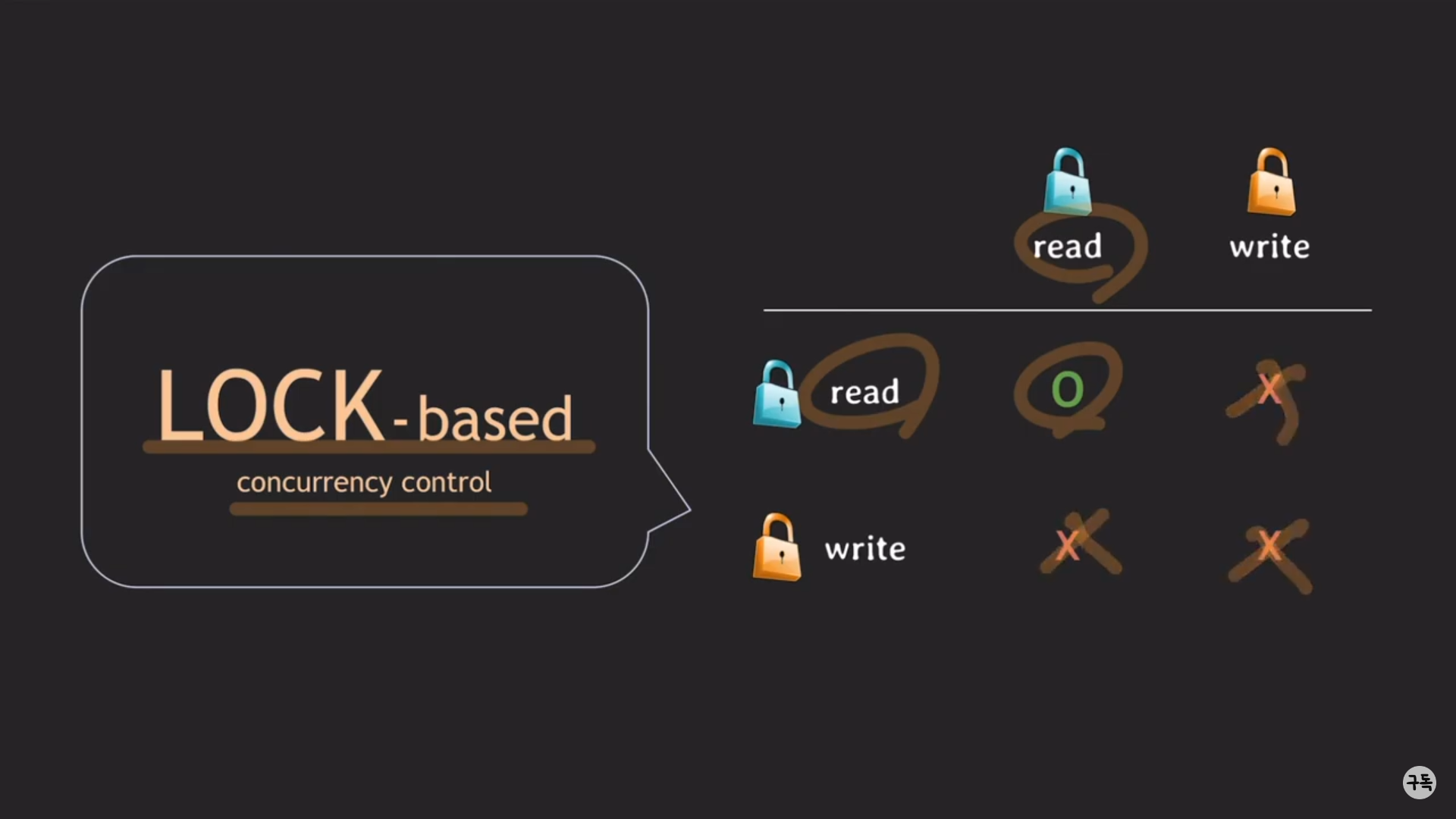
이전 시간에, Lock을 활영한 concurrency control에 대해서 살펴 보았다.
같은 데이테에 대해서 read-read인 경우는 허용을 하지만, 그 이외의 경우는 허용을 하지 않는다.
그래서, 트랜잭션의 Operantion에 대한 전체 처리량(throughput)이 좋지가 않았다.
개발자들은 이러한 문제를 해결하고자, write-write한 경우는 그렇다고 쳐도, read-write의 경우에는 어떻게 최적화를 시킬
수 없을까 라는 고민을 하게 되었고, 그렇게 해서 나온 아이디어가 MVCC(Multi Version Concurrency Control)이다.

