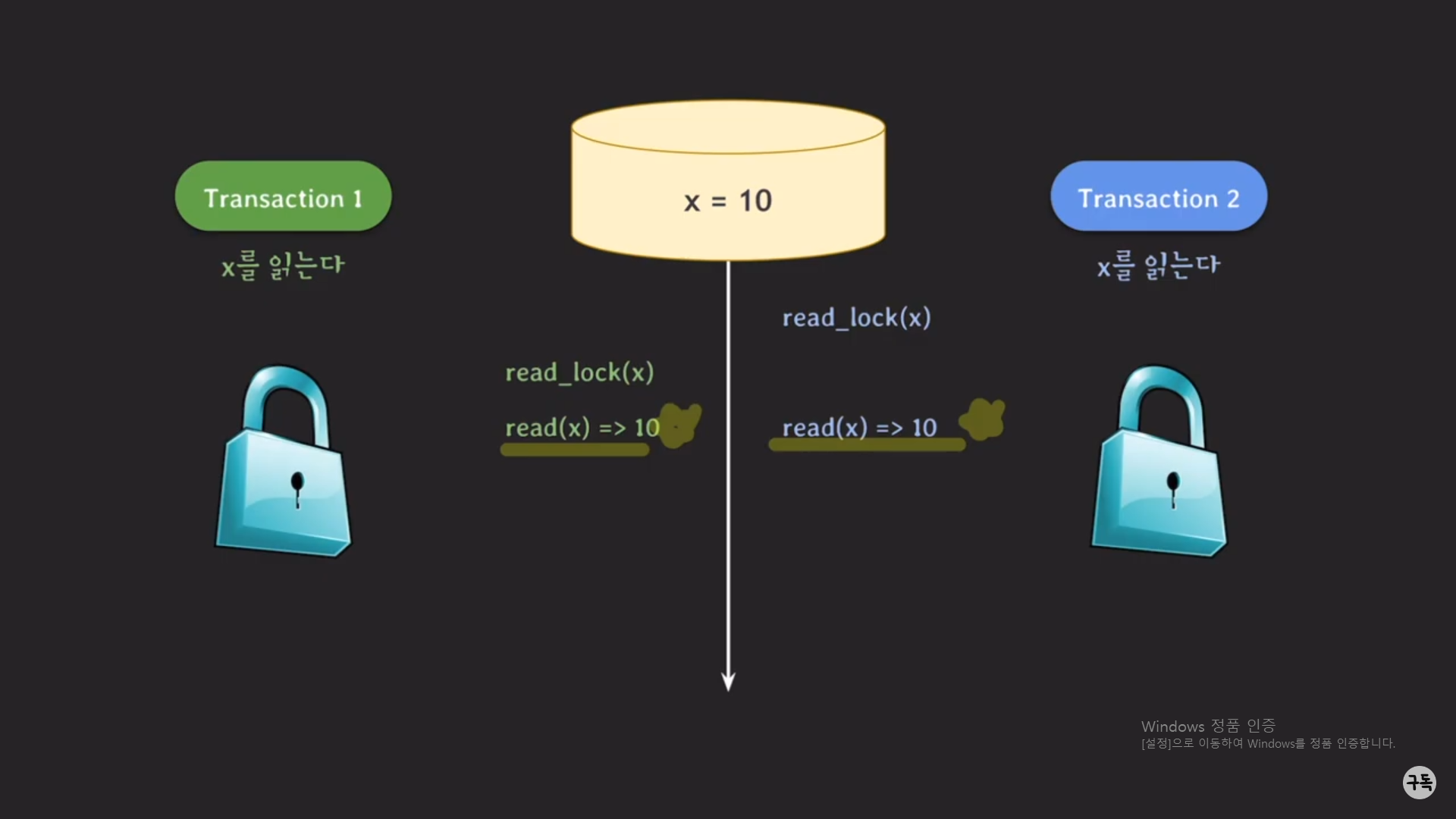
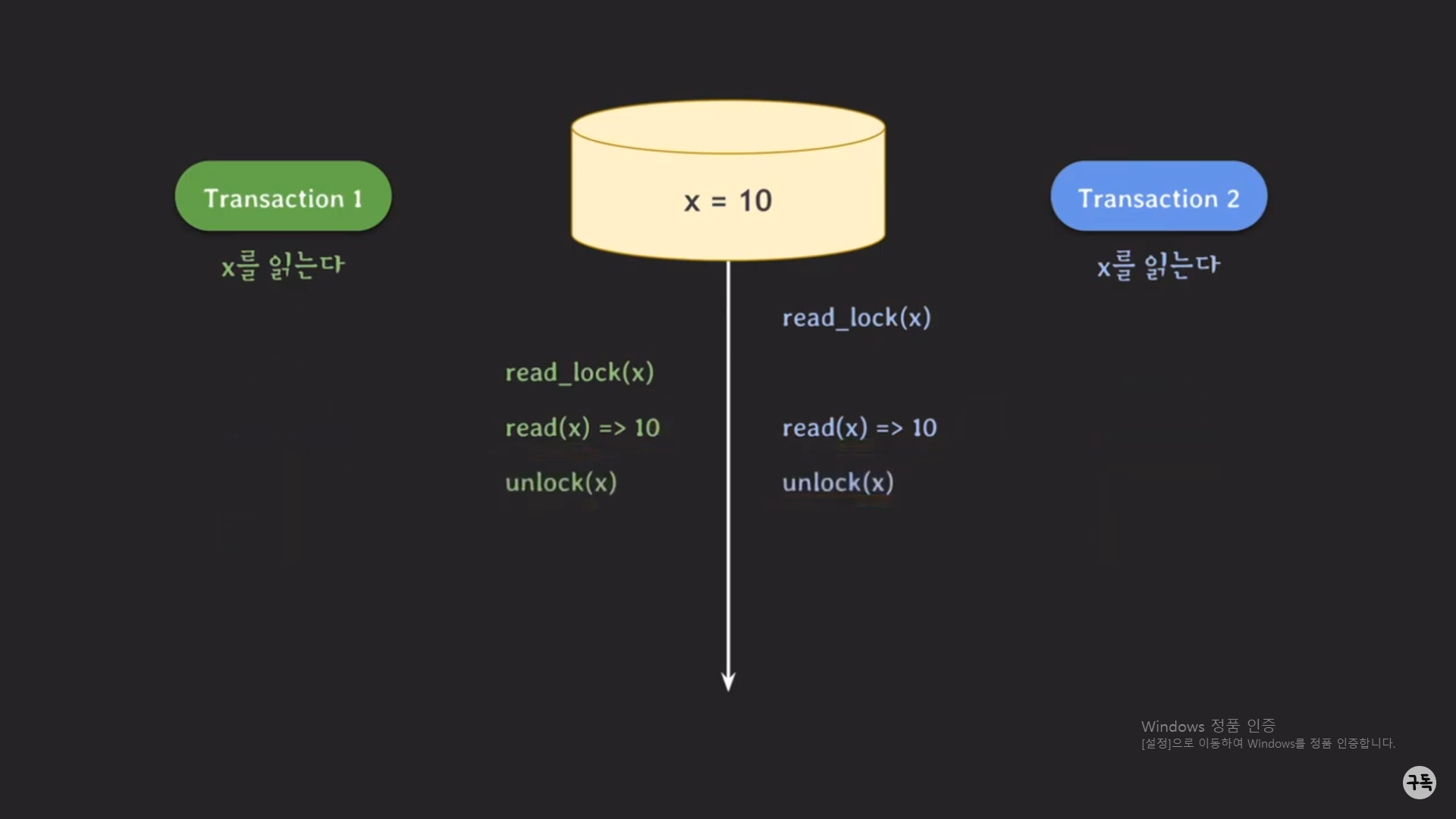
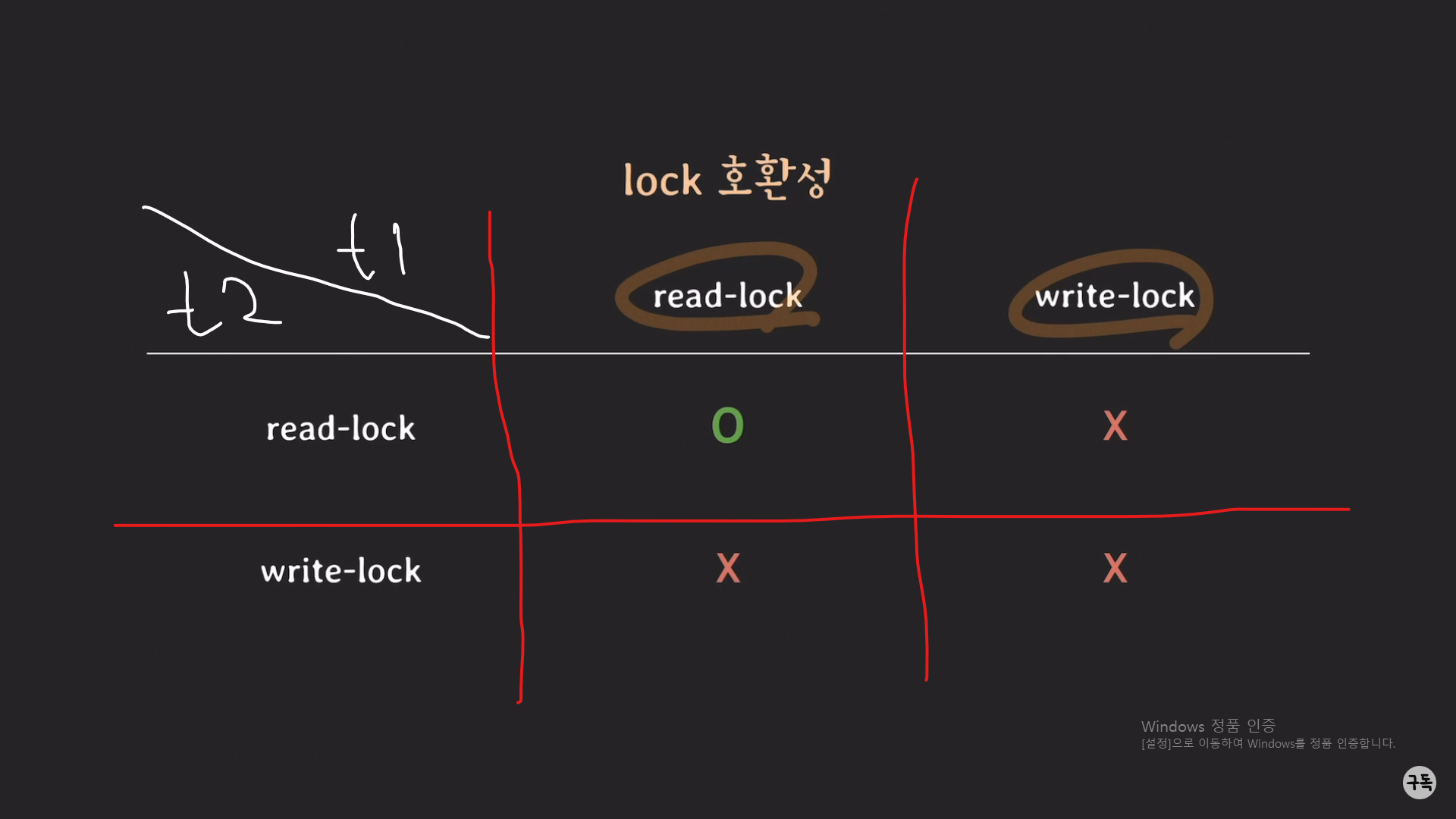
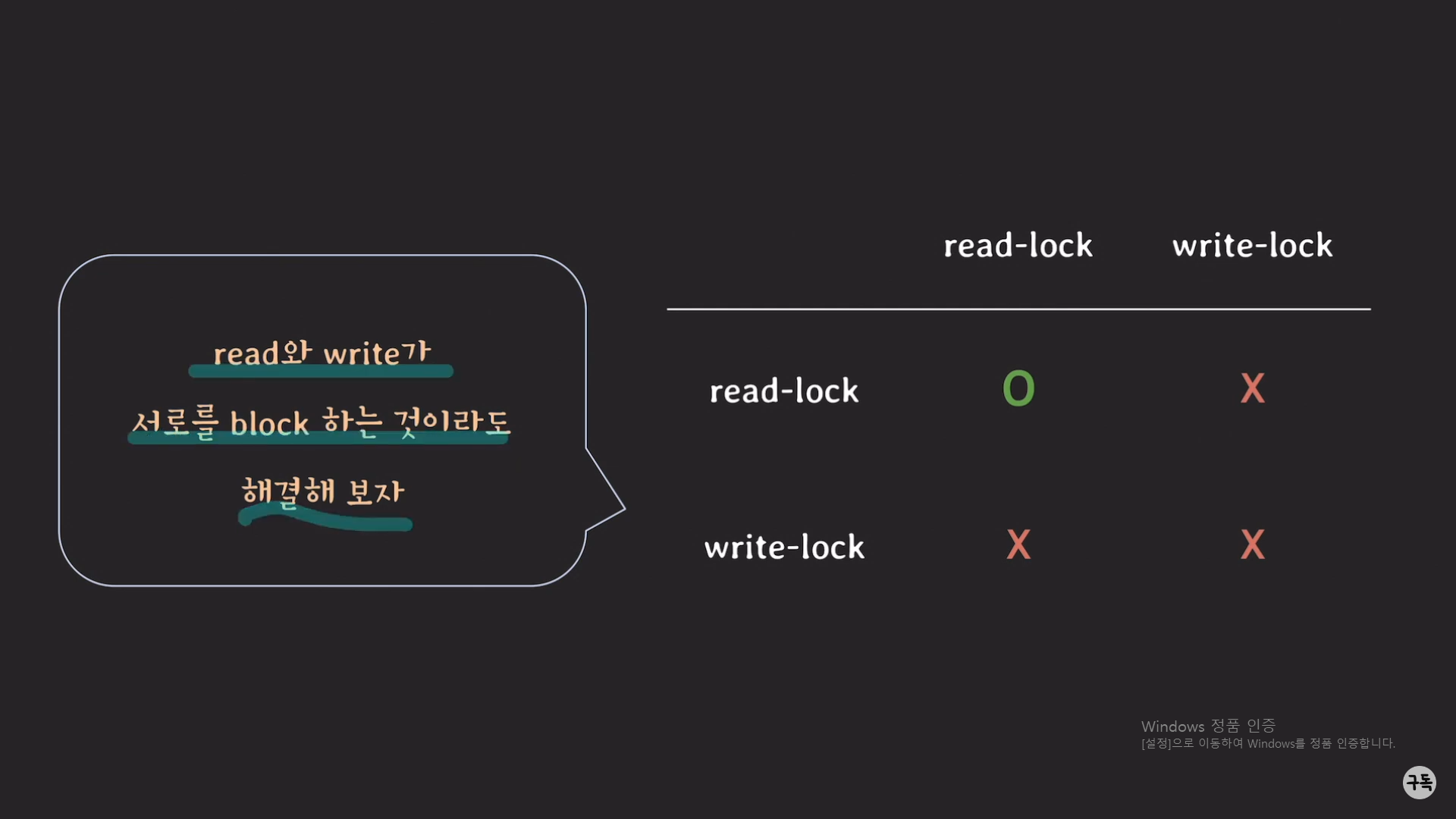
t1에서 read_lock을 쥐고 있는 경우 -> t2는 read_lock을 가질수는 있지만, write_lock을 가지지는 못한다.
t1에서 write_lock을 쥐고 있는 경우-> t2는 read_lock, write_lock 둘 다 가지지 못한다.
실제로 lock을 통해서 concurrency control이 어떻게 구현이 되는지를 살펴 보자.
( concurrency control을 풀어서 재정의를 하자면, Non-serialization schedule을 어떻게 isolation 특성을 유지시켜서
serialization schedule의 동작 방식과 같은 방식으로 구현을 하는 것이다.)
그 이전에 , 알아야 할 것이 있다.
lock을 사용하는 것만으로는 concurrency control을 보장할 수가 없다.
lock을 사용하여도 이상한 현상이 발생할 수가 있는데, 그 경우에 대해서 먼저 살펴 보자.

트랜잭션1,2가 serialized schedule처럼 동작을 한다면??
즉, 하나의 트랜잭션이 종료되고 나서, 나머지 트랜잭션이 종료가 된다면??
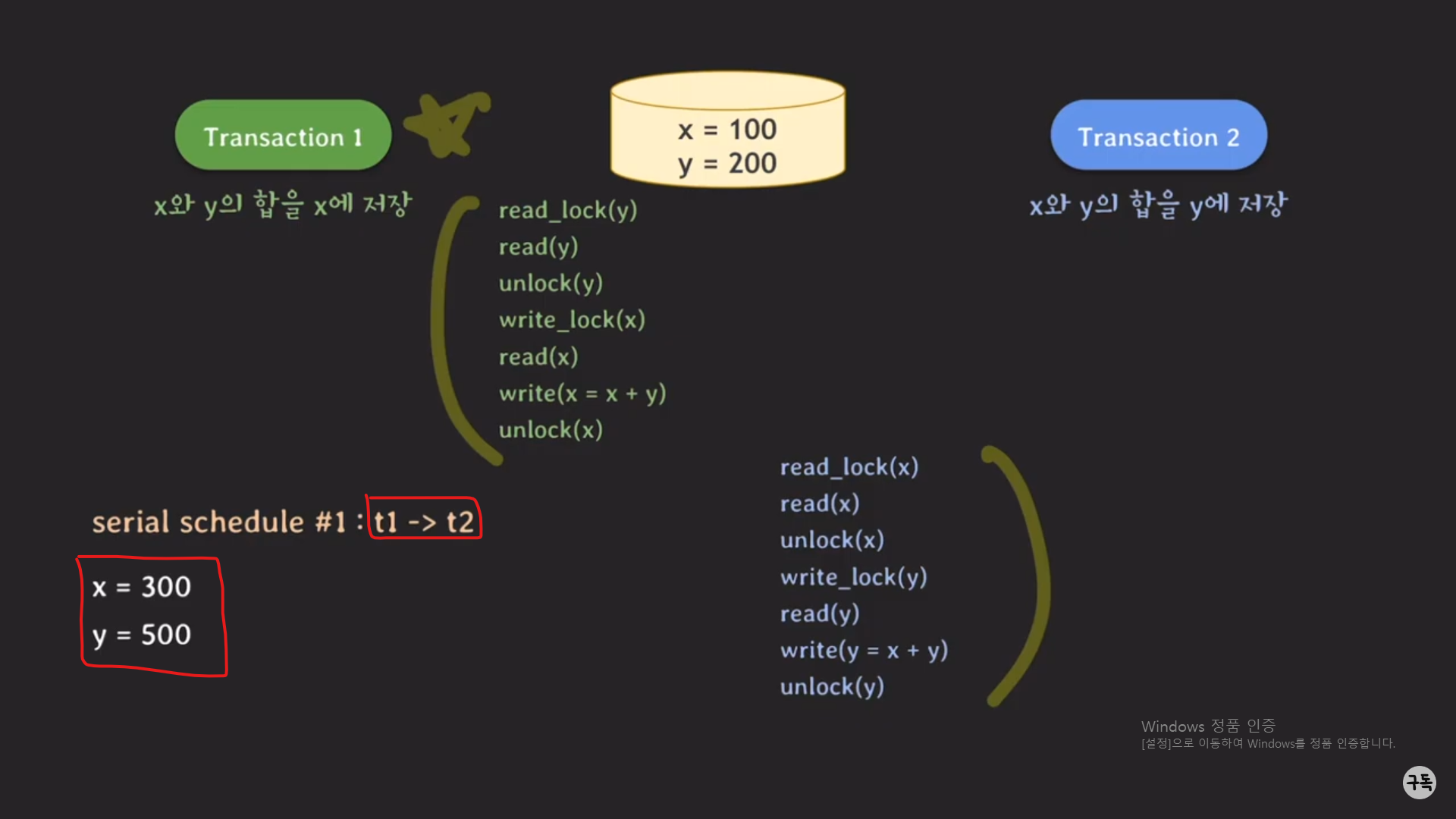

case1,2의 최종값들을 일단 기억해 두고, 아래에서는 트랜잭션1,2가 동시에 실행되는 경우를 살펴보자.
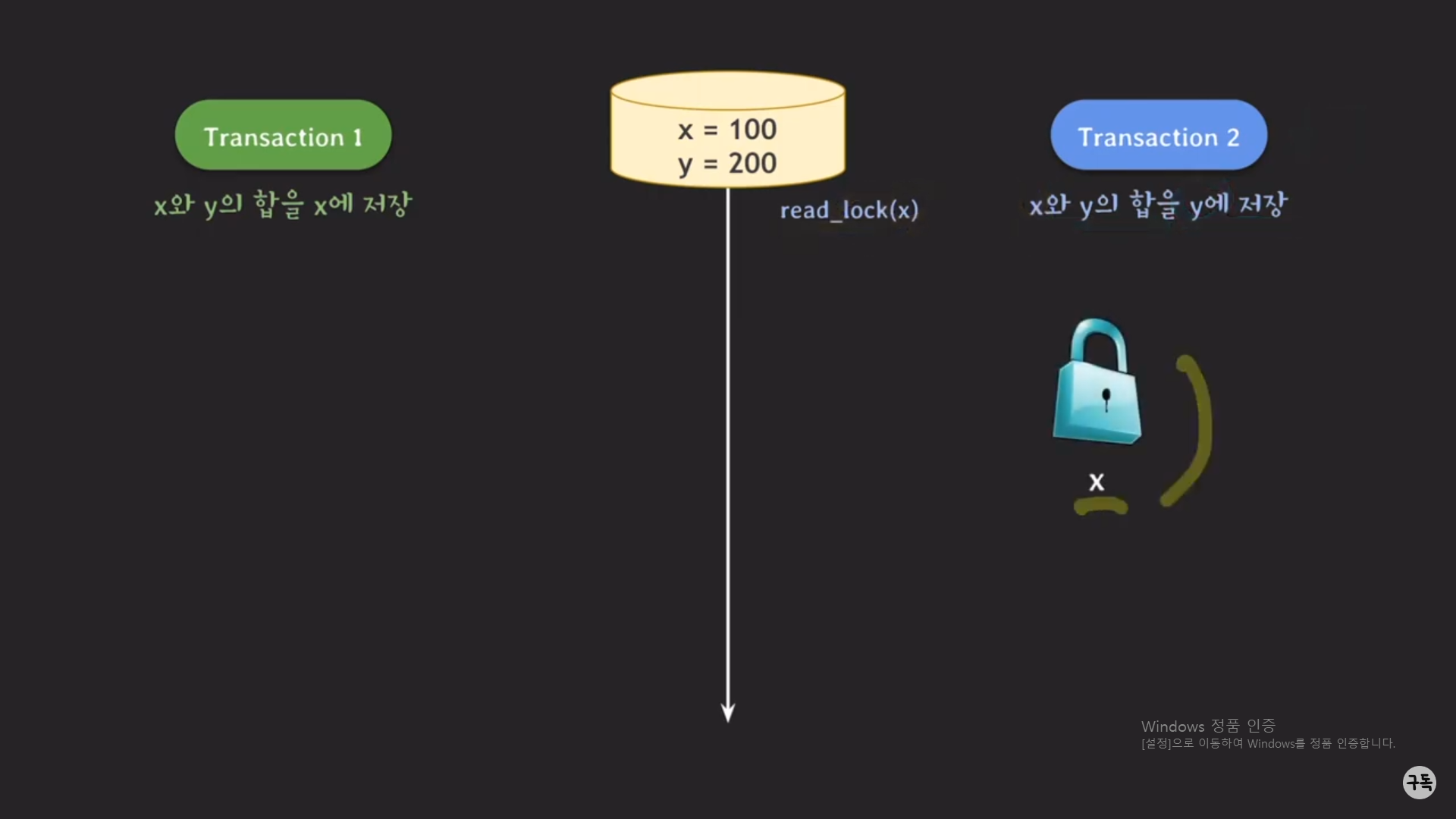
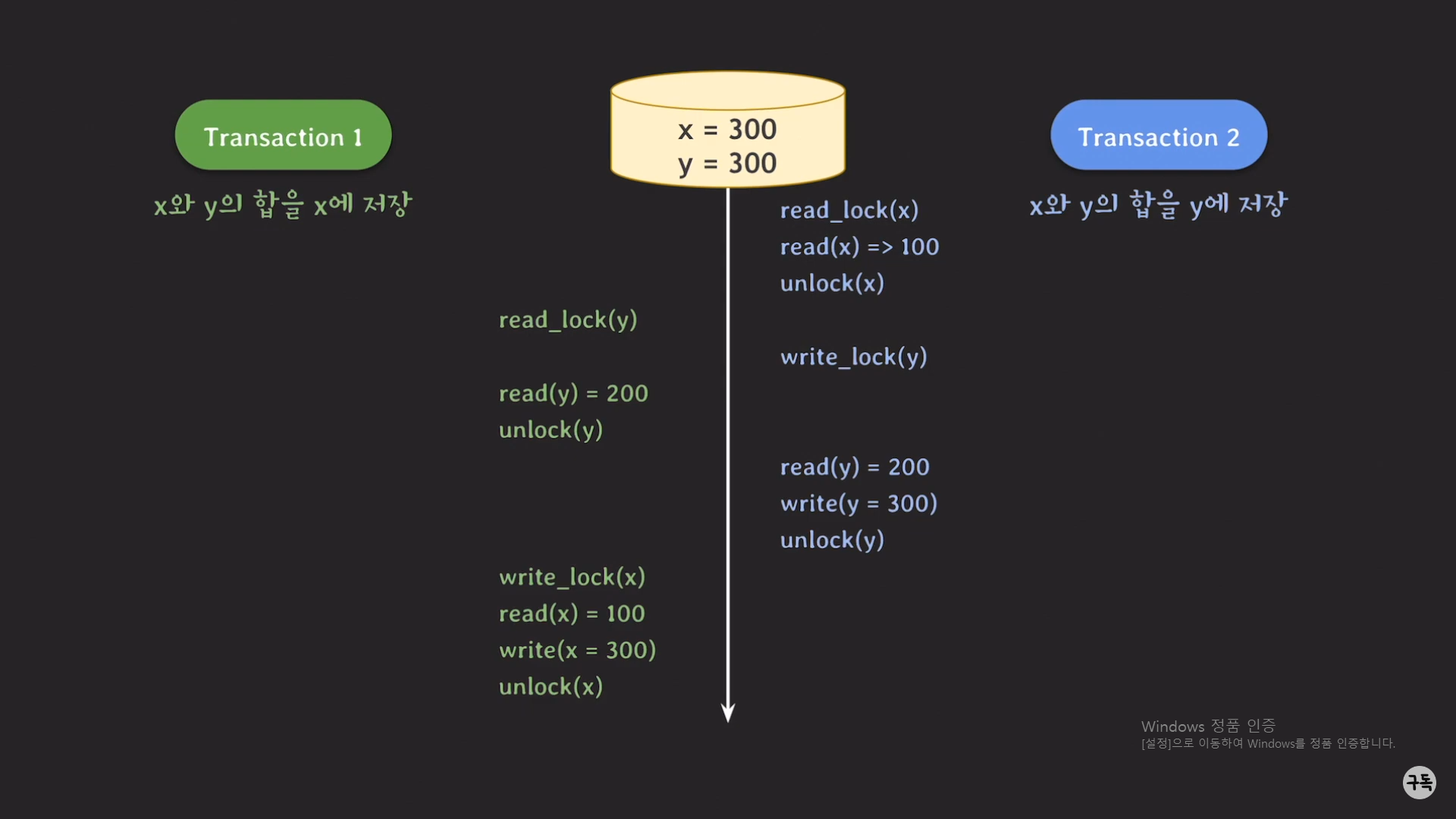

트랜잭션1,2를 동시에 실행시킨 최종 결과, (x,y)=(300,300)이 된다.