write-write의 경우에 대해서는 어느 한쪽을 block을 시키지만, read-read는 물론, read-write의 경우에 같은 데이터에 대해
서는 block이 되지 않고 동시에 처리를 가능하게 하여 전체 처리량(throughput)을 향상시켰다.
(참고로, MVCC는 LOCK을 사용하지 않아도 구현이 가능하다. 그러나 오늘날의 대부분의 RDBMS는 LOCK을 사용하여 MVCC를 구현한다.)
MVCC가 어떻게 구현이 되는지 아래의 예제에서 살펴보자
(아래의 예제에서는 편의상 write_lock, read_lock을 굳이 명시적으로 기술하지는 않겠다. 그리고 Unlock도 명시하지 않을 거임)
참고로, write_lock, read_lock이라던지, unlock과 같은 것은 개발자가 하는 것이 아닌, RDBMS가 하는 영역이다.

트랜잭션2번이 먼저 실행되어 , write(x=50)이 실행이 되면 여태까지는 DB에 바로 X=50에 적용이 되었지만, MVCC에서는
그런 식으로 동작을 하지는 않고, 트랜잭션 2만 아는 어느 공간에 임시 저장하는 형태로 X=50을 저장을 한다.(약간
Snapshot isolation과 비슷한듯??)
(사실 MVCC는 RDBMS마다 구현하는 방법이 다르기에 예제에서 설명하는 내용이 모든 RDBMS에 적용되는 개념은 꼭 아
니라는 것을 염두해 두자.)
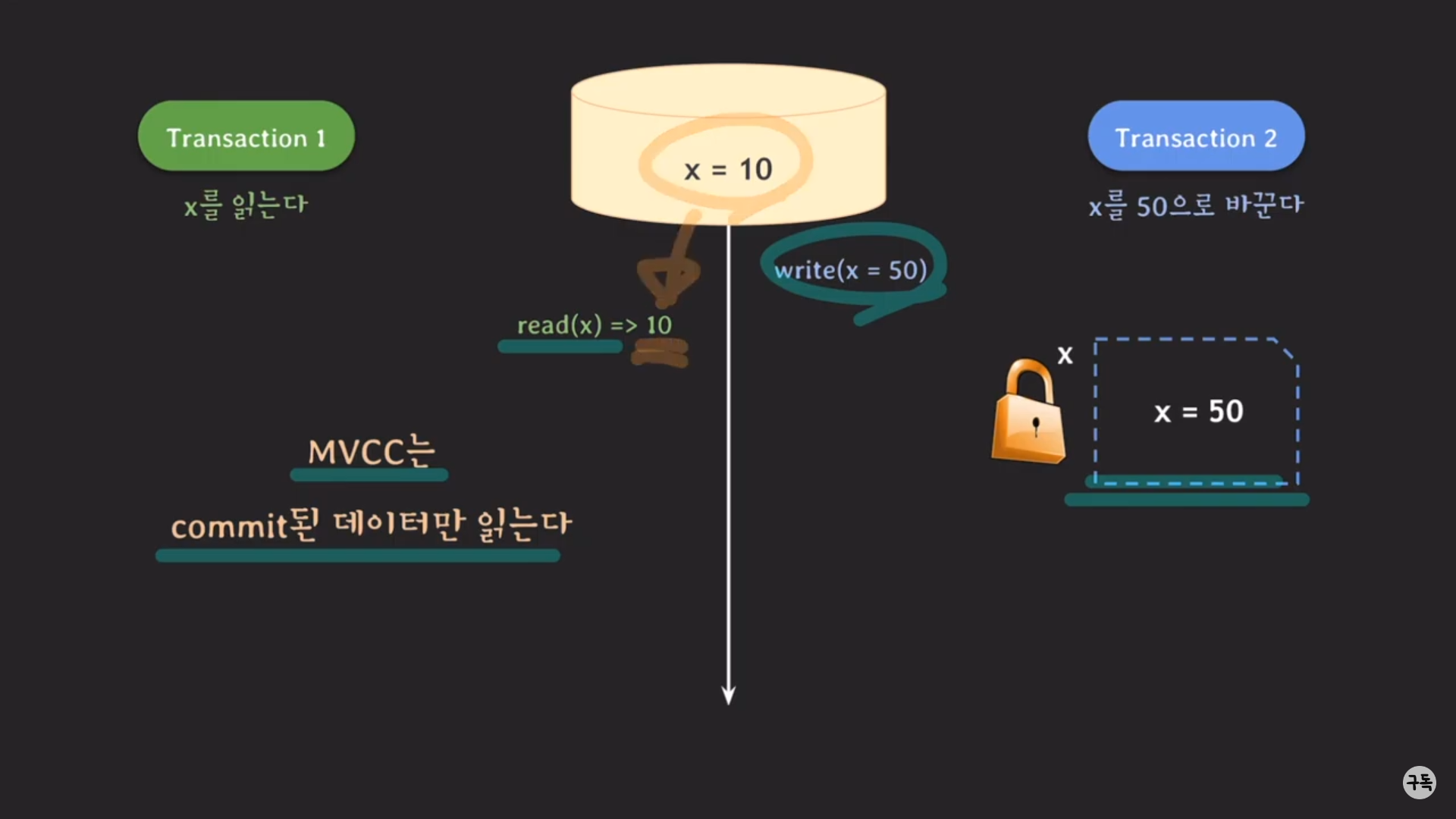
트랜잭션 2의 write( x = 50 )은 DB에 commit되지 않고, RDBMS내의 트랜잭션 2를 위한 공간에 임시저장이 돼 있다.