그런데 이 값은 트랜잭션1,2를 동시에 실행시키지 않고, serial하게 실행시켰을 때의 최종 결과값과 다르다.
고로, 위 Non-serializaed schdule은 lock을 이용하였음에도 concurrency control이 보장되지 않은, 단순한 Nonserializable
한 schedule이다.
아래에서 왜 이러한 이상한 현상이 발생을 했는지에 대해서 살펴보자.
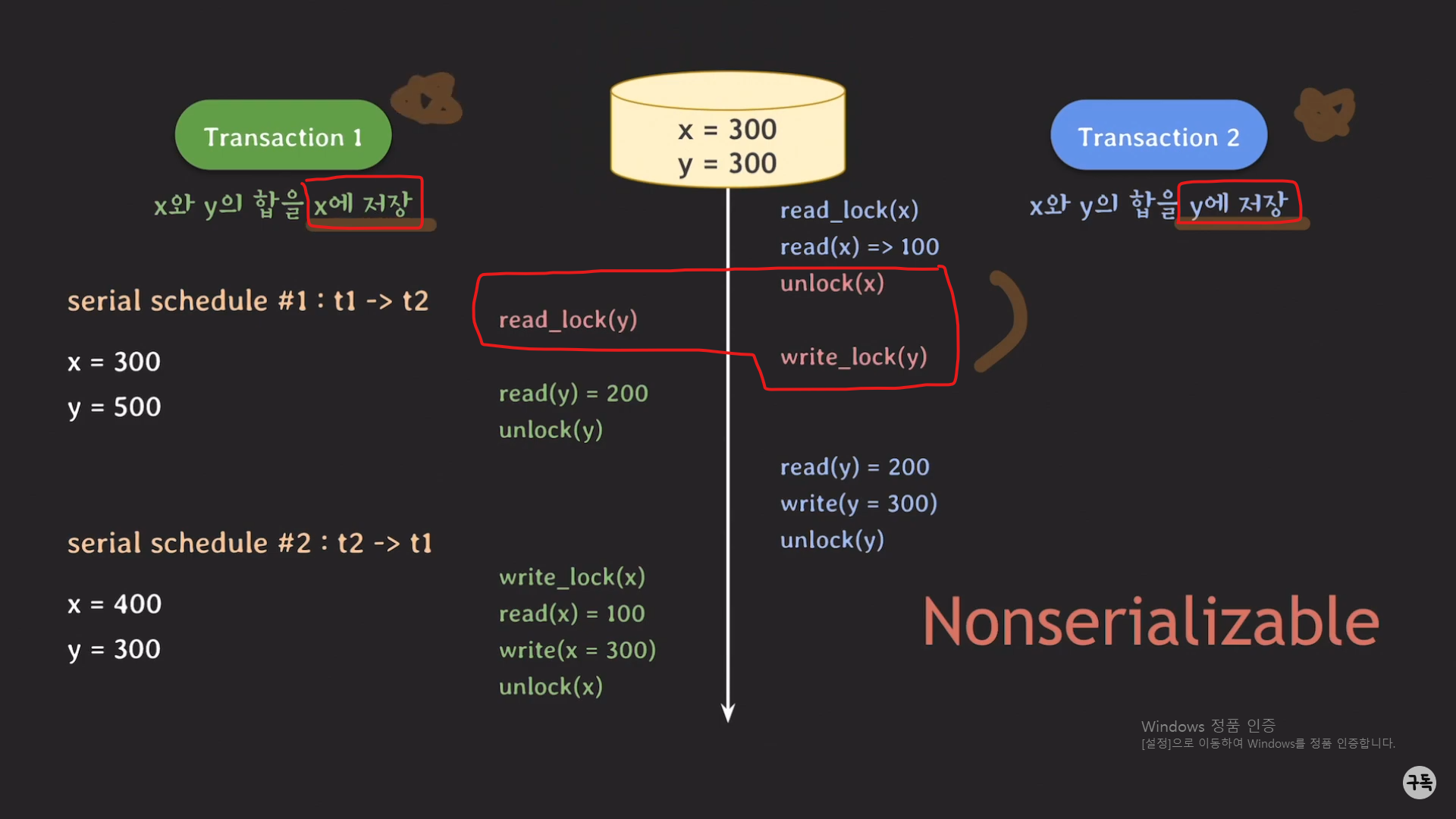
트랜잭션 1은 결과적으로 x를 업데이트하는 것이고, 트랜잭션 2는 결과적으로 y를 업데이트하는 것이다.
트랜잭션 1은 업데이트된 y값(트랜잭션 2의 실행 후의 y의 값)을 read했어야 serializable하게 실행돼, 최종 결과값이 serial
schedule #1,2중 어느하나와 같았을 것이다.( 트랜잭션 2는 먼저 실행이 되었기 때문에 트랜잭션 1이 업데이트한 x의 값을
받는 것을 염두에 두지 않아도 된다.)
정리
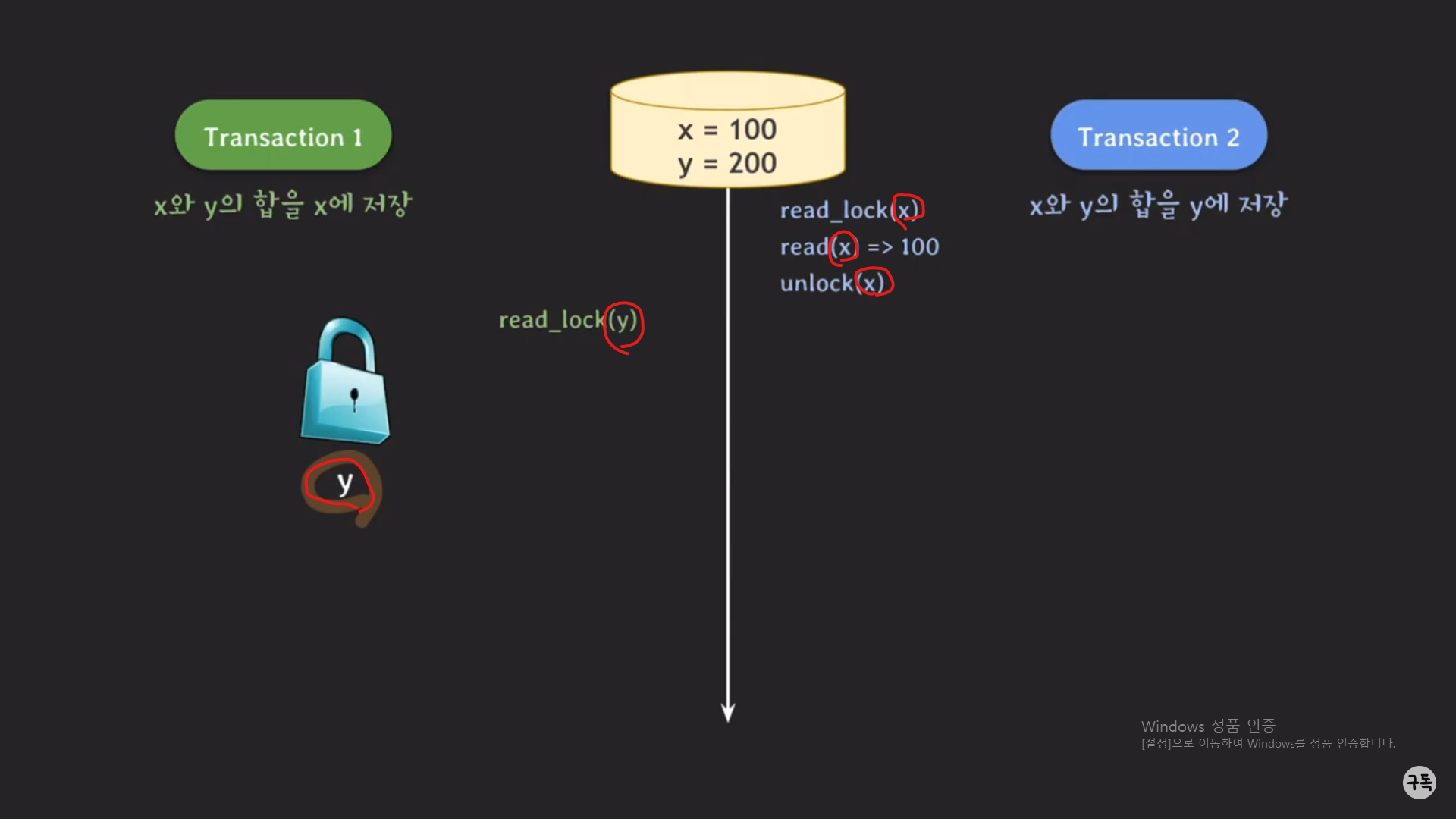
트랜잭션 2은 x의 값을 읽고 난 뒤,
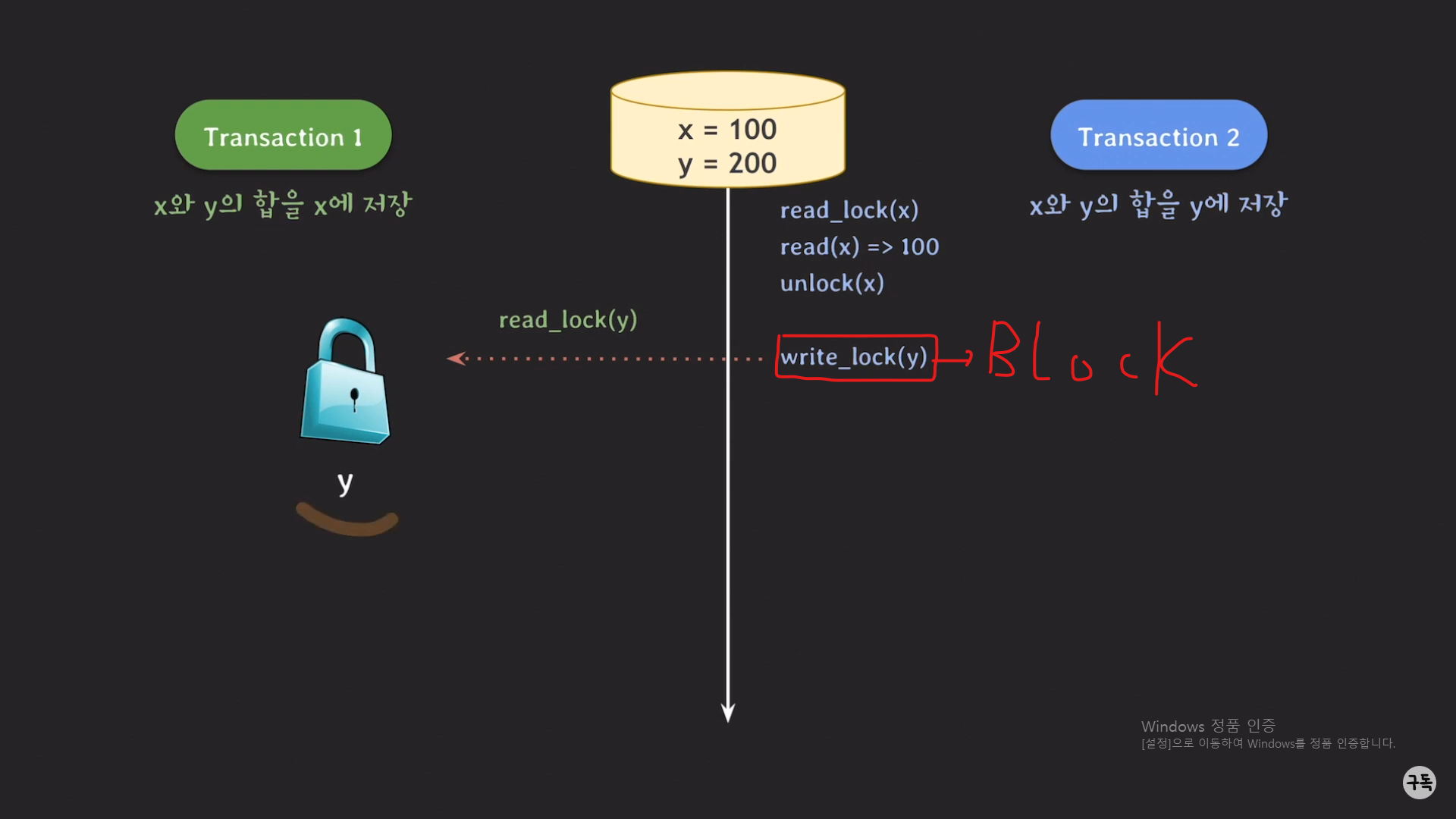
y에 대한 데이터를 읽고/쓰기위해서(y의 값을 업데이트하기 위해서) write_lock(y)을 취득을 하려고 하였는데,
트랜잭션1의 read_lock(y)로 인해 y에 대한 lock을 얻지 못하고,
block이 되는 바람에 트랜잭션 2는 y를 업데이트하지 못한채 계속 대기를 하였고,
트랜잭션 1은 업데이트되지 않은 y을 읽어서 유효하지 않은 y값을 사용하였기 때문에
이상한 현상이 일어난 것이다.
어떻게 하면 이 이상한 현상을 해결할 수가 있을까???
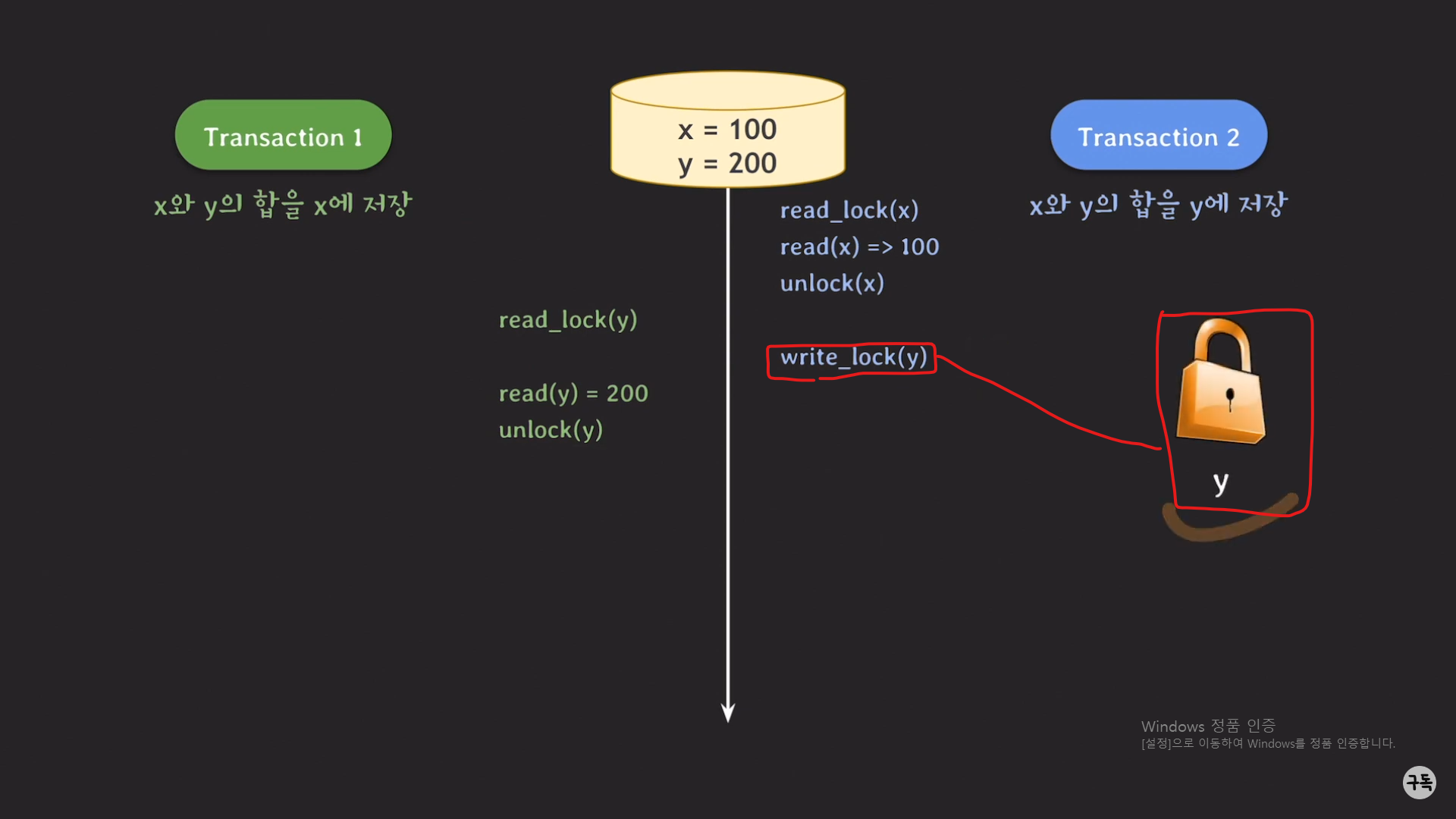
solution : 트랜잭션2의 unlock(x)와 write_lock(y)의 순서를 바꾸어 주면 된다.