MVCC는 특정 시점을 기준으로 가장 최근에 commit된 데이터만을 읽는다.
이 시점에서 가장 최근에 commit된 데이터는 아무것도 없으므로, 트랜잭션 1의 read(x)는 DB의 10의 값을 읽어 들인다.
트랜잭션 2에서는 wirte(x=50)을 위해서 x에 대해서 lock을 이미 쥐고 있는 상태이다.
그런데 어떻게 해서 트랜잭션 1의 read(x)이 block처리가 되지 않고 실행이 되는 걸까??
트랜잭션 2의 wirte(x=50)의 결과는 위에서도 언급을 하였듯이 RDBMS의 내부 어딘가에 저장이 된다.
즉, DB에 =50이 저장이 되는 것이 아니다.
고로, 트랜잭션 1은 트랜잭션 2의 영향을 받지 않은 데이터를 그대로 읽어 올 수가 있기 때문에 read(x)에서 lock을 취득하
여, 데이터를 읽어 올 수가 있다.
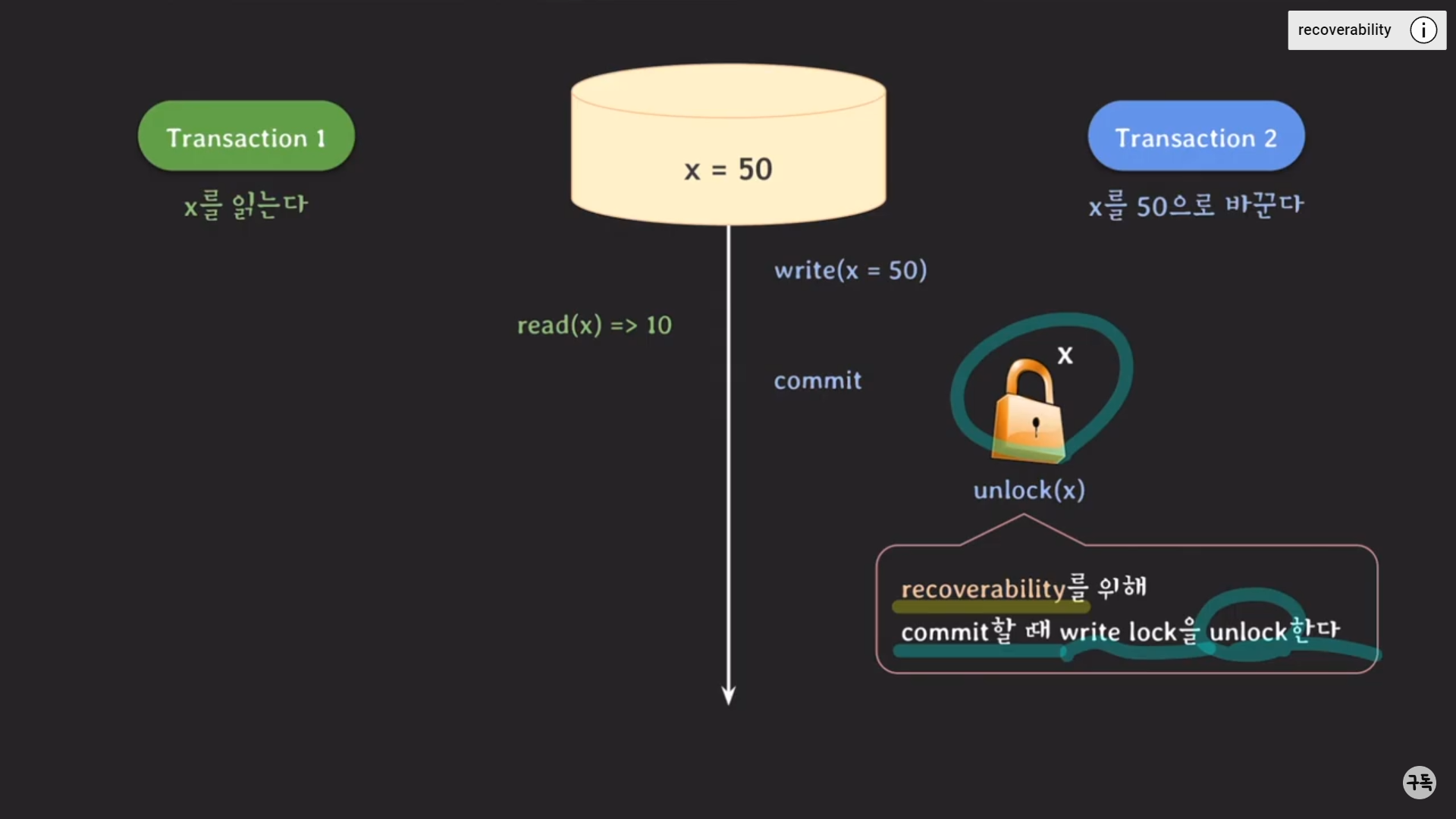
왜 write_lock의 경우, commit을 한 뒤에야 unlock을 해주는 걸까??