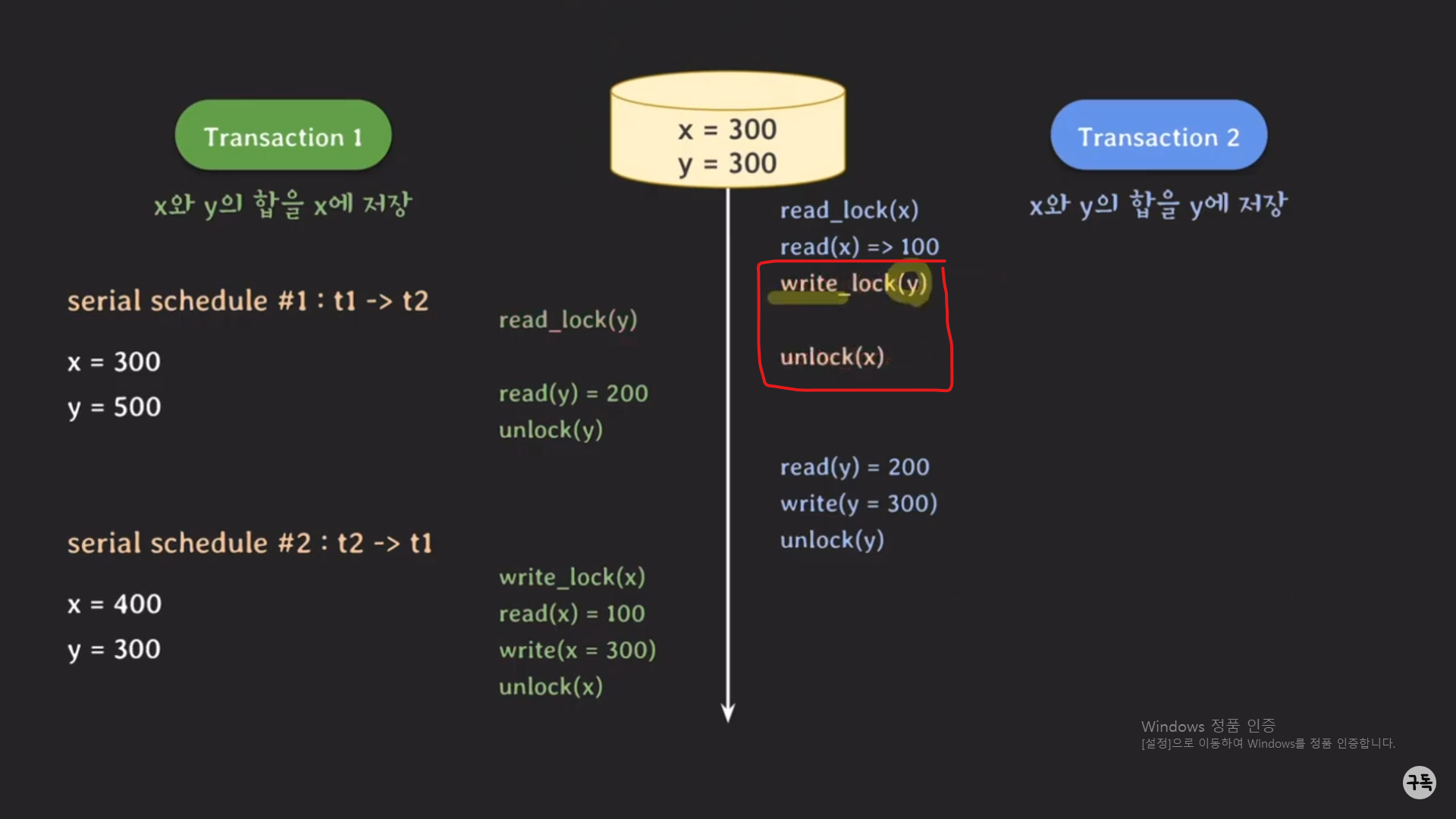
트랜잭션 1이 y에 대한 read_lock을 획득을 하기 이전에 트랜잭션 2에서 y에 대한 lock을 획득을 해 놓으면,
트랜잭션 1은 read_lock(y)에서 block된 상태로 계속 대기를 하기 때문에업데이트 되지 않은, 즉 유효하지 않은 y값을 읽어
들어서 유효하지 않은 계산을 못하게 될 것이다.
트랜잭션 1의 read_lock(y)가 block 처리가 되므로, schedule은 아래와 같이 변경이 될 것이다.
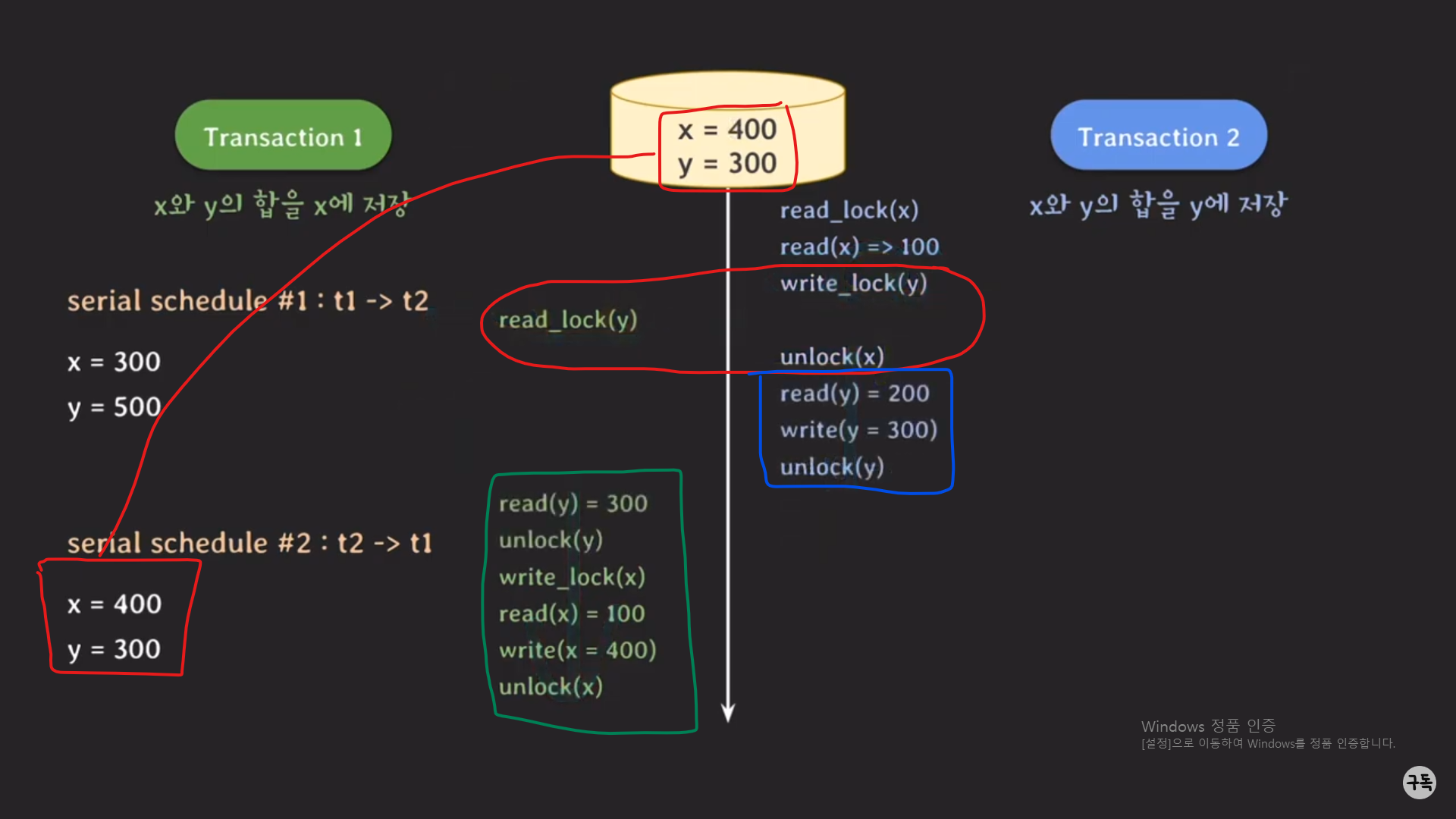
최종 결과값이 serial schedule의 최종 결과값과 같다.
만약 트랜잭션 1이 먼저 실행되었다면 그때에는 어떻게 해주면 될까??