트랜잭션 2가 write_lock을 취득하고 write 작업을 끝낼 때(commit)까지 다른 트랜잭션이 같은 데이터에 대해 read/write 작
업을 못하게 하기 위함이다.

그렇다면, 트랜잭션 1의 2번재 read(x)는 어떤 값을 읽을까?
그건 트랜잭션 1이 어떤 isolation level에 있냐에 따라 다르다.
만약 read committed level로 설정이 돼 있다면, read하는 시간을 기준으로 가장 최근에 commit된 데이터를 읽으므로,
x=50이라는 데이터를 읽어 들인다.
사실, MVCC에서 특정 시간 기준이라는 것은 RDBMS마다 서로 다르다.
그래서 MySQL과 Postgre SQL에서의 시간 기준으로 설명을 하겠다.

트랜잭션 1이 repeatable read level로 설정이 되 있는 경우,
트랜잭션 1이 시작되는 시간 기준으로 가장 최근에 commit된 데이터를 읽어 들이므로, x=10을 읽어 들인다.

위 예제들에서 살펴 봤듯이 MVCC는 어느 시간을 기준으로 가장 최근에 commit된 데이터를 읽어 들인다.
(MySQL 세계관에서는 특정 시점 기준으로 가장 최근에 COMMIT된 데이터를 READ하는 것을 CONSISTENT READ라고
부르므로, MySQL 문서를 읽을 때, 이 용어를 보면 당화하지 말자.)
고로, RDBMS는 내부 어딘가에서 데이터의 변화(write) history를 저장 및 관리를 해야 한다.
그리고, read와 write는 서로를 block하지 않기에 트랜잭션의 동시 처리량이 늘어나서 퍼포먼스가 높아 진다.
이러한 이유로 오늘날의 대부분의 RDBMS에서는 MVCC를 사용하여 concurrency control을 구현을 한다.


이 serializable에 대해서는 이후에 자세히 설명을 하겠다.

Postgre SQL에서의 MVCC의 동작 방식
위 예제가 Postgre SQL의 MVCC가 어떻게 동작하는지를 살펴 보자. 참고로, 여러 트랜잭션이 동시에 실행됐을 때, 최종 결과가 어떻게 되는지 미리 계산을 할 때 팁이 있는데, 이는 각 트랜잭션을 단독으로 실행했을 때의 값이라고 생각하면 된다.
왜냐하면, 트랜잭션의 isolation이란 여러 트랜잭션이 동시에 실행이 됨에도 불구하고, 단독으로 실행된 것과 같은 결과를 내는 것이기 때문이다.


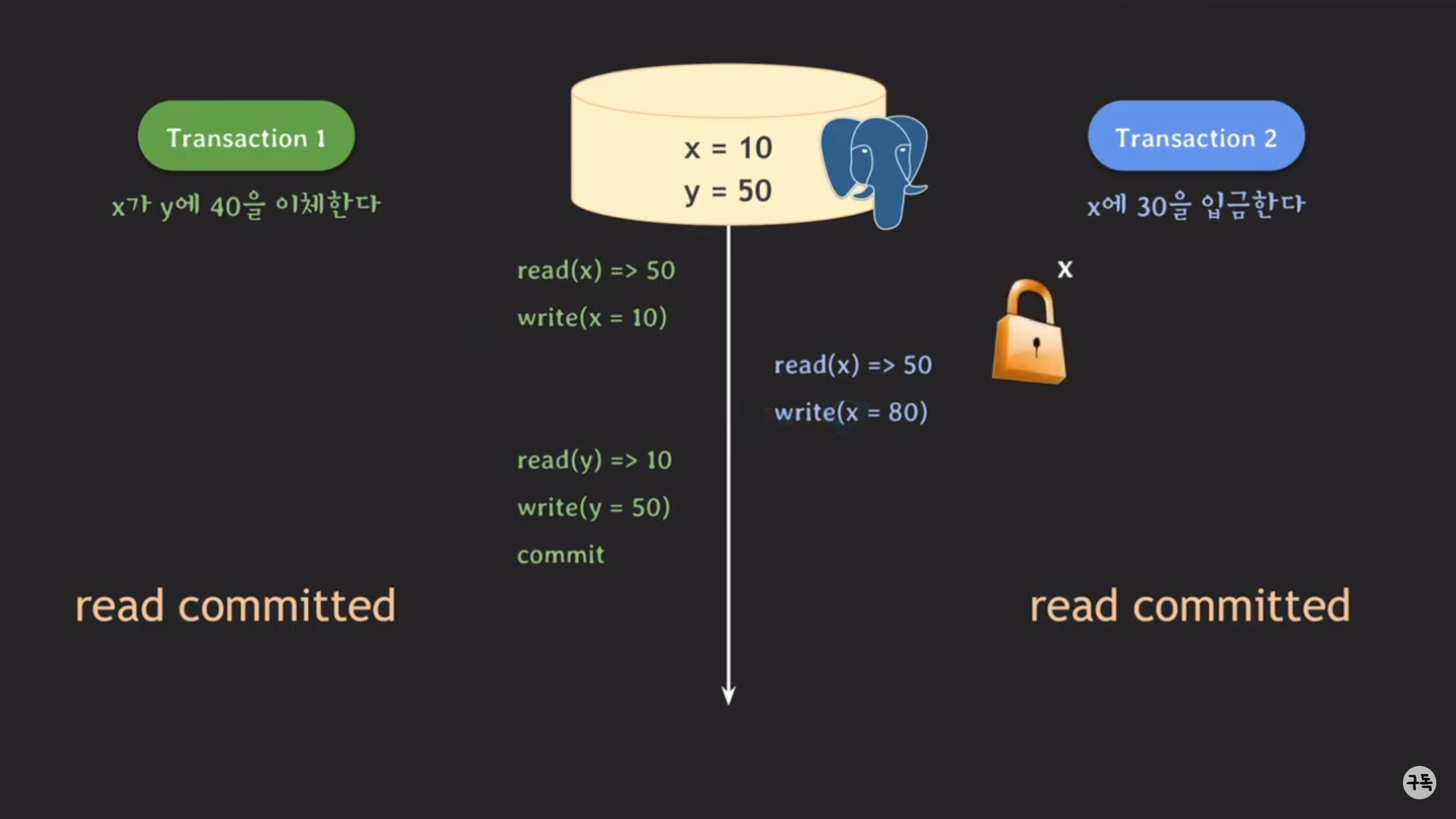
트랜잭션1,2의 isolation level은 모두 read committed level이다.

트랜잭션 2의 write(x=80)은 x에 대한 lock을 취득하지 못하므로, block처리돼서 대기 상태가 된다.


commit되는 순간 트랜잭션1의 최종 결과값이 DB에 영구적으로 저장이 된다.