트랜잭션 2가 업데이트되지 않은 x값을 읽기 전에,
트랜잭션 1에서 write_lock(x)를 통해
트랜잭션2에서 x에 대한 lock을 취득하려고 할 때, block을 걸음으로서
최종 결과값이 serial schedule의 최종결과 값과 동일하게 하면 된다.(아래 참조)
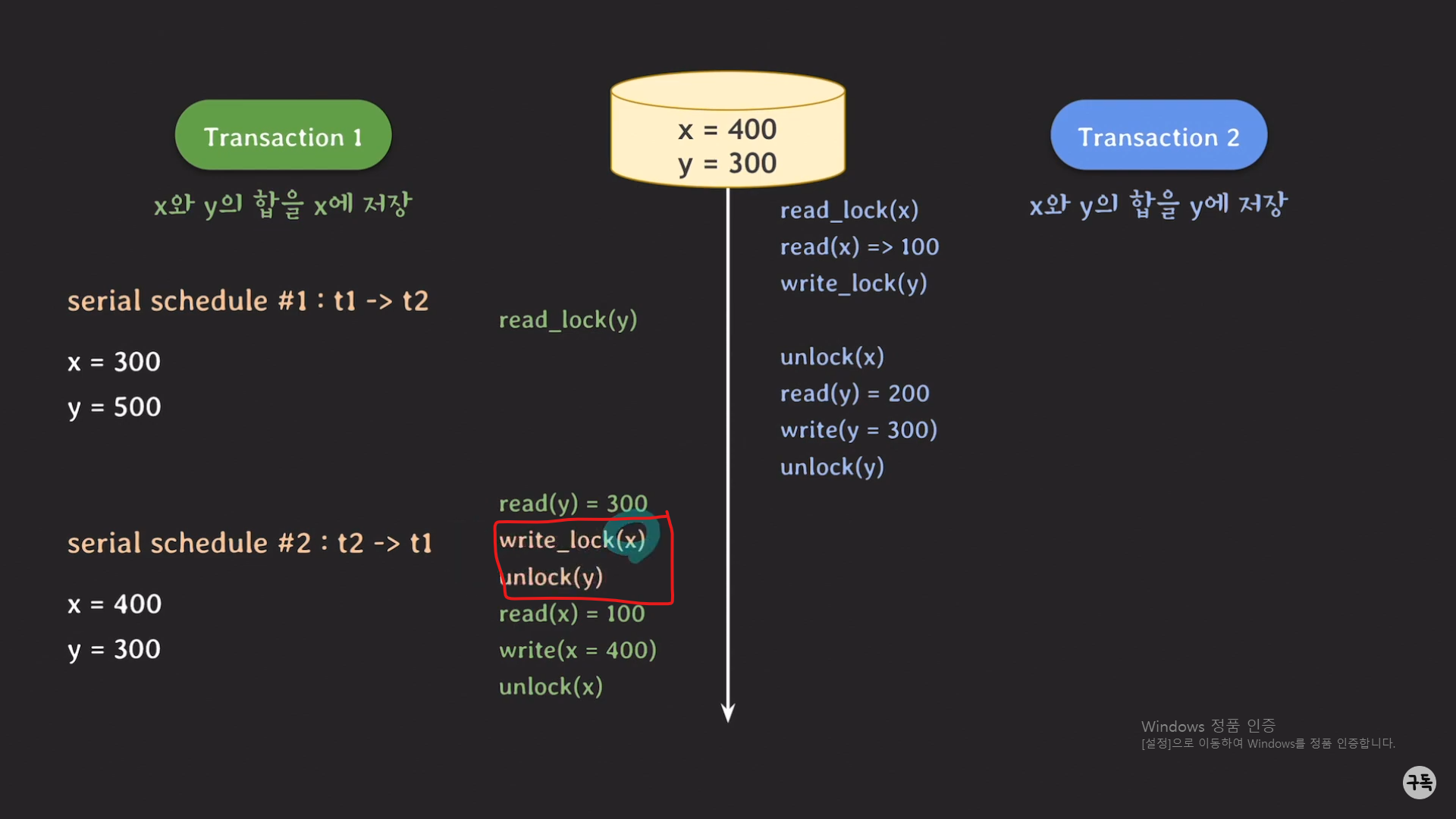
Point!!!!!!!!!!!!
LOCK을 사용했다고 해서, 이상한 현상이 일어나지 않는 것은 아니다!!!!!!!!!!!!!!!!!!!
2PL Protocol
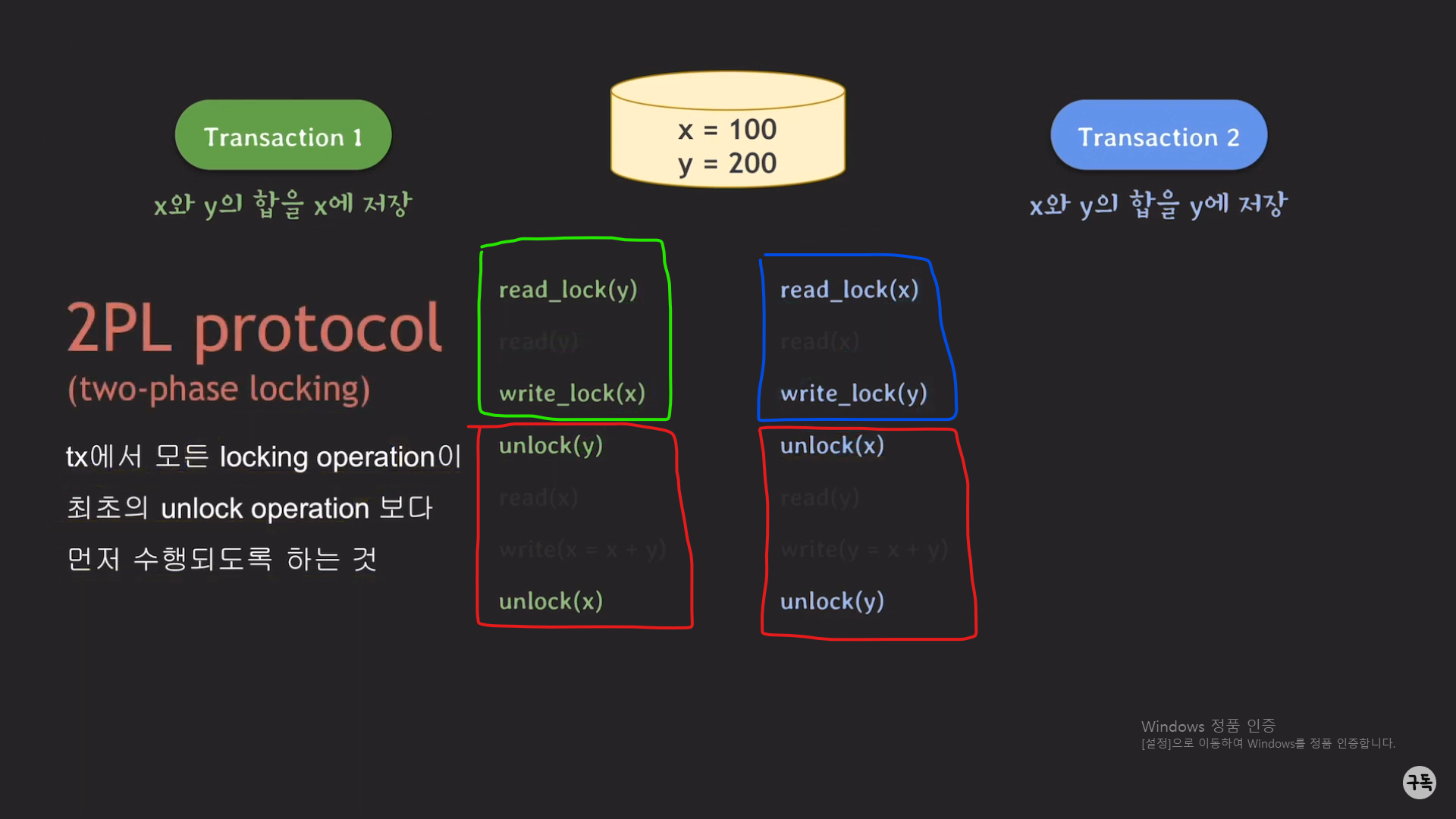
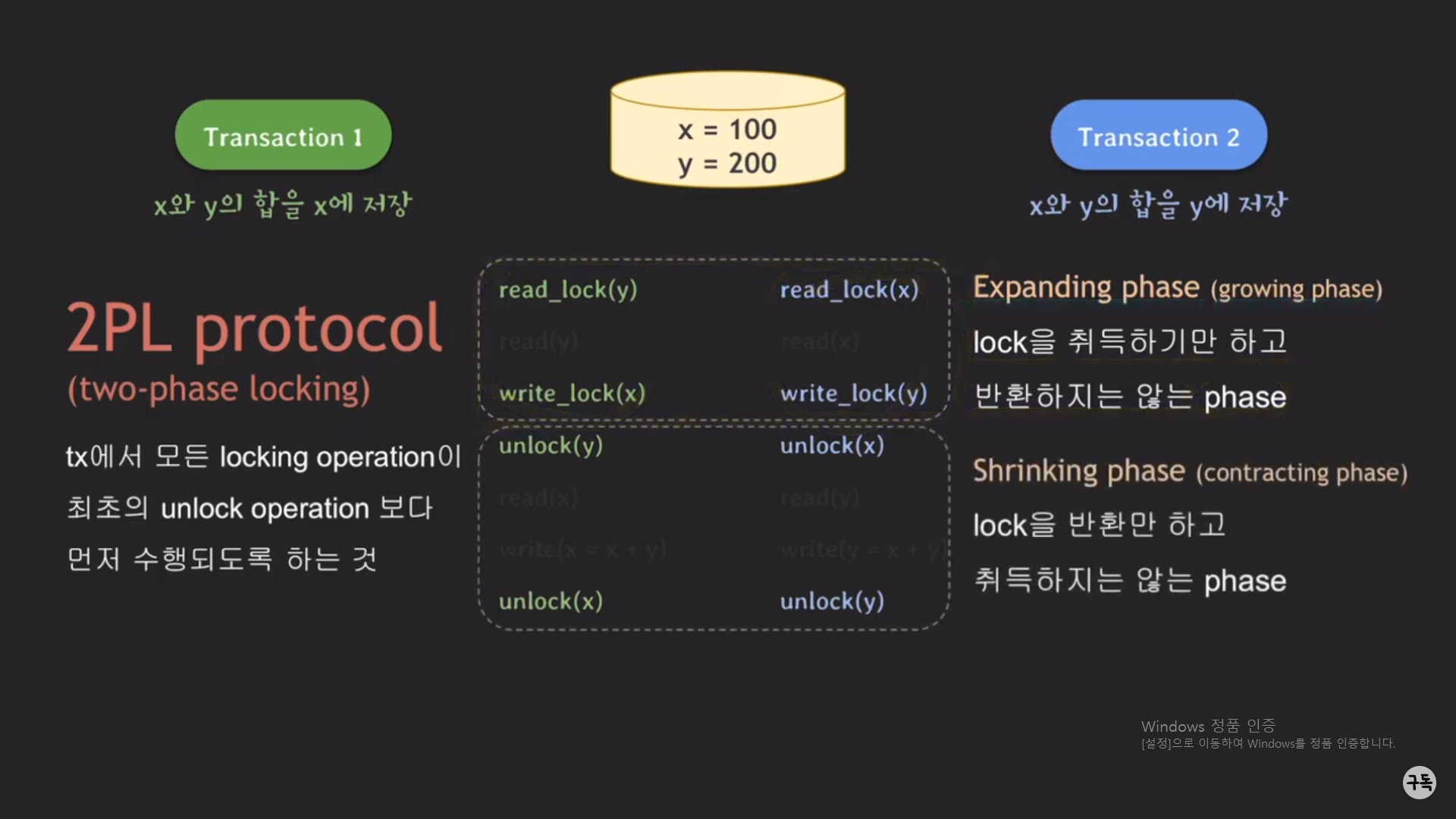
( phase : 단계 )
2PL Protocol은 Serialiability를 보장을 한다.
그러나 특정 상황에서는 문제가 생길 수가 있다. 아래에서 살펴 보자 고고씽~~!!!!!!
dead lock
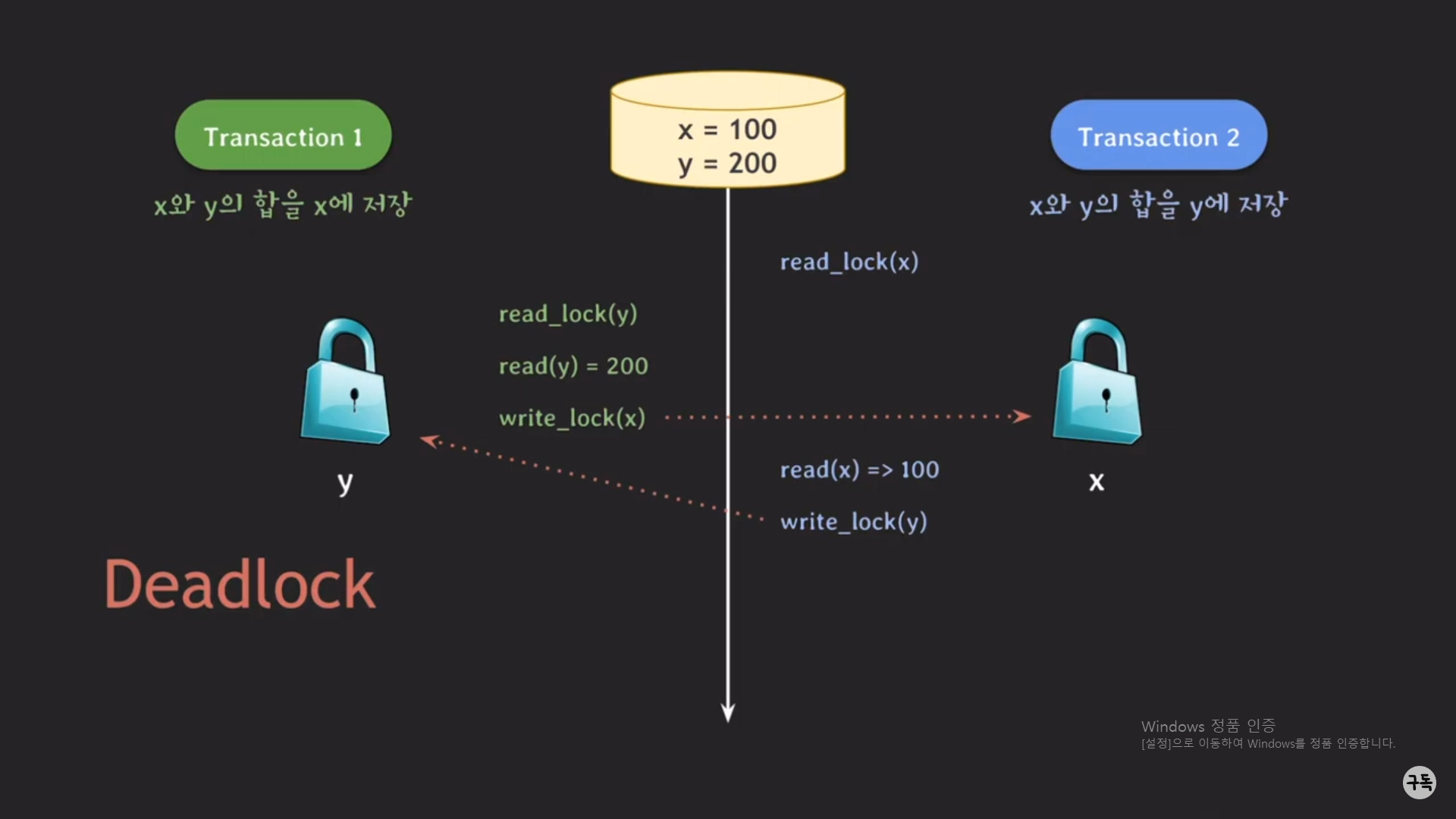
2PL Protocol에서 나타나는 dead lock은 운영체제에서 배우는 세마포어와 같은 방법으로 해결하면 된다.
dead lock, 세마포어는 운영체제의 영역이므로 여기서는 설명하지 않겠다.
정리
2PL protocol을 이용하여 Serializabilty를 보장받아서 concurrency control를 구현할 수가 있다.
2PL Protocol의 종류
2PL Protocol에는 3가지 종류의 protocol이 있는데, 예제를 통하여 그 종류들을 살펴보겠다.