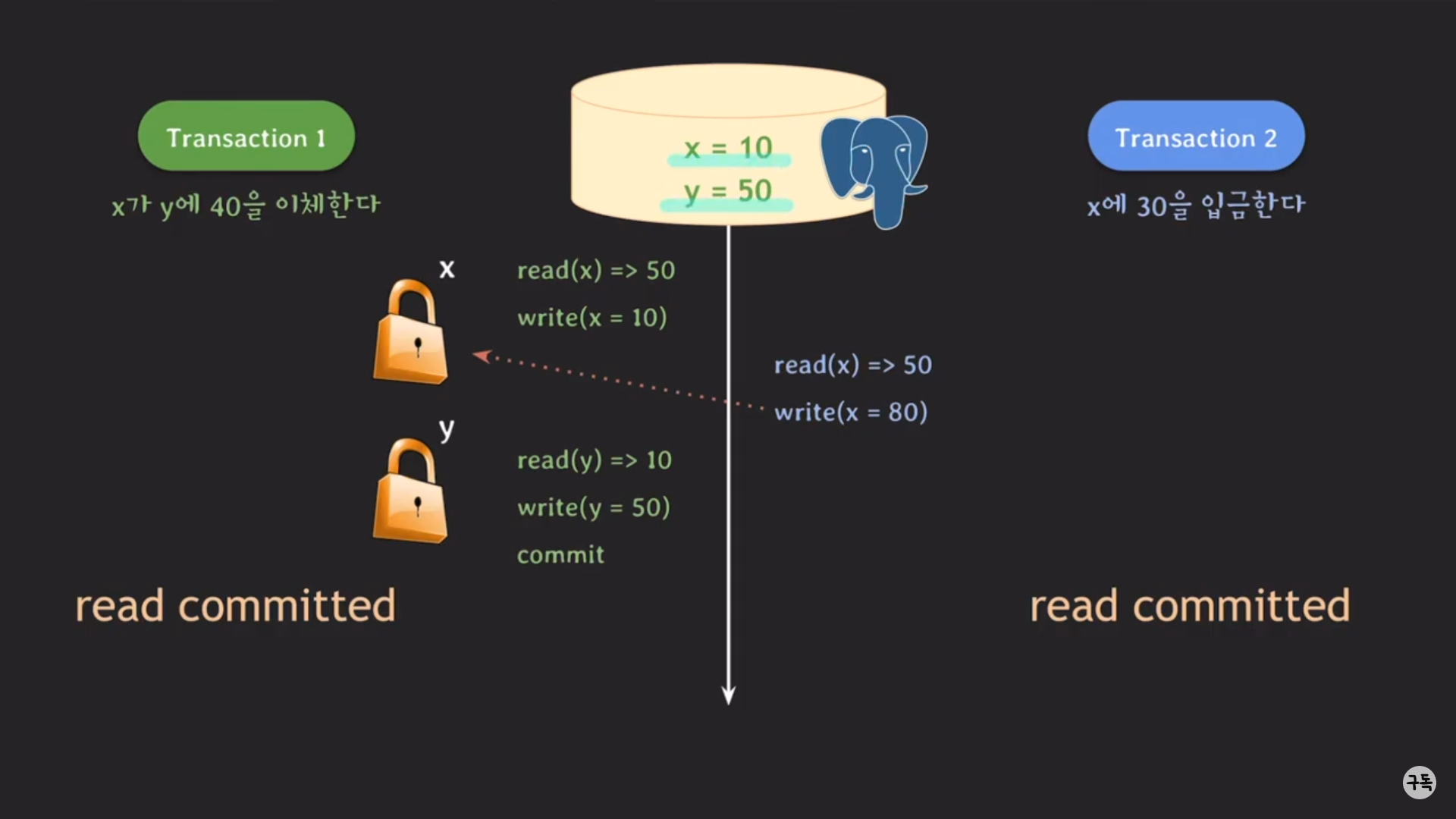
X에 대한 LOCK이 반환이 됐기 때문에, 트랜잭션 2는 이제야 write(x=80)의 수행이 가능해진다.
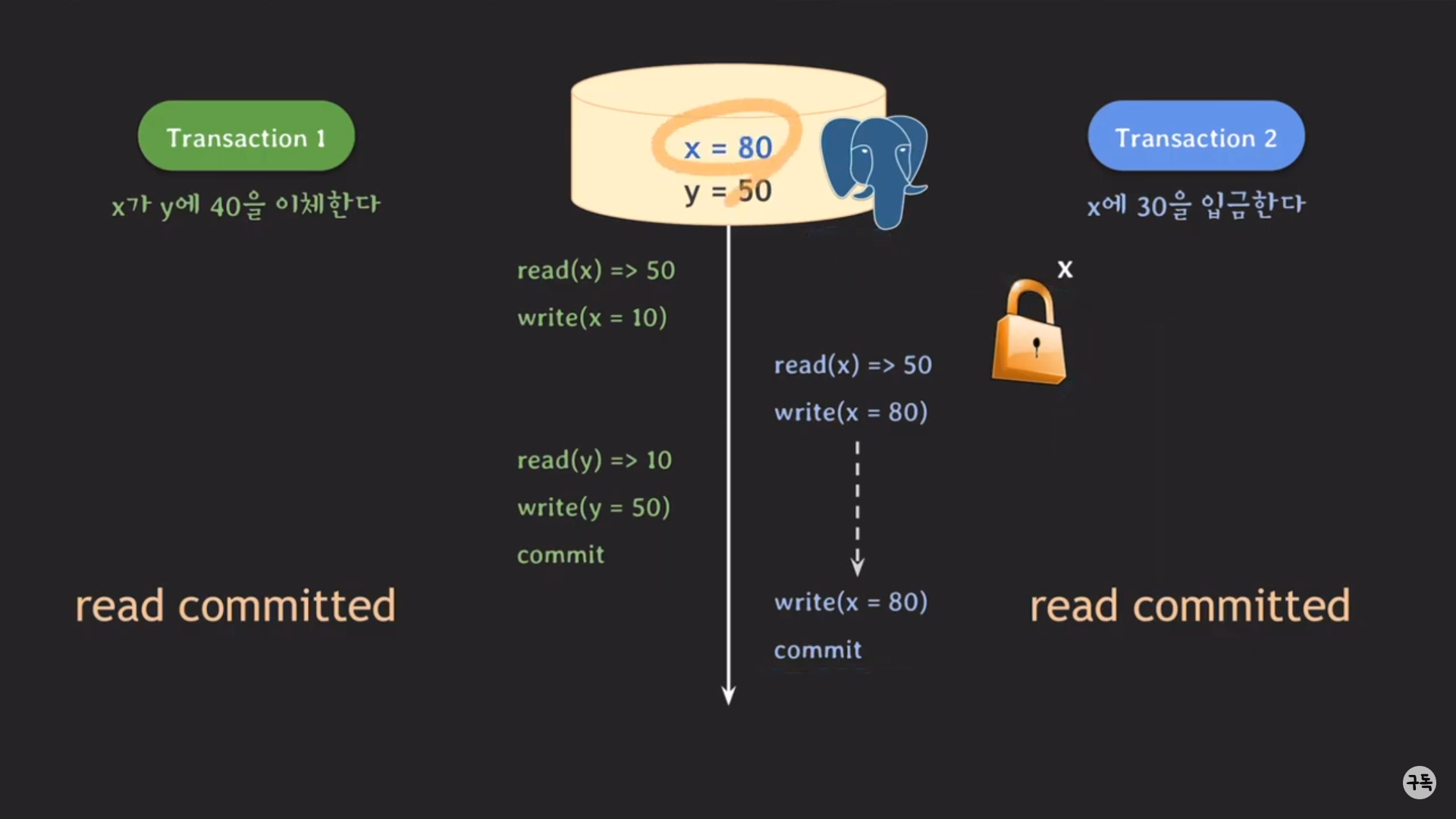
최종 결과값을 상펴 보자.
x=80, y=50으로 우리가 원하던 최종 결과값이 아니다. 즉, Lost Update 문제가 발생.
Solution : 트랜잭션 2으 isolatino level을 repeatable read로 설정을 해보자
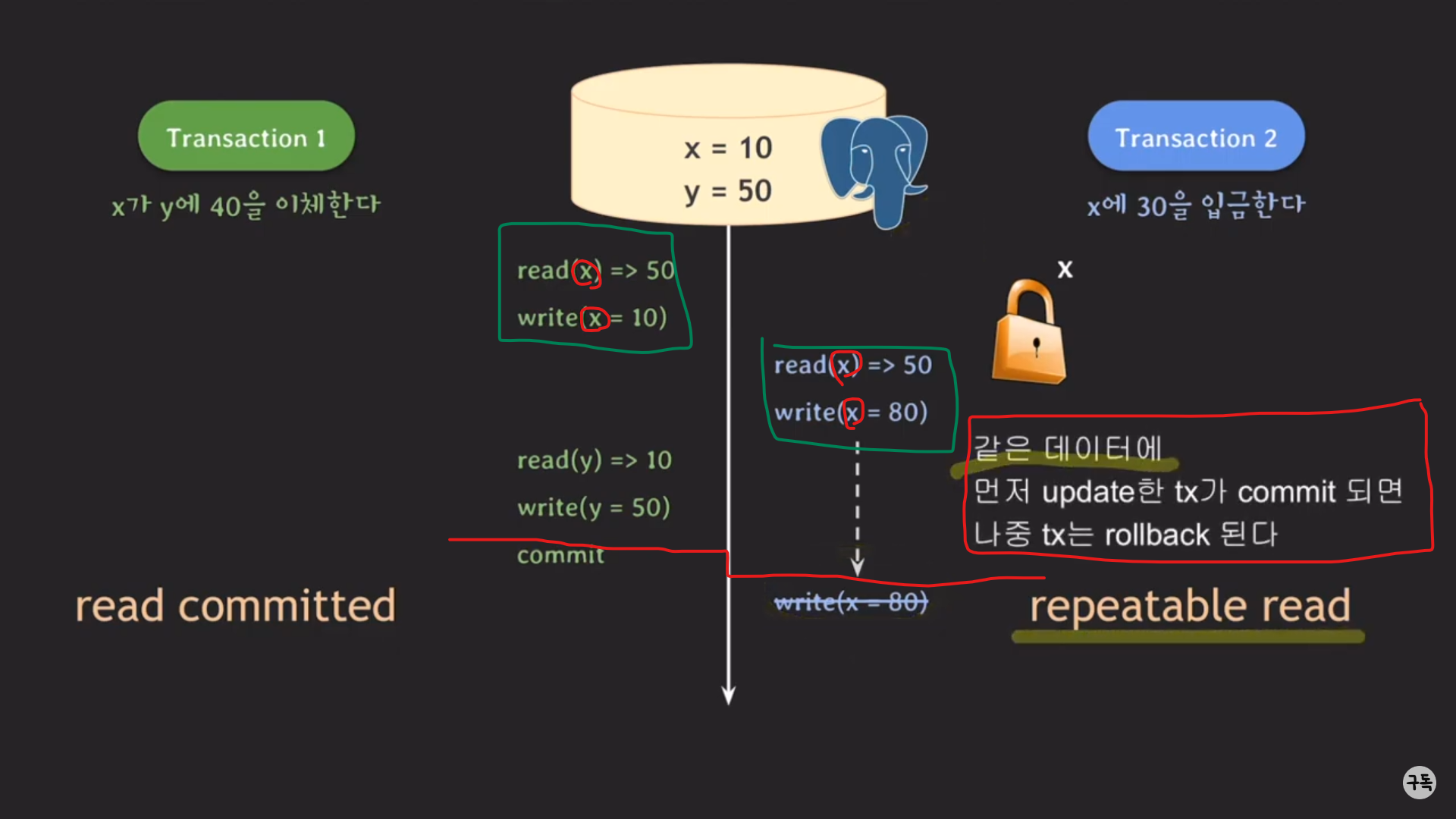
빨간색 선까지는 이전의 실행 흐름과 같다.
그러나 문제는 write(x = 80 )에서 달라진다.
Postgre SQL에서는 위에 적힌 규칙으로 인해 write(x=80)의 작업이 abort돼 roll back이 일어난다.
같은 데이터 : 여기서는 x
먼저 update한 tx : 여기서는 트랜잭션 1( 정확히는 트랜잭션 1의 read(x)와 write(x) )
commit : 같은 데이터 x에 대해 트랜잭션 1이 먼저 commit되었다.
-> 고로, 트랜잭션 2는 abort돼 roll back이 일어 난다.