먼저 예제를 소개하겠다.

위의 2PL Protocol로 구성된 schedule을 가지고 아래에서 2pl protocol의 종류에 대해서 설명을 하겠다.
1. conservative 2PL Protocol

conservative 2PL은 Dead Lock에 걸리지는 않는다.
그러나 모든 lock를 다 취하기는 어렵기 때문에 자칫하다가는 트랜잭션이 block이 돼서 시작을 못하는 경우가 발생을 한
다. 그래서 실용적이지 않기 때문에 잘 쓰이지는 않는다.
2. strict 2PL Protocol

3. strong strict 2PL Protocol

단점 또한 존재를 한다.
모든 unlock을 트랜잭션의 끝에서 실행하기 때문에, 즉 오랫동안 lock을 쥐고 있기 때문에 다른 트랜잭션의 block되는 시
간이 길어진다.
오늘날의 많은 RDBMS에서는 LOCK과 MVCC를 혼용해서 사용한다.
'CS 과목(CS科目) > 데이터 베이스(データベース)' 카테고리의 다른 글
| 20. MVCC - Part 2 (0) | 2022.12.16 |
|---|---|
| 19.MVCC - Part 1 (0) | 2022.12.12 |
| 17. transaction isolation level (1) | 2022.12.12 |
| 16. concurrency control - Part 2 (1) | 2022.12.10 |
| 15. concurrency control(Serial schedule, NonSerial schedule) - Part1 (1) | 2022.12.10 |