(참고로, 이러한 repeatable read의 특징은 Postgre SQL에 존재하지, MySQL에서는 존재하지 않는 특징이다.
MySQL에서는 roll back이 일어나지 않고 정상적으로 나머지 operation들을 실행해 나간다.)

트랜잭션 1은 commit되었고, 트랜잭션 2는 트랜잭션이 시작되기 이전의 상태로 roll back되었으므로,
트랜잭션 1은 성공을 한 것이고, 트랜잭션 2는 아예 실행을 하지 않은 것과 같은 상태이므로 정상적인 처리가 되었다고 볼
수 있다.
그럼 이제 이 다음에 트랜잭션 2를 실행을 하면 트랜잭션 2는 정상적인 실행을 할 것이다.
위와 같은 특징을 first-updater win이라고 부른다.
그럼, 트랜잭션 2를 repeatable read level로 바꿔주기만 하면 아무런 문제가 일어 나지 않을까???
트랜잭션 1의 isolation level은 read committed인체로 괜찮을까??
아니다. 아래에서 살펴보자.

트랜잭션 2가 먼저 실행됐을 때에도 lost update 현상이 발생이 되었다.

트랜잭션 1의 isolation level을 reapeatable read로 바꿔 줬을 때, 정상적인 최종 결과 값이 나온다.
즉, Postgre SQL에서 Lost Update문제가 발생을 하였을 때에는, 하나의 트랜잭션의 isolation level뿐 아니라 연관이 있는
다른 트랜잭션의 isolation level도 챙겨 줘야 한다.

MySQL에서는 repeatable read이여도 roll back이 일어나지 않고, operation들이 위와 같이 그대로 실행이 된다.
그 결과 lost update가 발생을 한다.
그러면 MySQL에서는 어떻게 Lost Update 문제를 해결할까??
그건 다음 시간에........
'CS 과목(CS科目) > 데이터 베이스(データベース)' 카테고리의 다른 글
| 21.DB 테이블 설계를 잘못하면 생길 수 있는 문제 (0) | 2022.12.16 |
|---|---|
| 20. MVCC - Part 2 (0) | 2022.12.16 |
| 18. LOCK을 활용한 concurrency control (1) | 2022.12.12 |
| 17. transaction isolation level (1) | 2022.12.12 |
| 16. concurrency control - Part 2 (0) | 2022.12.10 |



